
我用Python抓取8万条《装台》弹幕,都说了啥?
点上方蓝色“菜鸟学Python”,选“星标”公众号
第428篇原创

最近,电视剧《装台》在CCTV-1黄金档播出后,电视剧中,地道的当地美食受到网友热评,而且剧中接地气的剧情、演员们的真情实感的演绎也获得了业界的好评!
人民日报更是用了很大篇幅的文章,高度的赞扬了《装台》这部影视作品,表扬其“歪滴很”!不仅如此,在豆瓣的影视评分中,《装台》也以8.4分的高分获得了票房和口碑的双丰收。
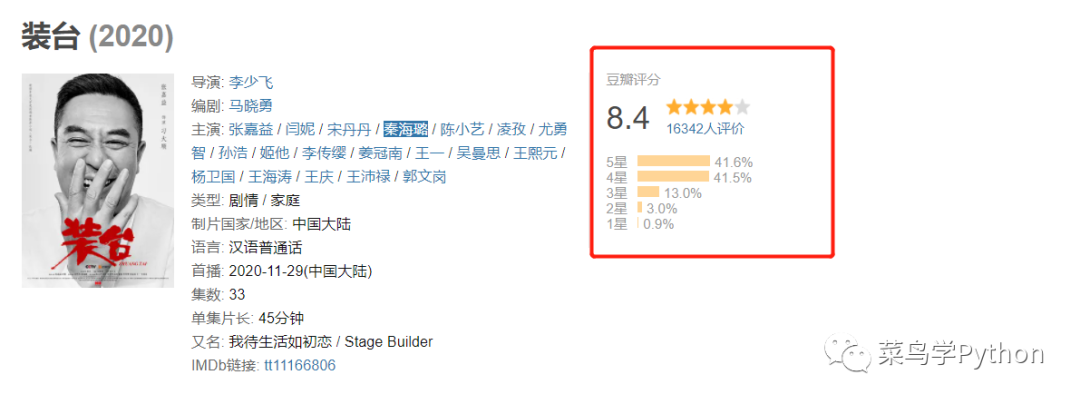
8.4分其实比较高了,要知道前段时间的李易峰和金晨演的《隐秘而伟大》才8.2分,可见装台的火热程度。剧中的张嘉益和闫妮老师的表演也是非常精彩,实力派的演员就是不一样,小编也追剧了很久,今天用Python来分析一下。
整个的数据分析分为两部分,第一部分是豆瓣的短评,第二部是芒果TV几万条弹幕的分析,我们一起来看一下。
用的工具和库:
Pandas
Pyecharts
Altair
Stylecloud
爬取豆瓣点评
我们首先来看一下豆瓣上关于《装台》的评价。这里,我们获取到了500条对于《装台》的豆瓣短评数据,并获取了500条短评的推荐指数。
豆瓣的爬取网上的方法很多,因为有反爬的限制,一般都是用selenium进行登入,然后对爬取的内容进行解析。
1).模拟登入
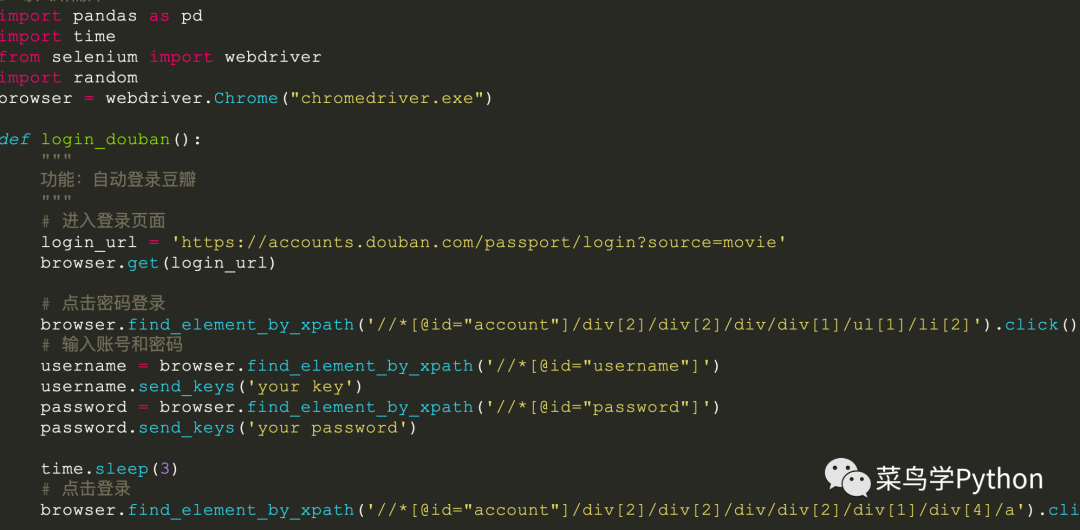
这里我们主要是用selenium来模拟浏览器进行登入,需要输入你的账户和密码,然后找到对应的一些控件进入输入,然后提交。
2).爬取短评
经过前面的第一步的准备,我们就可以开始爬取数据了:
主要是构造电视剧的url,然后进行翻;
对每一页的数据,我们需要提取4个唯独的数据,用户名,评分,评论时间,评论内容等等;
保存数据,这里我们直接保存为df格式;
最后我们保存的数据长的这样:

3).数据可视化
我们需要对数据进行一些清洗,然后规整之后开始进行可视化的分析。比如根据大家的推荐指数,来进行不同推荐指数的数量统计,并运行下列程序,进行推荐指数的分布可视化:

