
3万字加50张图,带你深度解析 Netty 架构与原理(上)
接下来我们会学习一个 Netty 系列教程,Netty 系列由「架构与原理」,「源码」,「架构」三部分组成,今天我们先来看看第一部分:Netty 架构与原理初探,大纲如下:
前言
1. Netty 基础
1.4.1. 缓冲区(Buffer)
1.4.2. 通道(Channel)
1.4.3. 选择器(Selector)
1.1. Netty 是什么
1.2. Netty 的应用场景
1.3. Java 中的网络 IO 模型
1.4. Java NIO API 简单回顾
1.5. 零拷贝技术
2. Netty 的架构与原理
2.2.1. 单 Reactor 单线程模式
2.2.2. 单 Reactor 多线程模式
2.2.3. 主从 Reactor 多线程模式
2.1. 为什么要制造 Netty
2.2. 几种 Reactor 线程模式
2.3. Netty 的模样
2.4. 基于 Netty 的 TCP Server/Client 案例
2.5. Netty 的 Handler 组件
2.6. Netty 的 Pipeline 组件
2.7. Netty 的 EventLoopGroup 组件
2.8. Netty 的 TaskQueue
2.9. Netty 的 Future 和 Promise
3. 结束语
前言
读者在阅读本文前最好有 Java 的 IO 编程经验(知道 Java 的各种 IO 流),以及 Java 网络编程经验(用 ServerSocket 和 Socket 写过 demo),并对 Java NIO 有基本的认识(至少知道 Channel、Buffer、Selector 中的核心属性和方法,以及三者如何配合使用的),以及 JUC 编程经验(至少知道其中的 Future 异步处理机制),没有也没关系,文中多数会介绍,不影响整体的理解。
文中对于 Reactor 的讲解使用了几张来自网络上的深灰色背景的示意图,但未找到原始出处,文中已标注“图片来源于网络”。
Netty 的设计复杂,接口和类体系庞大,因此我会从不同的层次对有些 Netty 中的重要组件反复描述,以帮助读者理解。
1. Netty 基础
基础好的同学,如果已经掌握了 Java NIO 并对 IO 多路复用的概念有一定的认知,可以跳过本章。
1.1. Netty 是什么
1)Netty 是 JBoss 开源项目,是异步的、基于事件驱动的网络应用框架,它以高性能、高并发著称。所谓基于事件驱动,说得简单点就是 Netty 会根据客户端事件(连接、读、写等)做出响应,关于这点,随着文章的论述的展开,读者自然会明白。
2)Netty 主要用于开发基于 TCP 协议的网络 IO 程序(TCP/IP 是网络通信的基石,当然也是 Netty 的基石,Netty 并没有去改变这些底层的网络基础设施,而是在这之上提供更高层的网络基础设施),例如高性能服务器段/客户端、P2P 程序等。
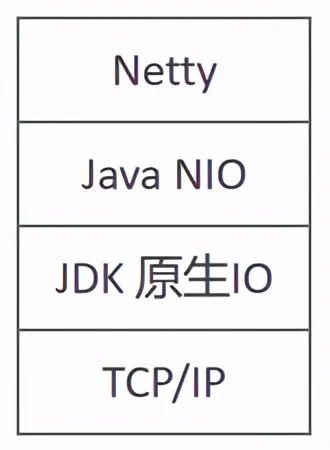
3)Netty 是基于 Java NIO 构建出来的,Java NIO 又是基于 Linux 提供的高性能 IO 接口/系统调用构建出来的。关于 Netty 在网络中的地位,下图可以很好地表达出来:
1.2. Netty 的应用场景
