
GitHub 3.1K,语音合成|语音识别|声纹识别一次性全开源!
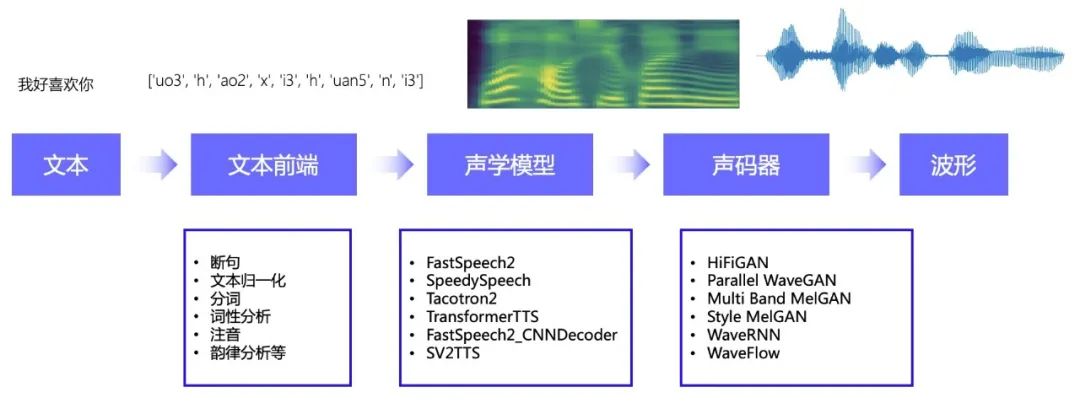
智能语音技术已经在生活中随处可见,常见的智能应用助手、语音播报、近年来火热的虚拟数字人,这些都有着智能语音技术的身影。智能语音是由语音识别,语音合成,自然语言处理等诸多技术组成的综合型技术,对开发者要求高,一直是企业应用的难点。
飞桨语音模型库 PaddleSpeech ,为开发者提供了语音识别、语音合成、声纹识别、声音分类等多种语音处理能力,代码全部开源,各类服务一键部署,并附带保姆级教学文档,让开发者轻松搞定产业级应用!
全新发布 PP-TTS :业界首个开源端到端流式语音合成系统,支持流式声学模型与流式声码器,开源一键式流式语音合成服务部署方案。
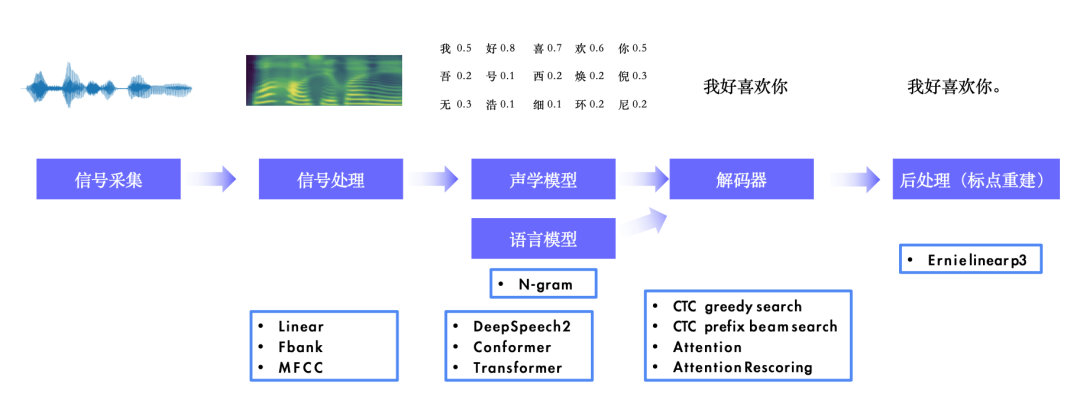
