
Go udp 的高性能优化
前段时间(已经是 2 年前了😛)优化了 golang udp client 和 server 的性能问题,我在这里简单描述下 udp 服务的优化过程。
当然,udp 性能本就很高,就算不优化,也轻易可以到几十万的 qps,但我们想更好的优化 go udp server 和 client。
UDP 存在粘包半包问题?
我们知道应用程序之间的网络传输会存在粘包半包的问题。该问题的由来我这里就不描述了,大家去搜吧。使用 tcp 会存在该问题,而 udp 是不存在该问题的。
为啥? tcp 是无边界的,tcp 是基于流传输的,tcp 报头没有长度这个变量,而 udp 是有边界的,基于消息的,是可以解决粘包问题的。udp 协议里有 16 位来描述包的大小,16 位决定他的数字最大数字是 65536,除去 udp 头和 ip 头的大小,最大的包差不多是 65507 byte。
但根据我们的测试,udp 并没有完美的解决应用层粘包半包的问题。如果你的 go udp server 的读缓冲是 1024,那么 client 发送的数据不能超过 server read buf 定义的 1024 byte,不然还是要处理半包了。如果发送的数据小于 1024 byte,倒是不会出现粘包的问题。
// xiaorui.cc
buf := make([]byte, 1024)
for {
n, _ := ServerConn.Read(buf[0:])
if string(buf[0:n]) != s {
panic(...)
...
在 Linux下 借助 strace 发现 syscall read fd 的时候,最大只获取 1024 个字节。这个 1024 就是上面配置的读缓冲大小。
// xiaorui.cc
[pid 25939] futex(0x56db90, FUTEX_WAKE, 1) = 1
[pid 25939] read(3, "Introduction... 隐藏... overview of IPython'", 1024) = 1024
[pid 25939] epoll_ctl(4, EPOLL_CTL_DEL, 3, {0, {u32=0, u64=0}}) = 0
[pid 25939] close(3
[pid 25940] <... restart_syscall resumed> ) = 0
[pid 25939] <... close resumed> ) = 0
[pid 25940] clock_gettime(CLOCK_MONOTONIC, {19280781, 509925143}) = 0
[pid 25939] pselect6(0, NULL, NULL, NULL, {0, 1000000}, 0
[pid 25940] pselect6(0, NULL, NULL, NULL, {0, 20000}, 0) = 0 (Timeout)
[pid 25940] clock_gettime(CLOCK_MONOTONIC, {19280781, 510266460}) = 0
[pid 25940] futex(0x56db90, FUTEX_WAIT, 0, {60, 0}
下面是 golang 里 socket fd read 的源码,可以看到你传入多大的 byte 数组,他就 syscall read 多大的数据。
// xiaorui.cc
func read(fd int, p []byte) (n int, err error) {
var _p0 unsafe.Pointer
if len(p) > 0 {
_p0 = unsafe.Pointer(&p[0])
} else {
_p0 = unsafe.Pointer(&_zero)
}
r0, _, e1 := Syscall(SYS_READ, uintptr(fd), uintptr(_p0), uintptr(len(p)))
n = int(r0)
if e1 != 0 {
err = errnoErr(e1)
}
return
}
http2 为毛比 http1 的协议解析更快,是因为 http2 实现了 header 的 hpack 编码协议。thrift 为啥比 grpc 快?单单对比协议结构体来说,thrift 和 protobuf 的性能半斤八两,但对比网络应用层协议来说,thrift 要更快。因为grpc是在 http2 上跑的,grpc server 不仅要解析 http2 header,还要解析 http2 body,这个 body 就是 protobuf 数据。
所以说,高效的应用层协议也是高性能服务的重要的一个标准。我们先前使用的是自定义的 TLV 编码,t 是类型,l 是 length,v 是数据。一般解决网络协议上的数据完整性差不多是这个思路。当然,我也是这么搞得。
如何优化 udp 应用协议上的开销?
上面已经说了,udp 在合理的 size 情况下是不需要依赖应用层协议解析包问题。那么我们只需要在 client 端控制 send 包的大小,server 端控制接收大小,就可以节省应用层协议带来的性能高效。😁别小看应用层协议的 cpu 消耗!
