
博客园 .NET 5 之路,我们可以学到什么?
移动开发和人工智能编者: 博客园团队发布的原文:Memcached 的惹祸,.NET 5.0 的背锅, 博客园觉得上次升级.NET 5在没有确认具体的原因的情况下把锅甩错了,因此有了这篇文章。
下面是博客园的博客原文:
抱歉,拖到现在才写这篇为 .NET 5.0 洗白的博文(之前的博文),不好意思,又错了,不是洗白,是还 .NET 5.0 的清白。
抱歉,就在今天上午写这篇博客的过程中,由于一个bug被迫在访问高峰发布,在10:30~11:10再次引发上次遇到的同样故障,由此给您带来麻烦,请您谅解。
2020年10月14日晚上我们发布了升级至 .NET 5.0 RC 2 的博客系统,在正式版发布之前进行升级不是我们想追求前卫,而是因为:
微软官博已经说明可以用于生产环境
RC2 is a “go live” release; you are supported using it in production.
正则表达式性能大幅提升(Regular expression performance improvements)
On many of the expressions we’ve tried, these improvements routinely result in throughput improvements of 3-6x, and in some cases, much more.
Json 序列化性能提升
JsonSerializer performance is significantly improved in .NET 5.0.
想使用 EF Core 5.0 的新特性(What's New in EF Core 5.0)
最吸引我们的是第2点,博客系统的代码中用了很多正则表达式,是耗CPU大户。
而且升级很简单:
TargetFramework 由
netcoreapp3.1改为net5.0更新 nuget 包
容器镜像
mcr.microsoft.com/dotnet/core/sdk:3.1改为mcr.microsoft.com/dotnet/sdk:5.0,mcr.microsoft.com/dotnet/core/aspnet:3.1改为mcr.microsoft.com/dotnet/aspnet:5.0
发布后从第2天上午访问高峰的监控数据看,CPU消耗降了10%,效果不错。
轻松升级,提前享受 .NET 5.0 的性能提升,印象中这是我们在 .NET Core 大版本升级历史中最惬意的一次。
下午我们带着升级后的喜悦心情欢迎新人的加入,现在能够遇到有兴趣学习 .NET 的新人也是不容易的,好了,现在可以直接学 .NET 5.0 了。就在新人欢迎会期间,网站出现了故障,昨晚升级到 .NET 5.0,今天下午就出故障,最大的嫌疑对象显然是 .NET 5.0,当机立断地进行回退操作,如果回退到升级之前的版本能恢复正常,那 .NET 5.0 就罪责难逃。
用下面的脚本在k8s集群上将部署回退到升级之前的容器镜像
./deploy-blog.sh 2.3.73
回退完成之后,很快恢复正常,铁证如山,随后我们立即发博宣判——博客系统升级到 .NET 5.0 引发的故障,让还未正式出茅庐的 .NET 5.0 就背上一口沉重的锅。
幸好有开发同事没有这么片面地看待问题,对故障进行了进一步分析,发现故障与 memcached 服务器的 tcp 连接数异常高有关,大量的数据库连接超时是因为连不上 memcached (达到了1万的最大连接数限制)造成大量请求直接访问数据库引起的。更进一步地,还找到了重现问题的方法,多次点击某些博客,就能让 memcached tcp 连接数飙升,排查后发现这些博客需要被缓存的数据超过了1M,超出了 memcached 单个缓存项的大小限制(默认就是1M),造成数据永远无法被缓存,但每次都要徒劳地读写 memcached 服务器。我们针对这个问题进行了修复,修复后重新发布了 .NET 5.0 版,观察几天后没有再次出现故障。
我们错怪了 .NET 5.0,我们的一时武断让 .NET 5.0 在即将出道之前先背锅,我们向 .NET 5.0 说抱歉,向被误导的 .NET 开发者说抱歉,我们会吸取教训,在故障发生后不要急于发博文,先全面分析问题,不能因为我们的一时误判产生误导。
虽然修复了问题,用上了 .NET 5.0,但问题背后的真正原因至今没有弄明白——仅仅几次鼠标点击,缓存数据超过1M,就能让 memcached 服务器的 tcp 连接数飙升?可能与我们使用的 memcached 客户端 EnyimMemcachedCore,待以后再找时间研究。
今天在写这篇博文的期间,再次遇到这个故障,看来有缘分,想躲也躲不过去了。今天发生故障与访问高峰发布有关,但之前我们评估过访问高峰发布的影响,也就5-10分钟左右访问速度变慢,不会产生如此大的重创。这次故障与上次是同样的表现,memcached tcp 连接数异常高,频频达到1万的最大连接数限制,打开网页速度慢就是因为在等待与 memcached 服务器建立 tcp 连接,重启 memcaced 服务器也于事无补,很快就会再次飙升至1万,平时访问高峰也就5000左右的连接。
从 memcached 服务器的其他指标看,虽然上万的 tcp 连接,但并没有不堪重负,难道仅仅是车多路窄造成的堵车引起大家都通行缓慢?那把路拓宽不就行了,于是将 memcached 服务器的 tcp 最大连接数限制由1万拓宽到2万,本担心连接数会飙升到2万,但没想到竟然恢复正常了。可能是某种特殊情况造成需要稍过万的 tcp 连接,但最大连接数限制把大家都堵住了,看来代码世界也最怕堵车。
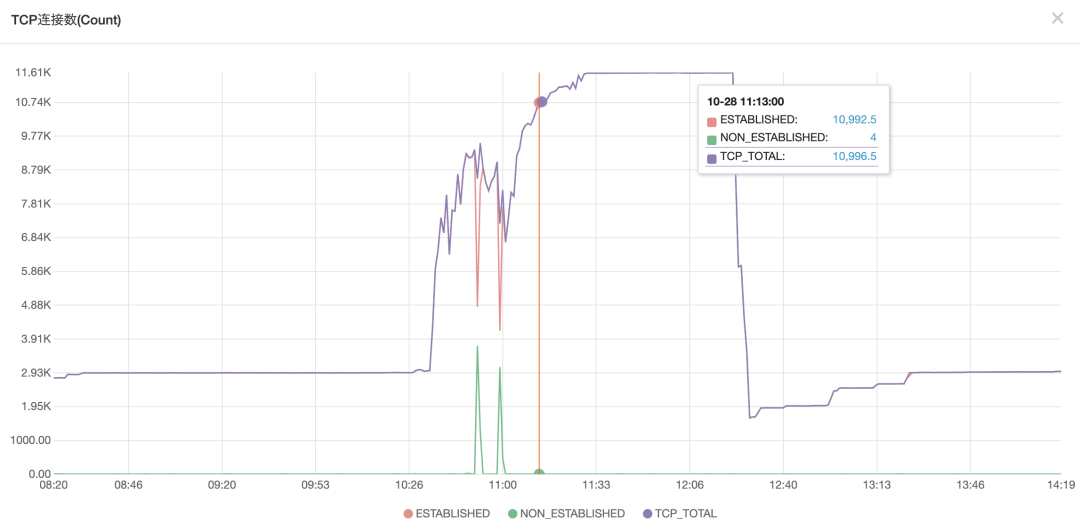
今天集中3个多小时的时间才完成这篇粗糙的博文,在故障后分享一篇博文也不是一件容易的事。