
24道面试题详解,先抓住眼前的

❝学海无涯,近期实践的 24 道面试题,要学习的内容有太多,至少先抓住眼前的知识,希望能在往后面试中帮到大家;
「原创不易,卑微求个赞,谢谢 ^_^」
❞
题目概览
为什么有的编程规范要求用 void 0代替undefined?Undefined和Null的区别JavaScript中的String是否有最大长度?Number 的长度? 为什么 JavaScript 中 x/0 不会报错? 为什么 0.1 + 0.2不等于0.3?为什么给对象添加的方法能用在基本类型上? 什么是装箱转换? 为什么我们常用 Object.prototype.toString来获取对象类型?什么是拆箱转换? try里面放return,finally还会执行吗?为什么 12.toString会报错?关于 **乘方表达式?关于 ==的几个错觉?从输入 URL 到看到网页,经历了什么? HTTP1.1/HTTP2/HTTPS 区别? ['1', '2', '3'].map(parseInt)输出什么?Set/Map/WeakSet/WeakMap 区别? 描述下 es5/es6 继承的区别? 简述下浏览器的渲染过程? 回流和重绘? 如何优化重绘重排? 介绍下 js 的模块化? ES6 转换为 ES5 中间经历了什么?
题目详解
1. 为什么有的编程规范要求用 void 0 代替 undefined?
❝❞
JavaScript的代码undefined是一个变量,而并非是一个关键字,这是JavaScript语言公认的设计失误之一,所以,我们为了避免无意中被篡改,建议使用void 0来获取undefined值。
2. Undefined 和 Null 的区别
Undefined:Undefined类型表示未定义,它的类型只有一个值,就是undefined;JavaScript的代码undefined是一个变量,而并非是一个关键字,这是JavaScript语言公认的设计失误之一;Null:Null类型也只有一个值,就是null,它的语义表示控制,与undefined不同,null是JavaScript中的关键字,所以在任何代码中,你都可以放心的用null关键字来获取null值;
❝❞
Undefined跟Null有一定的表意差别,Null表示的是:“定义了但是为空”。所以,在实际编程时,我们一般不会把变量赋值为undefined,这样可以保证所有值为undefined的变量,都是从未赋值的自然状态。
3. JavaScript 中的 String 是否有最大长度?
答案当然是有的, String有最大长度是2^53 - 1;
❝这个所谓最大长度,并不完全是你理解中的字符数。因为 String 的意义并非“字符串”,而是字符串的 UTF16 编码,我们字符串的操作 charAt、charCodeAt、length 等方法针对的都是 UTF16 编码。所以,字符串的最大长度,实际上是受字符串的编码长度影响的。
❞
❝现行的字符集国际标准,字符是以 Unicode 的方式表示的,每一个 Unicode 的码点表示一个字符,理论上,Unicode 的范围是无限的。UTF 是 Unicode 的编码方式,规定了码点在计算机中的表示方法,常见的有 UTF16 和 UTF8。Unicode 的码点通常用 U+??? 来表示,其中 ??? 是十六进制的码点值。0-65536(U+0000 - U+FFFF)的码点被称为基本字符区域(BMP)。
❞
❝JavaScript 字符串把每个 UTF16 单元当作一个字符来处理,所以处理非 BMP(超出 U+0000 - U+FFFF 范围)的字符时,你应该格外小心。JavaScript 这个设计继承自 Java,最新标准中是这样解释的,这样设计是为了“性能和尽可能实现起来简单”。因为现实中很少用到 BMP 之外的字符。
❞
4. Number 的长度?
Number 类型有 18437736874454810627(即2^64-2^53+3) 个值
5. 为什么 JavaScript 中 x/0 不会报错?