在互联网领域,Netty 作为异步高并发的网络组件,常常用于构建高性能 RPC 框架,以提升分布式服务群之间调用或者数据传输的并发度和速度。例如 Dubbo 的网络层就可以(但并非一定)使用 Netty。
一些大数据基础设施,比如 Hadoop,在处理海量数据的时候,数据在多个计算节点之中传输,为了提高传输性能,也采用 Netty 构建性能更高的网络 IO 层。
在游戏行业,Netty 被用于构建高性能的游戏交互服务器,Netty 提供了 TCP/UDP、HTTP 协议栈,方便开发者基于 Netty 进行私有协议的开发。
……
Netty 作为成熟的高性能异步通信框架,无论是应用在互联网分布式应用开发中,还是在大数据基础设施构建中,亦或是用于实现应用层基于公私协议的服务器等等,都有出色的表现,是一个极好的轮子。
1.3. Java 中的网络 IO 模型
Java 中的网络 IO 模型有三种:BIO、NIO、AIO。
1)BIO:同步的、阻塞式 IO。在这种模型中,服务器上一个线程处理一次连接,即客户端每发起一个请求,服务端都要开启一个线程专门处理该请求。这种模型对线程量的耗费极大,且线程利用率低,难以承受请求的高并发。BIO 虽然可以使用线程池+等待队列进行优化,避免使用过多的线程,但是依然无法解决线程利用率低的问题。
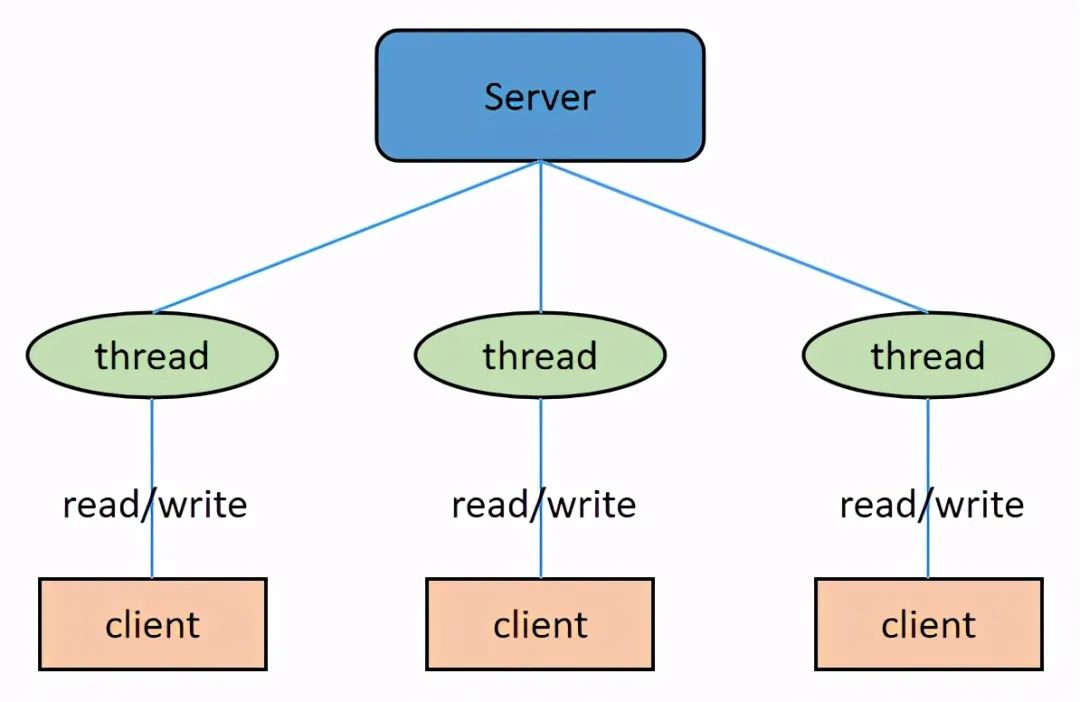
使用 BIO 构建 C/S 系统的 Java 编程组件是 ServerSocket 和 Socket。服务端示例代码为:
public static void main(String[] args) throws IOException {
ExecutorService threadPool = Executors.newCachedThreadPool();
ServerSocket serverSocket = new ServerSocket(8080);
while (true) {
Socket socket = serverSocket.accept();
threadPool.execute(() -> {
handler(socket);
});
}
}
/**
* 处理客户端请求
*/
private static void handler(Socket socket) throws IOException {
byte[] bytes = new byte[1024];
InputStream inputStream = socket.getInputStream();
socket.close();
while (true) {
int read = inputStream.read(bytes);
if (read != -1) {
System.out.println("msg from client: " + new String(bytes, 0, read));
} else {
break;
}
}
}
2)NIO:同步的、非阻塞式 IO。在这种模型中,服务器上一个线程处理多个连接,即多个客户端请求都会被注册到多路复用器(后文要讲的 Selector)上,多路复用器会轮训这些连接,轮训到连接上有 IO 活动就进行处理。NIO 降低了线程的需求量,提高了线程的利用率。Netty 就是基于 NIO 的(这里有一个问题:前文大力宣扬 Netty 是一个异步高性能网络应用框架,为何这里又说 Netty 是基于同步的 NIO 的?请读者跟着文章的描述找寻答案)。
