
【22期】为什么需要消息队列?使用消息队列有什么好处?

阅读本文大概需要 2.8 分钟。
来自:http://t.cn/EogJKg4
目录
一、消息队列的特性
二、为什么需要消息队列?
三、使用消息队列有什么好处?
四、为什么需要分布式?
五、分布式环境下需要解决哪些问题?
六、如何实现?
七、常见消息队列对比和选型
一、消息队列的特性
二、为什么需要消息队列?
三、使用消息队列有什么好处?
3.1、提高系统响应速度
3.2、提高系统稳定性
异步化、解耦、消除峰值
逻辑节点与Db的交互会有大量IO,即使把与Db交互的模块耦合在逻辑节点内,其实现对你来说是黑盒,如果内部是同步实现的,那就直接卡你游戏主逻辑,就因为一次存盘操作,玩家们都掉线了,服务器也可以关掉了。
那么我们改进一下,针对1的情况,可以把这个模块做到一个线程里挂在逻辑节点上。这样其实逻辑节点跟这个Db前端模块的交互就会基于一个比较原始的消息队列。但是这样还有一个坏处,那就是这两种任务一种是计算密集的(玩家的逻辑处理)、一种是IO密集的(只负责写入读取MySQL),搞到一个节点中,扩展起来会非常麻烦,而且耦合度太高。比如说现在发现场景放单节点上有瓶颈,要按场景分节点,那么这种挂在上面的数据模块怎么跟其他场景的交互呢?
峰值的问题。在分布式系统中,一次分布式事务关联的是多个节点,其中每一个节点出现问题都会成为整个事务处理流程中的瓶颈。如果逻辑节点与数据库之间没有一个起到缓冲作用的节点,那就是每次操作都要访问数据库,对于MMO来说,一个玩家上线load几百K数据,一个服10万个玩家上线已经足够搞垮一个mysql节点了。如果直接搞垮还是比较好的结果,至少是前面的玩家确实登录上去了并且可以正常游戏,后面的玩家登录不上。但是很可惜,十年前开始流行的C10K说法就是在讲:并发量上来之后,会造成chain reaction,大量的并发不会直接挂掉你的mysql节点,但是会拖慢速度,降低吞吐量,一个玩家的请求由于处理时间太长,导致玩家放弃重试,但是对于后端来说,对该玩家之前的处理过程消耗的资源就全部浪费了,陷入恶性循环。
四、为什么需要分布式?
4.1、多系统协作需要分布式
4.2、单系统内部署环境需要分布式
五、分布式环境下需要解决哪些问题?
5.1、并发问题
5.2、简单的、统一的操作机制
5.3、容错
5.4、可横向扩展
六、如何实现?
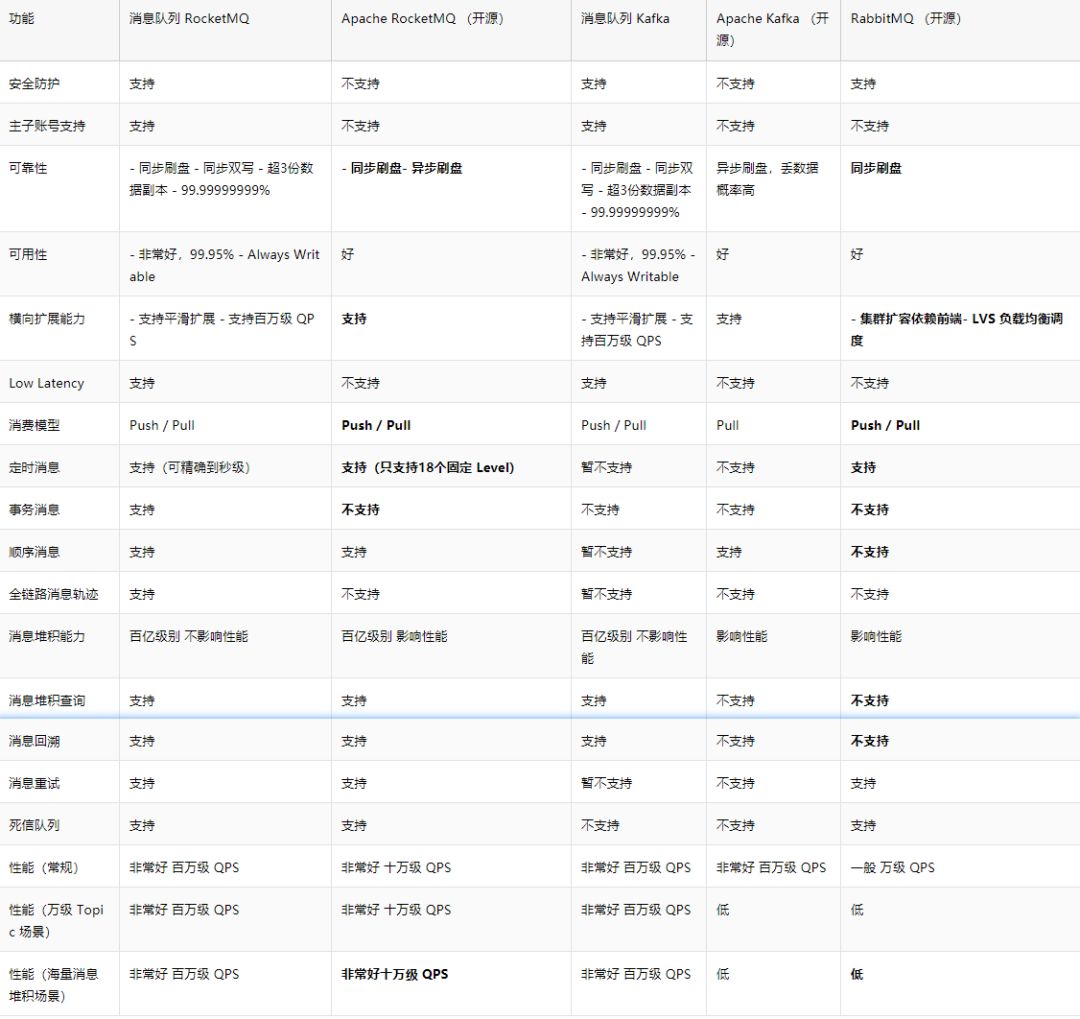
七、常见消息队列对比和选型
推荐阅读:
【21期】你能说说Java中Comparable和Comparator的区别吗
微信扫描二维码,关注我的公众号
朕已阅 