全新发布 PP-ASR :开源基于上万小时数据的流式语音识别系统,开源一键式流式语音识别服务部署方案。支持 Language Model 解码和个性化语音识别。 全新发布 PP-VPR :开源全链路声纹提取与检索系统,10分钟轻松搭建产业级系统。 一键服务化能力:语音识别、语音合成、声纹识别、声音分类、标点恢复,一键部署五项核心语音服务。
以下为本次发布内容详细解读。
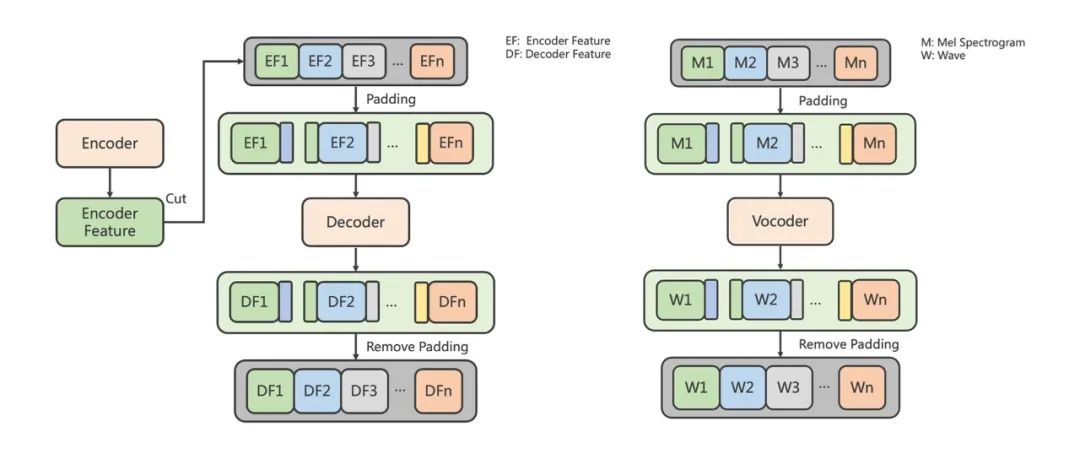
流式推理结构,降低平均响应时延
PP-TTS 的流式语音合成可以在保证合成质量的前提下,大幅降低平均响应时延:
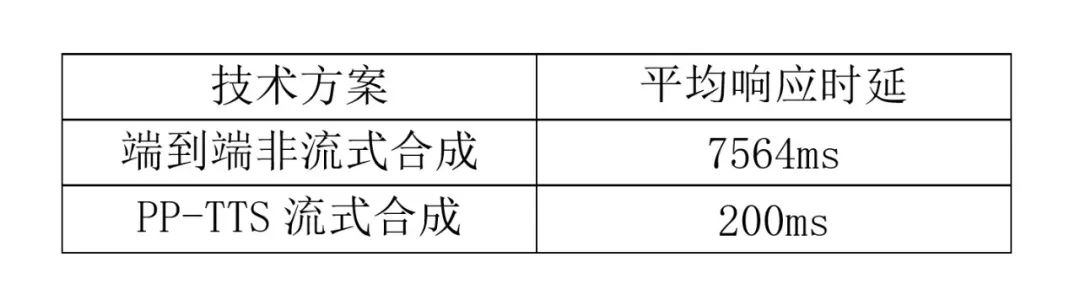
测试环境:测试用例为 CSMSC 数据集后100条, CPU 为 Intel(R) Core(TM) i5-8250U CPU @ 1.60GHz
文本前端优化