JavaScript 为了表达几个额外的语言场景(比如不让除以 0 出错,而引入了无穷大的概念),规定了几个例外情况: NaN,占用了9007199254740990,这原本是符合IEEE规则的数字;Infinity,无穷大;-Infinity,负无穷大。
❝另外,值得注意的是,JavaScript 中有
❞+0和 -0,在加法类运算中它们没有区别,但是除法的场合则需要特别留意区分,“忘记检测除以 -0,而得到负无穷大”的情况经常会导致错误,而区分 +0 和 -0 的方式,正是检测 1/x 是 Infinity 还是 -Infinity。
6. 为什么 0.1 + 0.2 不等于 0.3?
console.log(0.1 + 0.2 === 0.3); // false
❝根据双精度浮点数的定义,Number 类型中有效的整数范围是 -0x1fffffffffffff 至 0x1fffffffffffff,所以 Number 无法精确表示此范围外的整数。同样根据浮点数的定义,非整数的 Number 类型无法用 ==(=== 也不行) 来比较:这是浮点运算的特点,也是很多同学疑惑的来源,浮点数运算的精度问题导致等式左右的结果并不是严格相等,而是相差了个微小的值。
❞
所以实际上,这里错误的不是结论,而是比较的方法,正确的比较方法是使用 JavaScript 提供的最小精度值:
// 检查等式左右两边差的绝对值是否小于最小精度,才是正确的比较浮点数的方法。
console.log(Math.abs(0.1 + 0.2 - 0.3) <= Number.EPSILON);
7. 为什么给对象添加的方法能用在基本类型上?
❝JavaScript 中的几个基本类型,都在对象类型中有一个“亲戚”。它们是:Number;String;Boolean;Symbol。
❞
我们必须认识到 3 与 new Number(3) 是完全不同的值,它们一个是 Number 类型, 一个是对象类型。 Number、String 和 Boolean,三个构造器是两用的,当跟 new 搭配时,它们产生对象,当直接调用时,它们表示强制类型转换。 Symbol 函数比较特殊,直接用 new 调用它会抛出错误,但它仍然是 Symbol 对象的构造器。
console.log("abc".charAt(0)); //a
Symbol.prototype.hello = () => console.log("hello");
var a = Symbol("a");
console.log(typeof a); //symbol,a并非对象
a.hello(); // hello,有效
所以这里总结答案就是 .运算符提供了装箱操作,它会根据基础类型构造一个临时对象,使得我们能在基础类型上调用对应对象的方法。
8. 什么是装箱转换?
每一种基本类型 Number、String、Boolean、Symbol 在对象中都有对应的类,所谓装箱转换,正是把基本类型转换为对应的对象,它是类型转换中一种相当重要的种类。
❝装箱机制会频繁产生临时对象,在一些对性能要求较高的场景下,我们应该尽量避免对基本类型做装箱转换。
❞
9. 为什么我们常用 Object.prototype.toString 来获取对象类型?
每一类装箱对象皆有私有的 Class 属性,这些属性可以用 Object.prototype.toString获取;在 JavaScript 中,没有任何方法可以更改私有的 Class 属性,因此 Object.prototype.toString是可以准确识别对象对应的基本类型的方法,它比instanceof更加准确。
var symbolObject = Object(Symbol("a"));
console.log(Object.prototype.toString.call(symbolObject)); //[object Symbol]
❝但需要注意的是,
❞call本身会产生装箱操作,所以需要配合typeof来区分基本类型还是对象类型。
10. 什么是拆箱转换?
在 JavaScript标准中,规定了ToPrimitive函数,它是对象类型到基本类型的转换(即,拆箱转换)
❝对象到 String 和 Number 的转换都遵循“先拆箱再转换”的规则。通过拆箱转换,把对象变成基本类型,再从基本类型转换为对应的 String 或者 Number。
❞
拆箱转换会尝试调用 valueOf和toString来获得拆箱后的基本类型。如果valueOf和toString都不存在,或者没有返回基本类型,则会产生类型错误 TypeError。
var o = {
valueOf: () => {
console.log("valueOf");
return {};
},
toString: () => {
console.log("toString");
return {};
},
};
// Number 的转换 先 valueOf 再 toString
o * 2; // TypeError
// String 的转换则是 先 toString 再 valueOf
String(o); // TypeError
// 在 ES6 之后,还允许对象通过显式指定 @@toPrimitive Symbol 来覆盖原有的行为。
o[Symbol.toPrimitive] = () => {
console.log("toPrimitive");
return "hello";
};
// toPrimitive
console.log(o + ""); // hello
11. try 里面放 return,finally 还会执行吗?