解决 golang udp 的锁竞争问题
在 udp 压力测试的时候,发现 client 和 server 都跑不满 cpu 的情况。开始以为是 golang udp server 的问题,去掉所有相关的业务逻辑,只是单纯的做 atomic 计数,还是跑不满 cpu。通过 go tool pprof 的函数调用图以及火焰图,看不出问题所在。尝试使用 iperf 进行 udp 压测,golang udp server 的压力直接干到了满负载。可以说是压力源不足。
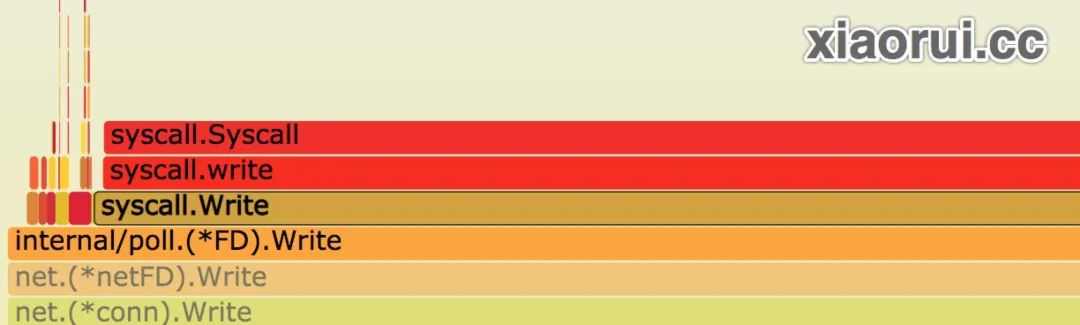
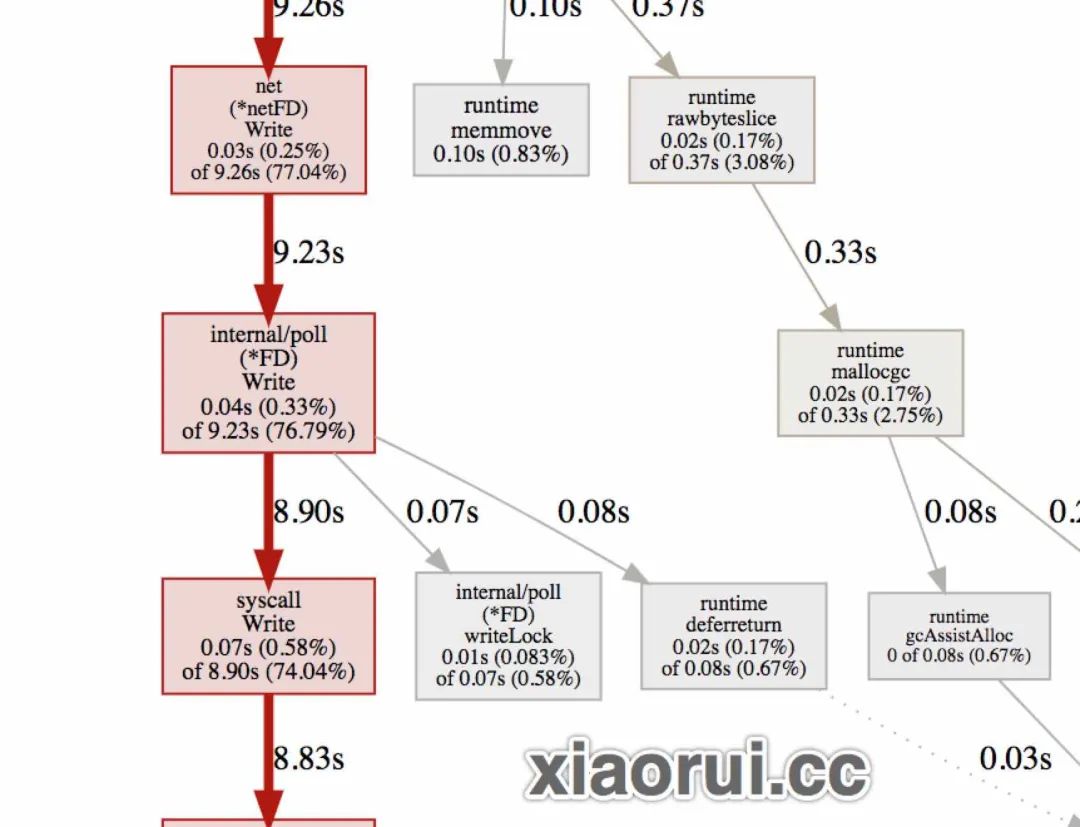
那么 udp 性能上不去的问题看似明显了,应该是 golang udp client 的问题了。我尝试在 go udp client 里增加了多协程写入,10 个 goroutine,100 个 goroutine,500 个 goroutine,都没有好的明显的提升效果,而且性能抖动很明显。😅
进一步排查问题,通过 lsof 分析 client 进程的描述符列表,client 连接 udp server 只有一个连接。也就是说,500 个协程共用一个连接。接着使用 strace 做 syscall 系统调用统计,发现 futex 和 pselect6 系统调用特别多,这一看就是存在过大的锁竞争。翻看 golang net 源代码,果然发现 golang 在往 socket fd 写入时,存在写锁竞争。
TODO 图片
// xiaorui.cc
// Write implements io.Writer.
func (fd *FD) Write(p []byte) (int, error) {
if err := fd.writeLock(); err != nil {
return 0, err
}
defer fd.writeUnlock()
if err := fd.pd.prepareWrite(fd.isFile); err != nil {
return 0, err
}
}
怎么优化锁竞争?
实例化多个 udp 连接到一个数组池子里,在客户端代码里随机使用 udp 连接。这样就能减少锁的竞争了。
总结
udp 性能调优的过程就是这样子了。简单说就两个点:一个是消除应用层协议带来的性能消耗,再一个是 golang socket 写锁带来的竞争。
当我们一些性能问题时,多使用 perf、strace 功能,再配合 golang pprof 分析火焰图来分析问题。实在不行,直接干 golang 源码。👌

👍长按图片打赏芮神