PP-TTS 提供了针对中文场景的语音合成文本前端优化方案:针对时间、日期、电话、温度等常见非标准词进行了文本正则化处理;开源了针对中文场景的轻声变调、三声变调和“一”“不”变调等字音转换( G2P )解决方案。在自建的文本正则化测试集上, CER 低至0.73%;以 CSMSC 数据集的拼音标注为 Ground Truth ,字音转换( G2P )的 WER 低至 2.6%。

基于 PP-TTS 优越的文本前端优化,语音合成的输出可以像真人一样自然、优雅,举个例子大家体验一下:


测试数据集:Conformer 模型,测试数据集为 AIShell-1 ,流式识别分块长度为 640ms , GPU: Tesla V100-SXM2-32GB,CPU:80 Core Intel(R) Xeon(R) Gold 6271C CPU@ 2.60GHz
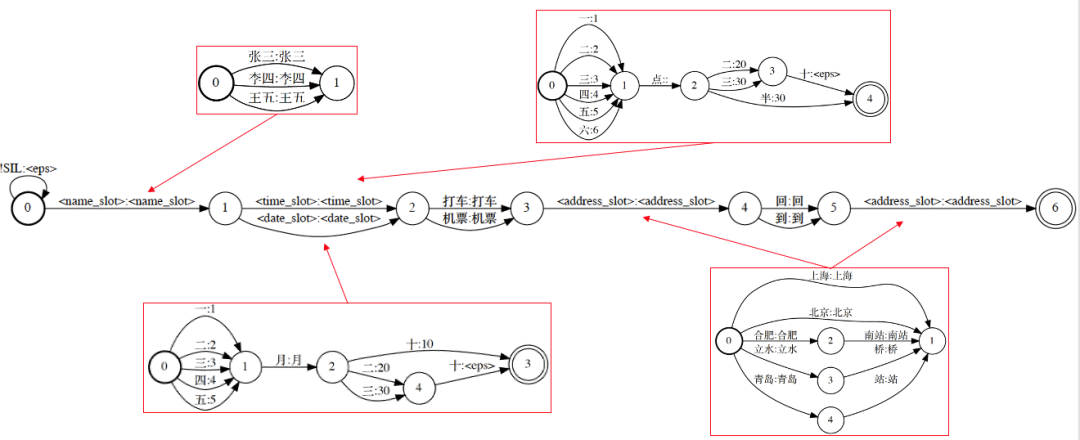
个性化识别方案
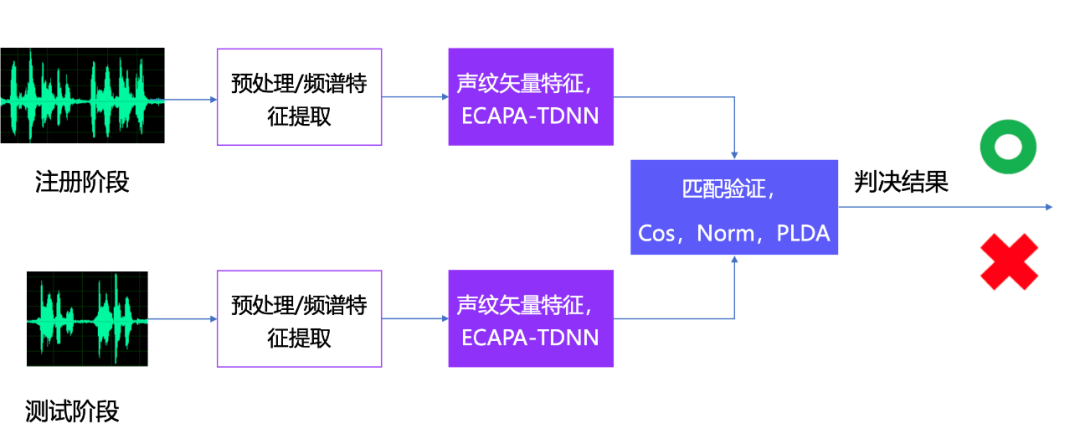