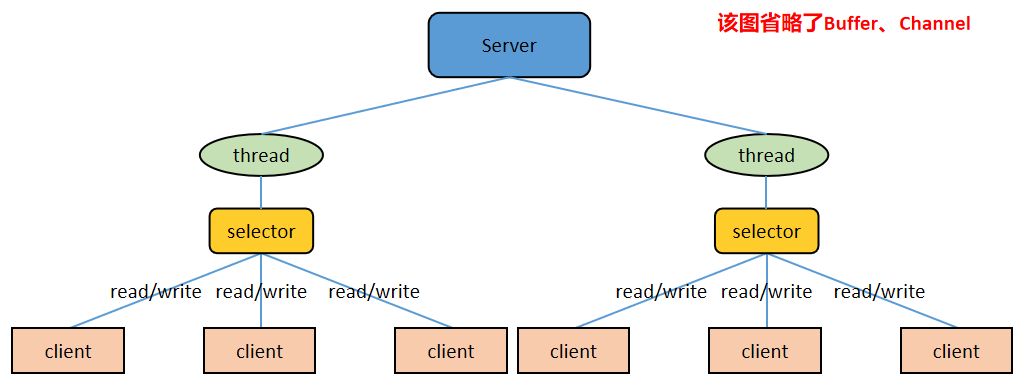
NIO 是面向缓冲区编程的,从缓冲区读取数据的时候游标在缓冲区中是可以前后移动的,这就增加了数据处理的灵活性。这和面向流的 BIO 只能顺序读取流中数据有很大的不同。
Java NIO 的非阻塞模式,使得一个线程从某个通道读取数据的时候,若当前有可用数据,则该线程进行处理,若当前无可用数据,则该线程不会保持阻塞等待状态,而是可以去处理其他工作(比如处理其他通道的读写);同样,一个线程向某个通道写入数据的时候,一旦开始写入,该线程无需等待写完即可去处理其他工作(比如处理其他通道的读写)。这种特性使得一个线程能够处理多个客户端请求,而不是像 BIO 那样,一个线程只能处理一个请求。
使用 NIO 构建 C/S 系统的 Java 编程组件是 Channel、Buffer、Selector。服务端示例代码为:
public static void main(String[] args) throws IOException {
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
Selector selector = Selector.open();
// 绑定端口
serverSocketChannel.socket().bind(new InetSocketAddress(8080));
// 设置 serverSocketChannel 为非阻塞模式
serverSocketChannel.configureBlocking(false);
// 注册 serverSocketChannel 到 selector,关注 OP_ACCEPT 事件
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
// 没有事件发生
if (selector.select(1000) == 0) {
continue;
}
// 有事件发生,找到发生事件的 Channel 对应的 SelectionKey 的集合
Set selectionKeys = selector.selectedKeys();
Iterator iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey selectionKey = iterator.next();
// 发生 OP_ACCEPT 事件,处理连接请求
if (selectionKey.isAcceptable()) {
SocketChannel socketChannel = serverSocketChannel.accept();
// 将 socketChannel 也注册到 selector,关注 OP_READ
// 事件,并给 socketChannel 关联 Buffer
socketChannel.register(selector, SelectionKey.OP_READ, ByteBuffer.allocate(1024));
}
// 发生 OP_READ 事件,读客户端数据