finally不管try/catch如何处理最终都会执行,并且如果finally中加入return/throw则会覆盖try/catch的return或者throw;
function foo() {
try {
return 0;
} catch (err) {
} finally {
// 这里会先执行
console.log("a");
}
}
console.log(foo());
// a
// 0
function foo() {
try {
i++;
return 0;
} catch (err) {
throw err;
} finally {
// 最终以 finally 为主
return 1;
}
}
console.log(foo()); // 1
12. 为什么 12.toString 会报错?
这时候 12.会被当作省略了小数点后面部分的数字,而单独看成一个整体,所以我们要想让点单独成为一个token,就要加入空格,或者 .,这样写:12 .toString()/12..toString()
// 数字直接量
.01
12.
12.01
❝Token 词
❞
IdentifierName 标识符名称,典型案例是我们使用的变量名,注意这里关键字也包含在内了。 Punctuator 符号,我们使用的运算符和大括号等符号。 NumericLiteral 数字直接量,就是我们写的数字。 StringLiteral 字符串直接量,就是我们用单引号或者双引号引起来的直接量。 Template 字符串模板,用反引号` 括起来的直接量。
13. 关于 ** 乘方表达式?
**运算是右结合的,因此2 ** 2 ** 3运算规则如下:
2 ** (2 ** 3); // 256
-2这样的一元运算表达式,是不可以放入乘方表达式的,如果需要表达类似的逻辑,必须加括号。
(++i) ** 30;
2 ** 30; //正确
// -2 ** 30 //报错
(-2) ** 30;
14. 关于 == 的几个错觉?
即使字符串与布尔值比较,也都要转换为数字
false == "0"; // true
true == "true"; // false
对象如果转换成了 primitive 类型跟等号另一边类型恰好相同,则不需要转换成数字。
[] == "" // true
[] == 0 // true
[] == false // true
❝所以
❞==比较坑,尽量还是使用===,或者仅在确定字符串与数值比较时去使用==
15. 从输入 URL 到看到网页,经历了什么?
浏览器首先使用 HTTP 协议或者 HTTPS 协议,向服务端请求页面; 把请求回来的 HTML 代码经过解析,构建成 DOM 树; 计算 DOM 树上的 CSS 属性; 最后根据 CSS 属性对元素逐个进行渲染,得到内存中的位图; 一个可选的步骤是对位图进行合成,这会极大地增加后续绘制的速度; 合成之后,再绘制到界面上。
16. HTTP1.1/HTTP2/HTTPS 区别?
HTTP2 相比于 HTTP1.1
❝
总的来说 HTTP2 大幅度的提升了 web 性能。在与 HTTP/1.1 完全语义兼容的基础上,进一步减少了网络延迟,在性能上大幅提升。
❞❝
在二进制分帧层中, HTTP/2 会将所有传输的信息分割为更小的消息和帧(frame),并对它们采用二进制格式的编码 ,其中 HTTP1.x 的首部信息会被封装到 HEADER frame,而相应的 Request Body 则封装到 DATA frame 里面。
❞
HTTP/2 通信都在一个连接上完成,这个连接可以承载任意数量的双向数据流。
在过去, HTTP 性能优化的关键并不在于高带宽,而是低延迟。TCP 连接会随着时间进行自我「调谐」,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度。这种调谐则被称为 TCP 慢启动。由于这种原因,让原本就具有突发性和短时性的 HTTP 连接变的十分低效。
HTTP/2 通过让所有数据流共用同一个连接,可以更有效地使用 TCP 连接,让高带宽也能真正的服务于 HTTP 的性能提升。❝
HTTP/1.1 并不支持 HTTP 首部压缩,为此 SPDY 和 HTTP/2 应运而生, SPDY 使用的是通用的 算法,而 HTTP/2 则使用了专门为首部压缩而设计的 HPACK 算法。
❞单连接多资源的方式,减少服务端的链接压力,内存占用更少,连接吞吐量更大 由于 TCP 连接的减少而使网络拥塞状况得以改善,同时慢启动时间的减少,使拥塞和丢包恢复速度更快 首部压缩 服务端推送:能够在客户端发送第一个请求到服务端时,提前把一部分内容推送给客户端,放入缓存当中,这可以避免客户端请求顺序带来的并行度不高,从而导致的性能问题。 TCP 连接复用,则使用同一个 TCP 连接来传输多个 HTTP 请求,避免了 TCP 连接建立时的三次握手开销,和初建 TCP 连接时传输窗口小的问题。 二进制分帧 HTTPS 有两个作用,一是确定请求的目标服务端身份,二是保证传输的数据不会被网络中间节点窃听或者篡改。
❝HTTPS 是使用加密通道来传输 HTTP 的内容。但是 HTTPS 首先与服务端建立一条 TLS 加密通道。TLS 构建于 TCP 协议之上,它实际上是对传输的内容做一次加密,所以从传输内容上看,HTTPS 跟 HTTP 没有任何区别。
❞
17. ['1', '2', '3'].map(parseInt) 输出什么?