全链路声纹识别与音频检索系统
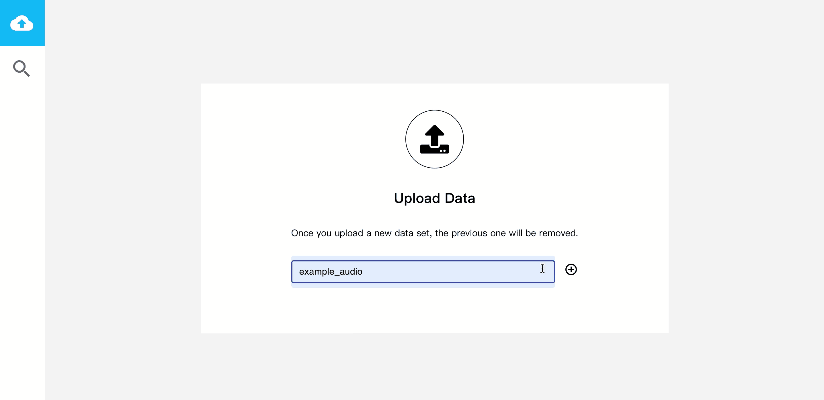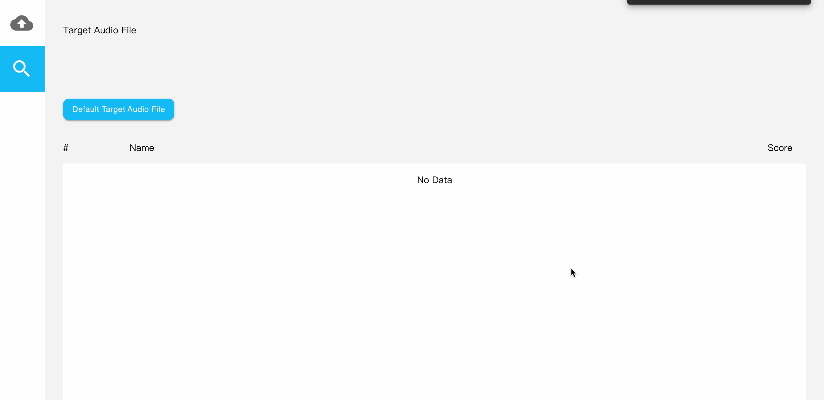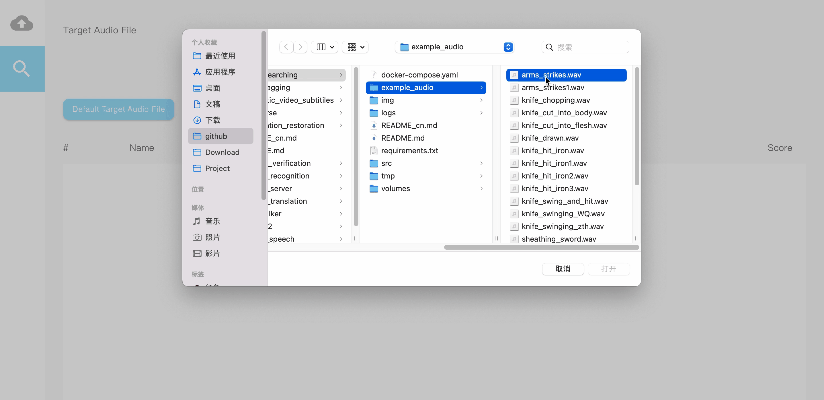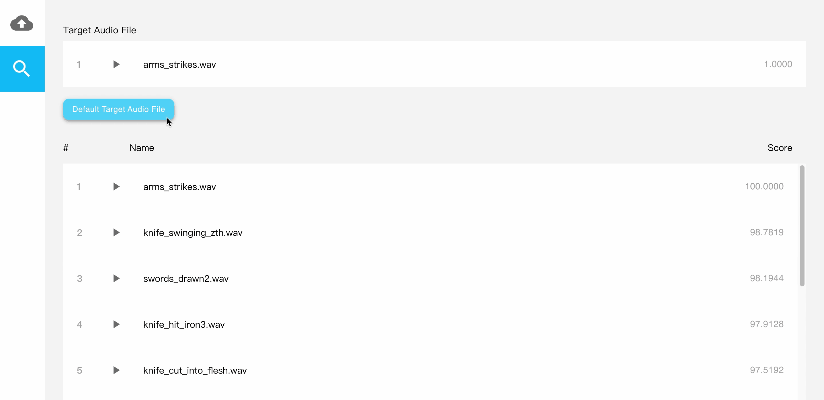
Demo使用及展示
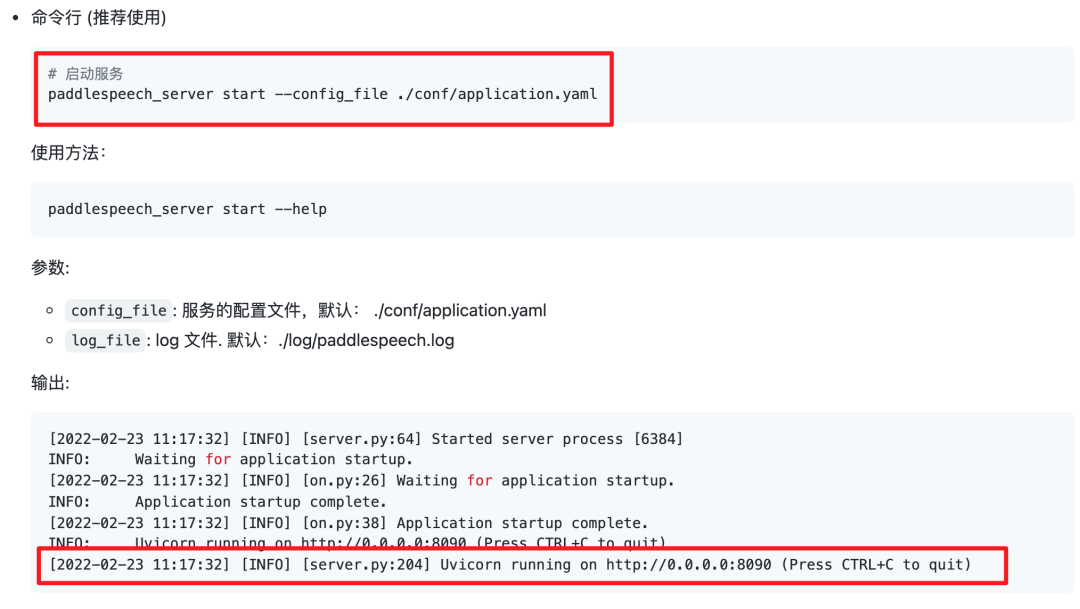
此时服务已经挂载到了配置的8090端口了,我们可以通过命令行对服务进行调用。
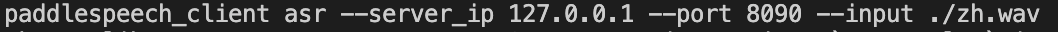


直播课预告

入群福利
获取 PaddleSpeech 团队整理的接近20G重磅学习大礼包
获取5月25-27日直播课程链接

更多开发者应用案例
智能语音工单报销
(基于 PaddleSpeech 和 PaddleNLP )
虚拟数字人