if (selectionKey.isReadable()) {
SocketChannel channel = (SocketChannel) selectionKey.channel();
ByteBuffer buffer = (ByteBuffer) selectionKey.attachment();
channel.read(buffer);
System.out.println("msg form client: " + new String(buffer.array()));
}
// 手动从集合中移除当前的 selectionKey,防止重复处理事件
iterator.remove();
}
}
}
3)AIO:异步非阻塞式 IO。在这种模型中,由操作系统完成与客户端之间的 read/write,之后再由操作系统主动通知服务器线程去处理后面的工作,在这个过程中服务器线程不必同步等待 read/write 完成。由于不同的操作系统对 AIO 的支持程度不同,AIO 目前未得到广泛应用。因此本文对 AIO 不做过多描述。
使用 Java NIO 构建的 IO 程序,它的工作模式是:主动轮训 IO 事件,IO 事件发生后程序的线程主动处理 IO 工作,这种模式也叫做 Reactor 模式。使用 Java AIO 构建的 IO 程序,它的工作模式是:将 IO 事件的处理托管给操作系统,操作系统完成 IO 工作之后会通知程序的线程去处理后面的工作,这种模式也叫做 Proactor 模式。
本节最后,讨论一下网路 IO 中阻塞、非阻塞、异步、同步这几个术语的含义和关系:
阻塞:如果线程调用 read/write 过程,但 read/write 过程没有就绪或没有完成,则调用 read/write 过程的线程会一直等待,这个过程叫做阻塞式读写。
非阻塞:如果线程调用 read/write 过程,但 read/write 过程没有就绪或没有完成,调用 read/write 过程的线程并不会一直等待,而是去处理其他工作,等到 read/write 过程就绪或完成后再回来处理,这个过程叫做阻塞式读写。
异步:read/write 过程托管给操作系统来完成,完成后操作系统会通知(通过回调或者事件)应用网络 IO 程序(其中的线程)来进行后续的处理。
同步:read/write 过程由网络 IO 程序(其中的线程)来完成。
基于以上含义,可以看出:异步 IO 一定是非阻塞 IO;同步 IO 既可以是阻塞 IO、也可以是非阻塞 IO。
1.4. Java NIO API 简单回顾
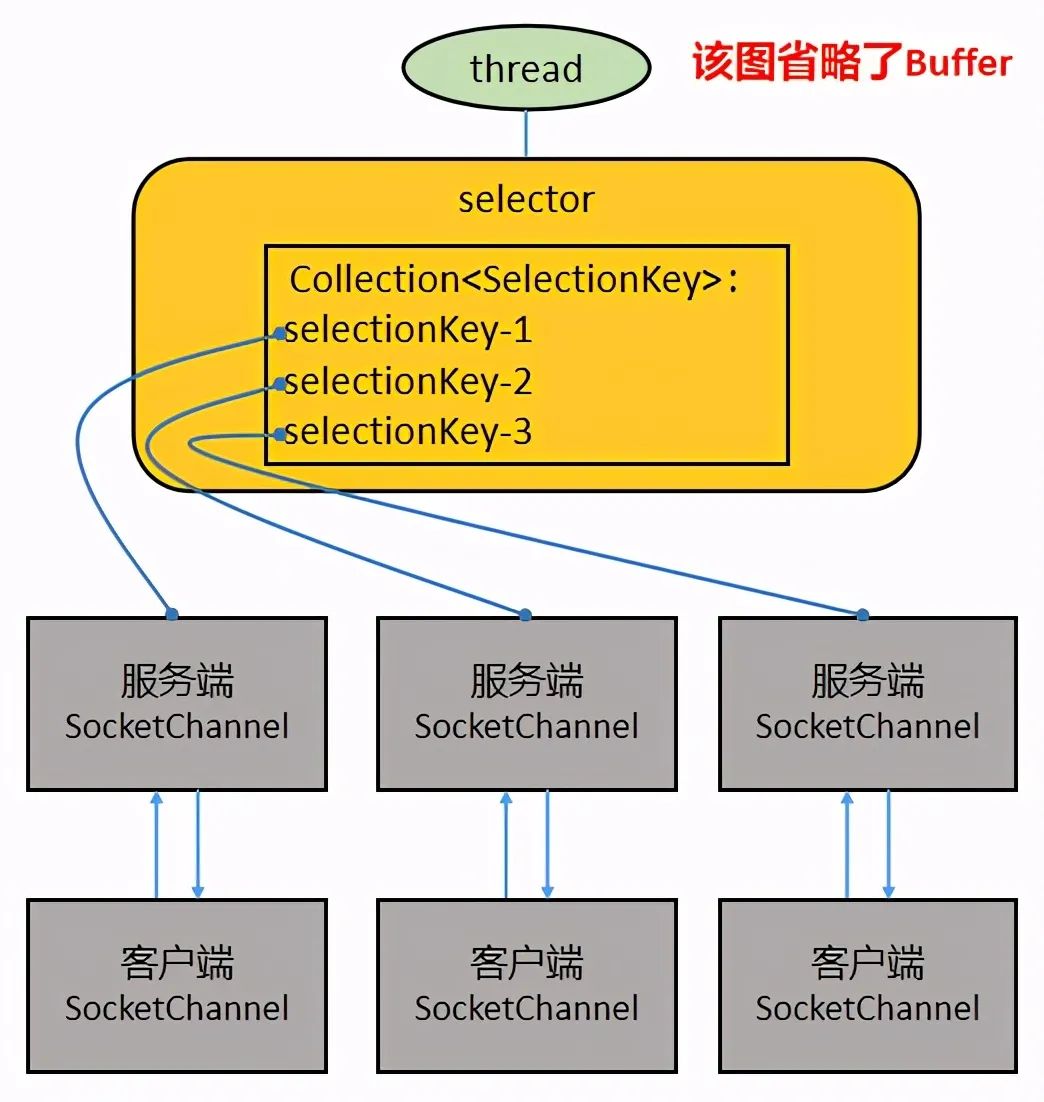
BIO 以流的方式处理数据,而 NIO 以缓冲区(也被叫做块)的方式处理数据,块 IO 效率比流 IO 效率高很多。BIO 基于字符流或者字节流进行操作,而 NIO 基于 Channel 和 Buffer 进行操作,数据总是从通道读取到缓冲区或者从缓冲区写入到通道。Selector 用于监听多个通道上的事件(比如收到连接请求、数据达到等等),因此使用单个线程就可以监听多个客户端通道。如下图所示:
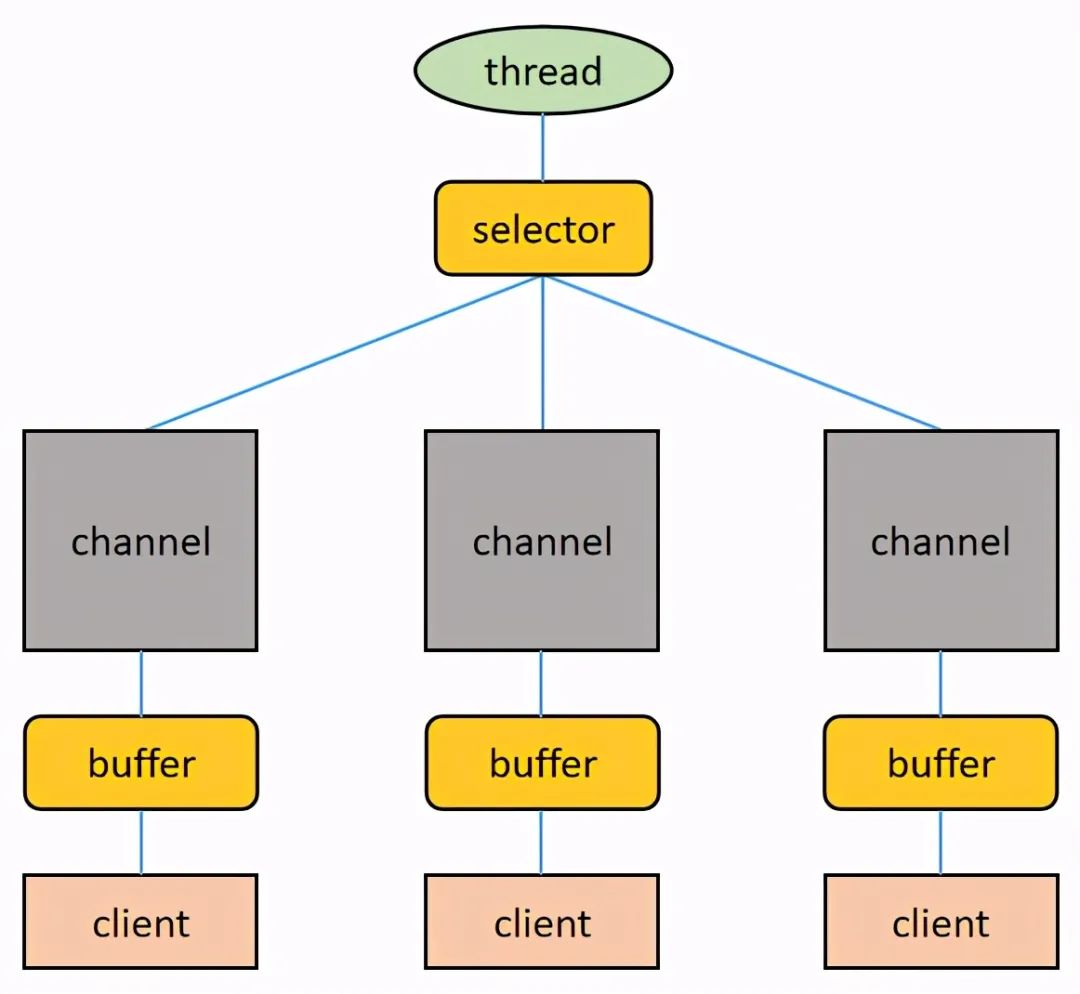
关于上图,再进行几点说明:
一个 Selector 对应一个处理线程
一个 Selector 上可以注册多个 Channel