乍一看可能会说出 [1, 2, 3],其实不然,答案是[1, NaN, NaN]
["1", "2", "3"].map(parseInt);
// parseInt(string, radix) 接收2个参数,(要处理的值, 解析时的基数)
// 基数是一个介于2和36之间的整数
// 平铺一下
["1", "2", "3"].map((item, idx) => parseInt(item, idx));
parseInt("1", 0); // 1 radix为 0时该值无效,且第一个参数不以“0x”和“0”开头时,按照10为基数处理。这个时候返回1
parseInt("2", 1); // NaN 当radix小于2并且大于36或第一个参数的第一个非空格字符不能转换为数字。
parseInt("3", 2); // NaN 基数为2(2进制)表示的数中,最大值小于3,所以无法解析,返回NaN
18. Set/Map/WeakSet/WeakMap 区别?
Set
❝❞
成员不能重复 只有健值,没有健名,有点类似数组。 可以遍历,方法有 add, delete, has
WeakSet
❝❞
只能储存对象引用,不能存放值,而 Set 对象都可以 成员都是弱引用,即垃圾回收机制不考虑 WeakSet 对该对象的应用,随时可以消失。可以用来保存 DOM 节点,不容易造成内存泄漏 不能遍历,方法有 add, delete, has
Map
❝❞
本质上是健值对的集合,类似集合 可以遍历,方法很多,方便跟各种数据格式进行转换
WeakMap
❝❞
直接受对象作为健名(null 除外),不接受其他类型的值作为健名 健名所指向的对象,不计入垃圾回收机制 不能遍历,方法同 get, set, has, delete
19. 描述下 es5/es6 继承的区别?
class的声明没有被变量提升,类似let/const的声明,不能前置使用;
var t = new Test(); // Test is not defined
class Test {}
class声明内部会启用严格模式
class Test {
constructor() {
empty = "test"; // empty is not defined
}
}
class的所有方法(包括静态方法和实例方法)都是不可枚举的
class Text {
constructor() {
this.a = 1;
}
func1() {}
func2() {}
}
console.log(Object.keys(Text)); // []
console.log(Object.keys(Text.prototype)); // []
Object.keys(new Text()); // ['a']
function Func() {
this.a = 1;
this.fun1 = function () {};
this.fun2 = function () {};
}
Func.prototype.func3 = function () {};
console.log(Object.keys(Func)); // []
console.log(Object.keys(Func.prototype)); // ['func3']
Object.keys(new Func()); // ['a', 'func1', 'func2']
class的所有方法(包括静态方法和实例方法)都没有原型对象prototype,所以也没有constructor,不能使用 new 来调用其方法
var a = new Text();
new a.func1(); // a.test is not a constructor
必须使用 new调用class
Text(); // Class constructor A cannot be invoked without 'new'
new Text();
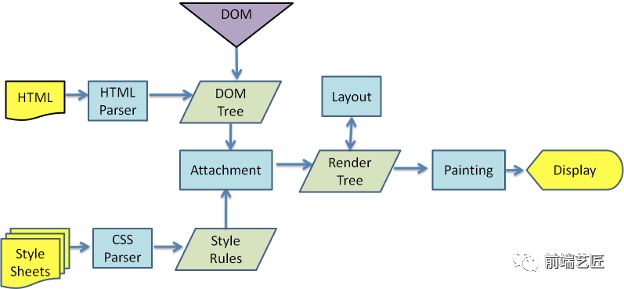
20. 简述下浏览器的渲染过程?