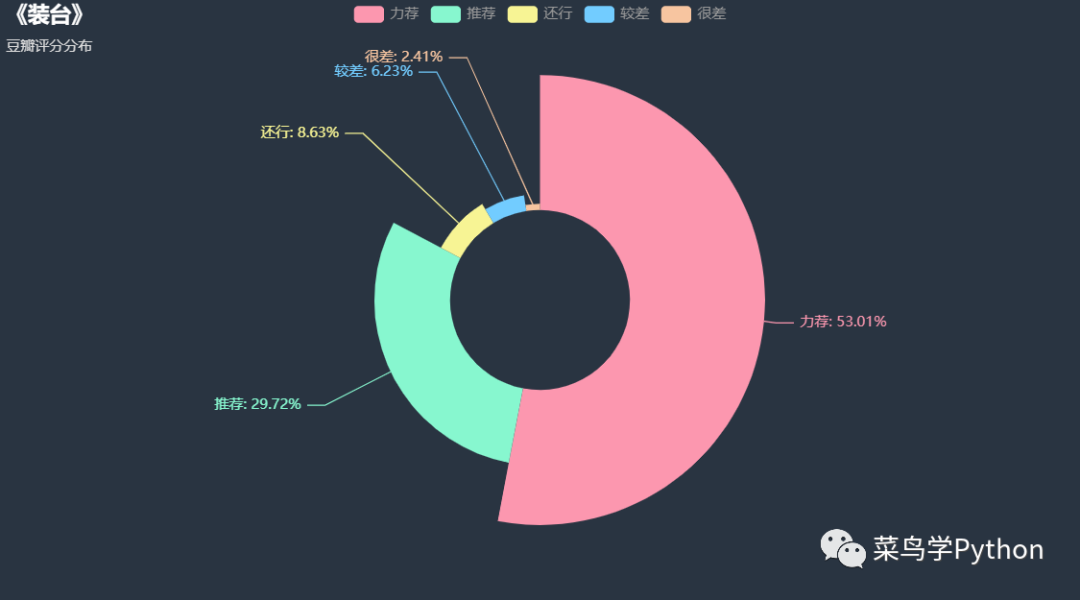
从大家的推荐指数来看,超过半数的豆瓣评论者给出了“力荐”的评价,而给出“较差”和“很差”的评论者占总人数的不到10%。说明这部剧得到了绝大多数观看者的认可。
4).利用神器Altair动态分析
上面是用pyecharts做可视化分析,这里我换一个神器(再见Matplotlib!我用这款Python神器了!),用Altair来分析评论者给出的推荐指数随着时间的分布变化,运行下图所示的程序:

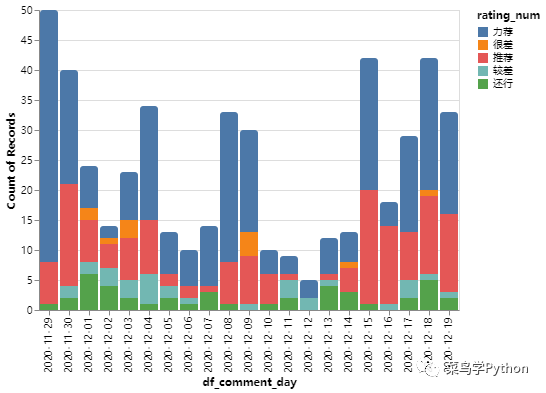
从上图可以看出,随着时间的推移,“力荐”指数依旧牢牢的把握住了大多数的推荐指标。而在总体的推荐数量上,推荐数量随着时间呈现一种波动形式。
05).词云的分析
那么豆瓣上的影评者对于《装台》的词云评价是如何的呢?我们通过jieba库进行分词,然后利用stylecloud库来制作词云的可视化展示。程序和词云的可视化展示如下图所示:

可以看到,大家的影评中提到最多的关键词包括了“生活”、“接地气”等,而大家对于这部影视作品的态度则是“喜欢”、“好看”。
芒果TV上8万弹幕抓取
看完500个短评是不是不过瘾,这次我们来弄更大一点的数据来分析和挖掘我们从芒果TV中,抓取前20集的弹幕内容,并进行数据的处理和分析。
1).如何抓取弹幕
首先,我们来看一下应该如何来抓取弹幕内容。在网页中打开芒果TV,并播放《装台》,如下图所示:
https://bullet-ws.hitv.com/bullet/2020/12/19/003728/10438285/1.json
https://bullet-ws.hitv.com/bullet/2020/12/19/000001/10439875/1.json
而json数据的“1”、“2”、“3”代表每一集的长度,也就是有多少分钟。

上图中可以看出,弹幕数量随着剧集的发展呈现下降的趋势,第一集的弹幕数量最高,为8185条。最少的为第19集,为1980条。
3).看看大家都说啥
接下来我们来看看大家的弹幕信息词云,看看网友的弹幕中包含了哪些关键词信息。

1.扫描下面的公众号(非本公众号)
2.输入:装台
输入:装台
获取源码
推荐阅读:
这个GitHub 1400星的Git魔法书火了,斯坦福校友出品丨有中文版 贼 TM 好用的 Java 工具类库 超全Python IDE武器库大总结,优缺点一目了然! 秋招来袭!GitHub28.5颗星!这个汇聚阿里,腾讯,百度,美团,头条的面试题库必须安利! 收获10400颗星!这个Python库有点黑科技,竟然可以伪造很多'假'的数据! 牛掰了!这个Python库有点逆天了,竟然能把图片,视频无损清晰放大!
点这里,获取一大波福利