每个 Channel 都会对应一个 Buffer(有时候一个 Channel 可以使用多个 Buffer,这时候程序要进行多个 Buffer 的分散和聚集操作),Buffer 的本质是一个内存块,底层是一个数组
Selector 会根据不同的事件在各个 Channel 上切换
Buffer 是双向的,既可以读也可以写,切换读写方向要调用 Buffer 的 flip()方法
同样,Channel 也是双向的,数据既可以流入也可以流出
1.4.1. 缓冲区(Buffer)
缓冲区(Buffer)本质上是一个可读可写的内存块,可以理解成一个容器对象,Channel 读写文件或者网络都要经由 Buffer。在 Java NIO 中,Buffer 是一个顶层抽象类,它的常用子类有(前缀表示该 Buffer 可以存储哪种类型的数据):
ByteBuffer
CharBuffer
ShortBuffer
IntBuffer
LongBuffer
DoubleBuffer
FloatBuffer
涵盖了 Java 中除 boolean 之外的所有的基本数据类型。其中 ByteBuffer 支持类型化的数据存取,即可以往 ByteBuffer 中放 byte 类型数据、也可以放 char、int、long、double 等类型的数据,但读取的时候要做好类型匹配处理,否则会抛出 BufferUnderflowException。
另外,Buffer 体系中还有一个重要的 MappedByteBuffer(ByteBuffer 的子类),可以让文件内容直接在堆外内存中被修改,而如何同步到文件由 NIO 来完成。本文重点不在于此,有兴趣的可以去探究一下 MappedByteBuffer 的底层原理。
1.4.2. 通道(Channel)
通道(Channel)是双向的,可读可写。在 Java NIO 中,Buffer 是一个顶层接口,它的常用子类有:
FileChannel:用于文件读写
DatagramChannel:用于 UDP 数据包收发
ServerSocketChannel:用于服务端 TCP 数据包收发
SocketChannel:用于客户端 TCP 数据包收发
1.4.3. 选择器(Selector)
选择器(Selector)是实现 IO 多路复用的关键,多个 Channel 注册到某个 Selector 上,当 Channel 上有事件发生时,Selector 就会取得事件然后调用线程去处理事件。也就是说只有当连接上真正有读写等事件发生时,线程才会去进行读写等操作,这就不必为每个连接都创建一个线程,一个线程可以应对多个连接。这就是 IO 多路复用的要义。
Netty 的 IO 线程 NioEventLoop 聚合了 Selector,可以同时并发处理成百上千的客户端连接,后文会展开描述。
在 Java NIO 中,Selector 是一个抽象类,它的常用方法有:
public abstract class Selector implements Closeable {
......
/**
* 得到一个选择器对象
*/
public static Selector open() throws IOException {
return SelectorProvider.provider().openSelector();
}
......