解析 HTML,生成 DOM 树,解析 CSS,生成 CSSOM 树 将 DOM 树和 CSSOM 树结合,生成渲染树(Render Tree)
❝构建渲染树:
❞
从 DOM 树的根节点开始遍历每个可见节点。 对于每个可见的节点,找到 CSSOM 树中对应的规则,并应用它们。 根据每个可见节点以及其对应的样式,组合生成渲染树。
Layout(回流):根据生成的渲染树,进行回流(Layout),得到节点的几何信息(位置,大小) Painting(重绘):根据渲染树以及回流得到的几何信息,得到节点的绝对像素 Display:将像素发送给 GPU,展示在页面上。(这一步其实还有很多内容,比如会在 GPU 将多个合成层合并为同一个层,并展示在页面中。而 css3 硬件加速的原理则是新建合成层,这里我们不展开,之后有机会会写一篇博客)
21. 回流和重绘?
重绘:由于节点的几何属性发生改变或者由于样式发生变化而不影响布局的成为重绘。
❝例如 outline, visibility, color、background-color 等,重绘的代价是高昂的,因为浏览器必须验证 DOM 树上其他节点元素的可见性。
❞
回流:回流是布局或者几何属性需要改变就称为回流。回流是影响浏览器性能的关键因素,因为其变化涉及到部分页面(或是整个页面)的布局更新。一个元素的回流可能会导致了其所有子元素以及 DOM 中紧随其后的节点、祖先节点元素的随后的回流。
❝大部分的回流将导致页面的重新渲染,回流必定会导致重绘,但是,重绘不一定会引发回流
❞
22. 如何优化重绘重排?
1.浏览器优化
❝现代浏览器大多都是通过
队列机制来批量更新布局,浏览器会把修改操作放在队列中,至少一个浏览器刷新(即 16.6ms)才会清空队列,但当你获取布局信息的时候,队列中可能有会影响这些属性或方法返回值的操作,即使没有,浏览器也会强制清空队列,触发回流与重绘来确保返回正确的值。以下属性或方法的使用都会强制刷新队列,应避免频繁使用:
❞
offsetTop、offsetLeft、offsetWidth、offsetHeight scrollTop、scrollLeft、scrollWidth、scrollHeight clientTop、clientLeft、clientWidth、clientHeight width、height getComputedStyle() getBoundingClientRect()
2.减少重绘与回流
❝❞
使用 transform 替代 to 使用 visibility 替换 display: none ,因为前者只会引起重绘,后者会引发回流(改变了布局) 避免使用 table 布局,可能很小的一个小改动会造成整个 table 的重新布局。 尽可能在 DOM 树的最末端改变 class,回流是不可避免的,但可以减少其影响。尽可能在 DOM 树的最末端改变 class,可以限制了回流的范围,使其影响尽可能少的节点。 避免设置多层内联样式,CSS 选择符从右往左匹配查找,避免节点层级过多。 将动画效果应用到 position 属性为 absolute 或 fixed 的元素上,避免影响其他元素的布局,这样只是一个重绘,而不是回流,同时,控制动画速度可以选择 requestAnimationFrame 避免使用 CSS 表达式,可能会引发回流。 将频繁重绘或者回流的节点设置为图层,图层能够阻止该节点的渲染行为影响别的节点,例如 will-change、video、iframe 等标签,浏览器会自动将该节点变为图层。 CSS3 硬件加速(GPU 加速),使用 css3 硬件加速,可以让 transform、opacity、filters 这些动画不会引起回流重绘 。但是对于动画的其它属性,比如 background-color 这些,还是会引起回流重绘的,不过它还是可以提升这些动画的性能。 避免频繁操作样式,最好一次性重写 style 属性,或者将样式列表定义为 class 并一次性更改 class 属性。 避免频繁操作 DOM,创建一个 documentFragment,在它上面应用所有 DOM 操作,最后再把它添加到文档中。 避免频繁读取会引发回流/重绘的属性,如果确实需要多次使用,就用一个变量缓存起来。 对具有复杂动画的元素使用绝对定位,使它脱离文档流,否则会引起父元素及后续元素频繁回流。
23. 介绍下 js 的模块化?
