
slimxml 编码错误排查
缘起
前一段时间,同事遇到一个配置文件读取错误问题,让我帮忙看看。最开始不相信这么基础的功能会有问题。排查完发现,确实是一个字符编码转换方面的 bug,而且只有特定字符会有问题。一起来看看吧。
简化问题
为了使问题简化,我把配置文件内容改成了下面这样,只有一条记录。
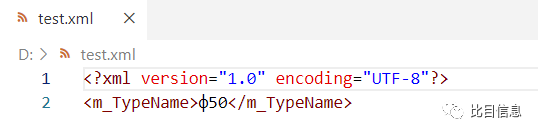
尝试重现
网上找到 slimxml 源码,编译,运行。
说明: 这个
xml库是非常古老的一个库了。不建议使用。
加载上面的 xml。查看结果,果然与预期的不一致。配置文件里的字符是 φ,用 utf8 编码存储的。对应的字节流是 cf 86。
加载到内存中后,使用 unicode 存储的,对应的字节流是 cf 00。
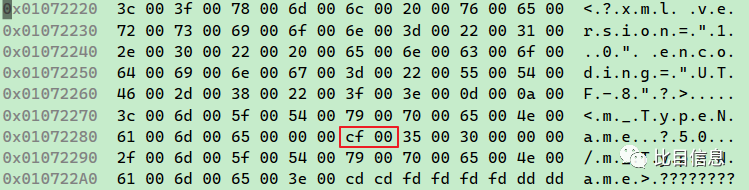
而 φ 在 utf16 编码下对应的字节流应该是 c6 03 (小端字节序)。

编码转换的bug?
配置文件里是使用 utf8 保存的,加载到内存中后变成了 unicode 的,加载过程中一定发生了编码转换。难道是转换过程中发生了错误?单步跟踪 slimxml 加载文件的过程。很快就找到了关键函数—— utf8toutf16()。简单跟踪后,发现下面的处理代码有些问题,
else if ((*u8 & 0xe0) == 0xc0)
{
if (size < 2)
{
break;
}
*(u16++) = (*u8 & 0x1f) | ((*(u8+1) & 0x3f) << 5); // <-- something wrong
u8 += 2;
size -= 2;
++converted;
}
于是,网上找了一段 utf8 转 utf16 的代码,替换上面的处理,替换后的代码如下:
else if ((*u8 & 0xe0) == 0xc0)
{
if (size < 2)
{
break;
}
*u16 = (*u8 & 0x1F) << 6;
*u16 |= (*(u8 + 1) & 0x3F);
u16++;
u8 += 2;
size -= 2;
++converted;
}
再次运行,发现效果正常。
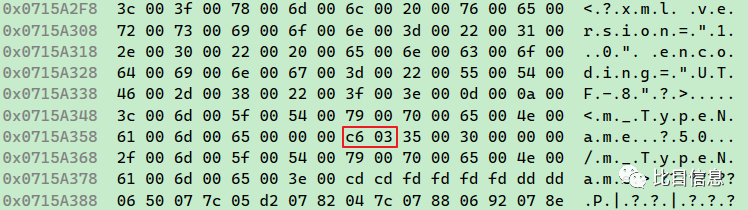
总结
本次排查非常顺利,一是因为目标比较明确,二是因为在整个排查过程中,我清楚的知道每一步的正确结果是什么。字符编码是每个程序员的基本功,一定要熟练掌握。本文的参考资料中包含了非常给力的在线编码转换工具,非常值得收藏。
参考资料
https://www.tamasoft.co.jp/en/general-info/unicode.html
https://code.google.com/archive/p/slimxml/downloads
https://onlineunicodetools.com/convert-unicode-to-utf8
https://onlineunicodetools.com/convert-unicode-to-utf16
https://www.browserling.com/tools/utf8-encode
https://www.browserling.com/tools/utf8-decode
https://gist.github.com/rechardchen/3321830