/**
* 返回所有发生事件的 Channel 对应的 SelectionKey 的集合,通过
* SelectionKey 可以找到对应的 Channel
*/
public abstract Set selectedKeys() ;
......
/**
* 返回所有 Channel 对应的 SelectionKey 的集合,通过 SelectionKey
* 可以找到对应的 Channel
*/
public abstract Set keys() ;
......
/**
* 监控所有注册的 Channel,当其中的 Channel 有 IO 操作可以进行时,
* 将这些 Channel 对应的 SelectionKey 找到。参数用于设置超时时间
*/
public abstract int select(long timeout) throws IOException;
/**
* 无超时时间的 select 过程,一直等待,直到发现有 Channel 可以进行
* IO 操作
*/
public abstract int select() throws IOException;
/**
* 立即返回的 select 过程
*/
public abstract int selectNow() throws IOException;
......
/**
* 唤醒 Selector,对无超时时间的 select 过程起作用,终止其等待
*/
public abstract Selector wakeup();
......
}
在上文的使用 Java NIO 编写的服务端示例代码中,服务端的工作流程为:
1)当客户端发起连接时,会通过 ServerSocketChannel 创建对应的 SocketChannel。
2)调用 SocketChannel 的注册方法将 SocketChannel 注册到 Selector 上,注册方法返回一个 SelectionKey,该 SelectionKey 会被放入 Selector 内部的 SelectionKey 集合中。该 SelectionKey 和 Selector 关联(即通过 SelectionKey 可以找到对应的 Selector),也和 SocketChannel 关联(即通过 SelectionKey 可以找到对应的 SocketChannel)。
4)Selector 会调用 select()/select(timeout)/selectNow()方法对内部的 SelectionKey 集合关联的 SocketChannel 集合进行监听,找到有事件发生的 SocketChannel 对应的 SelectionKey。
5)通过 SelectionKey 找到有事件发生的 SocketChannel,完成数据处理。
以上过程的相关源码为:
/**
* SocketChannel 继承 AbstractSelectableChannel
*/
public abstract class SocketChannel
extends AbstractSelectableChannel
implements ByteChannel,
ScatteringByteChannel,
GatheringByteChannel,
NetworkChannel
{
......