Commonjs(2009):号召规范服务端的 js 接口,形成了 ServerJs 规范(即 CommonJs)CommonJS 内的模块规范成为了 Node.js 的标准实现规范
// file module.js
// 对外输出
module.exports = {
a: 1,
b: 2,
};
// file test.js 引入一个模块
var test = require("module.js").a; // 1
AMD(2009):js 模块的异步加载 , require.js、curl是其对应实现
❝❞
源自 CommonJS,但是 异步的加载的 模块下载完后,立即执行加载,所有模块加载完毕进入回调 随着以 npm (遵循 CommonJS 规范)为主导的依赖管理机制的统一,越来越多的开发者放弃了使用 AMD 模式。
// file module.js 定义一个模块
define(function () {
return {
a: 1,
b: 2,
};
});
// file hello.js 引入一个模块
define(["./module.js"], function (module) {
console.log(module.a, module.b);
});
UMD(2011):为了支持一个模块同时兼容 AMD 和 CommonJs 规范,适用于 同时支持浏览器端和服务端引用的第三方库,提出了 UMD 规范
// 定义一个模块
(function (root, factory) {
if (typeof define === "function" && define.amd) {
// AMD
define(["jquery", "underscore"], factory);
} else if (typeof exports === "object") {
// Node, CommonJS之类的
module.exports = factory(require("jquery"), require("underscore"));
} else {
// 浏览器全局变量(root 即 window)
root.returnExports = factory(root.jQuery, root._);
}
})(this, function ($, _) {
// 方法
function a() {} // 私有方法,因为它没被返回 (见下面)
function b() {} // 公共方法,因为被返回了
function c() {} // 公共方法,因为被返回了
// 暴露公共方法
return {
b: b,
c: c,
};
});
CMD(2011): require.js需要提前声明 所依赖的库,为了做到 看起来"使用时才加载"(就近依赖),创造了 sea.js,同时其对应 CMD 规范,下载完后,并不立即执行,回调函数中遇到 require 才执行加载模块
// 定义一个模块
define(function (require, exports, module) {
// ....
});
//sea.js:
define(function (require, exports, module) {
var mod_A = require("dep_A");
var mod_B = require("dep_B");
var mod_C = require("dep_C");
});
ES2015 Modules(2015):导入的值也是只读不可变对象(丧失了 CommonJS 的修改特性,但也是一个优点,保证了 ES6 Modules 的依赖关系是确定(Deterministic)的,和运行时的状态无关,从而也就保证了 ES6 Modules 是可以进行可靠的静态分析的。),不像 CommonJS 是一个内存的拷贝
// file module.js
export const a = 1;
export function b (){
}
export default {
c: 3
}
// file test.js
import {a, b}, c from './module.js'
24. ES6 转换为 ES5 中间经历了什么?
❝这里其实我们可以参考 babel 的实现思路
❞
将代码字符串解析成抽象语法树,即所谓的 AST ❝
可以使用
❞@babel/parser的parse方法,将代码字符串解析成 AST;对 AST 进行处理,在这个阶段可以对 ES6 代码进行相应转换,即转成 ES5 代码 ❝
使用
❞@babel/core的transformFromAstSync方法,对 AST 进行处理,将其转成 ES5 并生成相应的代码字符串;过程中,可能还需要使用@babel/traverse来获取依赖文件等。根据处理后的 AST 再生成代码字符串