}
public abstract class AbstractSelectableChannel
extends SelectableChannel
{
......
/**
* AbstractSelectableChannel 中包含注册方法,SocketChannel 实例
* 借助该注册方法注册到 Selector 实例上去,该方法返回 SelectionKey
*/
public final SelectionKey register(
// 指明注册到哪个 Selector 实例
Selector sel,
// ops 是事件代码,告诉 Selector 应该关注该通道的什么事件
int ops,
// 附加信息 attachment
Object att) throws ClosedChannelException {
......
}
......
}
public abstract class SelectionKey {
......
/**
* 获取该 SelectionKey 对应的 Channel
*/
public abstract SelectableChannel channel();
/**
* 获取该 SelectionKey 对应的 Selector
*/
public abstract Selector selector();
......
/**
* 事件代码,上面的 ops 参数取这里的值
*/
public static final int OP_READ = 1 << 0;
public static final int OP_WRITE = 1 << 2;
public static final int OP_CONNECT = 1 << 3;
public static final int OP_ACCEPT = 1 << 4;
......
/**
* 检查该 SelectionKey 对应的 Channel 是否可读
*/
public final boolean isReadable() {
return (readyOps() & OP_READ) != 0;
}
/**
* 检查该 SelectionKey 对应的 Channel 是否可写
*/
public final boolean isWritable() {
return (readyOps() & OP_WRITE) != 0;
}
/**
* 检查该 SelectionKey 对应的 Channel 是否已经建立起 socket 连接
*/
public final boolean isConnectable() {
return (readyOps() & OP_CONNECT) != 0;
}
/**
* 检查该 SelectionKey 对应的 Channel 是否准备好接受一个新的 socket 连接
*/
public final boolean isAcceptable() {
return (readyOps() & OP_ACCEPT) != 0;
}
/**
* 添加附件(例如 Buffer)
*/
public final Object attach(Object ob) {
return attachmentUpdater.getAndSet(this, ob);
}
/**
* 获取附件
*/
public final Object attachment() {
return attachment;
}
......
}
下图用于辅助读者理解上面的过程和源码:
首先说明,本文以 Linux 系统为对象来研究文件 IO 模型和网络 IO 模型。
1.5. 零拷贝技术
注:本节讨论的是 Linux 系统下的 IO 过程。并且对于零拷贝技术的讲解采用了一种浅显易懂但能触及其本质的方式,因为这个话题,展开来讲实在是有太多的细节要关注。
在“将本地磁盘中文件发送到网络中”这一场景中,零拷贝技术是提升 IO 效率的一个利器,为了对比出零拷贝技术的优越性,下面依次给出使用直接 IO 技术、内存映射文件技术、零拷贝技术实现将本地磁盘文件发送到网络中的过程。
1)直接 IO 技术
使用直接 IO 技术实现文件传输的过程如下图所示。
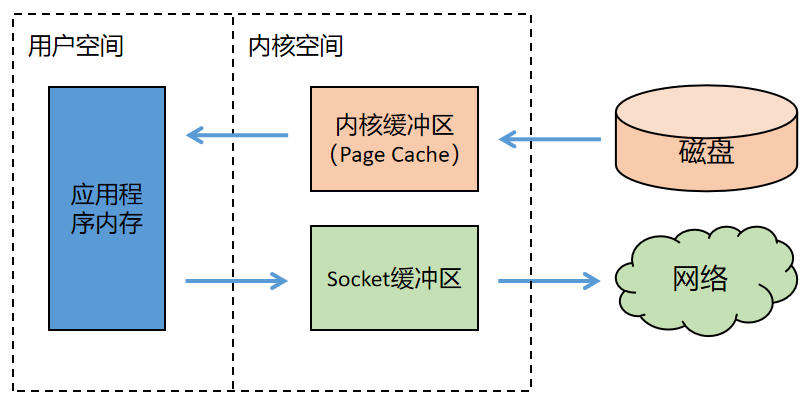
上图中,内核缓冲区是 Linux 系统的 Page Cahe。为了加快磁盘的 IO,Linux 系统会把磁盘上的数据以 Page 为单位缓存在操作系统的内存里,这里的 Page 是 Linux 系统定义的一个逻辑概念,一个 Page 一般为 4K。
可以看出,整个过程有四次数据拷贝,读进来两次,写回去又两次:磁盘-->内核缓冲区-->Socket 缓冲区-->网络。
直接 IO 过程使用的 Linux 系统 API 为:
ssize_t read(int filedes, void *buf, size_t nbytes);
ssize_t write(int filedes, void *buf, size_t nbytes);
等函数。
2)内存映射文件技术
使用内存映射文件技术实现文件传输的过程如下图所示。
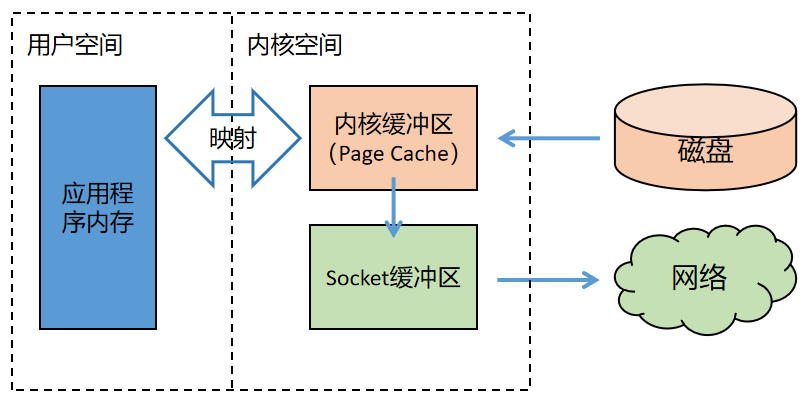
可以看出,整个过程有三次数据拷贝,不再经过应用程序内存,直接在内核空间中从内核缓冲区拷贝到 Socket 缓冲区。
内存映射文件过程使用的 Linux 系统 API 为:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
3)零拷贝技术
使用零拷贝技术,连内核缓冲区到 Socket 缓冲区的拷贝也省略了,如下图所示:
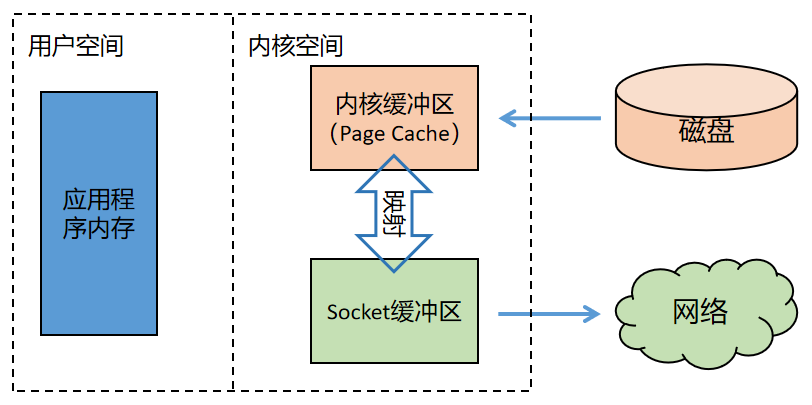
内核缓冲区到 Socket 缓冲区之间并没有做数据的拷贝,只是一个地址的映射。底层的网卡驱动程序要读取数据并发送到网络上的时候,看似读取的是 Socket 的缓冲区中的数据,其实直接读的是内核缓冲区中的数据。
零拷贝中所谓的“零”指的是内存中数据拷贝的次数为 0。
零拷贝过程使用的 Linux 系统 API 为:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
在 JDK 中,提供的:
FileChannel.transderTo(long position, long count, WritableByteChannel target);
方法实现了零拷贝过程,其中的第三个参数可以传入 SocketChannel 实例。例如客户端使用以上的零拷贝接口向服务器传输文件的代码为:
public static void main(String[] args) throws IOException {
SocketChannel socketChannel = SocketChannel.open();
socketChannel.connect(new InetSocketAddress("127.0.0.1", 8080));
String fileName = "test.zip";
// 得到一个文件 channel
FileChannel fileChannel = new FileInputStream(fileName).getChannel();
// 使用零拷贝 IO 技术发送
long transferSize = fileChannel.transferTo(0, fileChannel.size(), socketChannel);
System.out.println("file transfer done, size: " + transferSize);
fileChannel.close();
}
以上部分为第一章,学习 Netty 需要的基础知识。

腾讯、阿里、滴滴后台面试题汇总总结 — (含答案)
面试:史上最全多线程面试题 !
最新阿里内推Java后端面试题
JVM难学?那是因为你没认真看完这篇文章

关注作者微信公众号 —《JAVA烂猪皮》
了解更多java后端架构知识以及最新面试宝典

看完本文记得给作者点赞+在看哦~~~大家的支持,是作者源源不断出文的动力