
【React】1260- 聊聊我眼中的 React Hooks
时至 2022 年年初,React Hooks 已在 React 生态中大放异彩,席卷了几乎所有的 React 应用。而其又与 Function Component 以及 Fiber 架构几近天作之合,在当下,我们好像毫无拒绝它的道理。
诚然,Hooks 解决了 React Mixins 这个老大难的问题,但从它各种奇怪的使用体验上来说,我认为现阶段的 Hooks 并不是一个好的抽象。
红脸太常见,也来唱个黑脸,本文将站在一个「挑刺儿」的视角,聊聊我眼中的 React Hooks ~
「奇怪的」规矩
React 官方制定了一些 Hooks 书写规范用来规避 Bug,但这也恰恰暴露了它存在的问题。
命名
Hooks 并非普通函数,我们一般用use开头命名,以便与其他函数区分。
但相应地,这也破坏了函数命名的语义。固定的use前缀使 Hooks 很难命名,你既为useGetState这样的命名感到困惑,也无法理解useTitle到底是怎么个use法儿。
相比较而言,以_开头的私有成员变量和$尾缀的流,则没有类似的困扰。当然,这只是使用习惯上的差异,并不是什么大问题。
调用时序
在使用useState的时候,你有没有过这样的疑惑:useState虽然每次render()都会调用,但却可以为我保持住 State,如果我写了很多个,那它怎么知道我想要的是什么 State 呢?
const [name, setName] = useState('xiaoming')
console.log('some sentences')
const [age, setAge] = useState(18)
两次useState只有参数上的区别,而且也没有语义上的区分(我们仅仅是给返回值赋予了语义),站在 useState的视角,React 怎么知道我什么时候想要name而什么时候又想要age的呢?
以上面的示例代码来看,为什么第 1 行的useState会返回字符串name,而第 3 行会返回数字age呢? 毕竟看起来,我们只是「平平无奇」地调用了两次useState而已。答案是「时序」。useState的调用时序决定了结果,也就是,第一次的useState「保存」了 name的状态,而第二次「保存」了age的状态。
// Class Component 中通过字面量声明与更新 State,无一致性问题
this.setState({
name: 'xiaoming', // State 字面量 `name`,`age`
age: 18,
})
React 简单粗暴地用「时序」决定了这一切(背后的数据结构是链表),这也导致 Hooks 对调用时序的严格要求。也就是要避免所有的分支结构,不能让 Hooks 「时有时无」。
// ❌ 典型错误
if (some) {
const [name, setName] = useState('xiaoming')
}
这种要求完全依赖开发者的经验抑或是 Lint,而站在一般第三方 Lib 的角度看,这种要求调用时序的 API 设计是极为罕见的,非常反直觉。
最理想的 API 封装应当是给开发者认知负担最小的。好比封装一个纯函数add(),不论开发者是在什么环境调用、在多么深的层级调用、用什么样的调用时序,只要传入的参数符合要求,它就可以正常运作,简单而纯粹。
function add(a: number, b: number) {
return a + b
}
function outer() {
const m = 123;
setTimeout(() => {
request('xx').then((n) => {
const result = add(m, n) // 符合直觉的调用:无环境要求
})
}, 1e3)
}
可以说「React 确实没办法让 Hooks 不要求环境」,但也不能否认这种方式的怪异。
类似的情况在redux-saga里也有,开发者很容易写出下面这种「符合直觉」的代码,而且怎么也「看」不出有问题。
import { call } from 'redux-saga/effects'
function* fetch() {
setTimeout(function* () {
const user = yield call(fetchUser)
console.log('hi', user) // 不会执行到这儿
}, 1e3)
}
yield call()在 Generator 里调用,看起来真的很「合理」。但实际上,function*需要 Generator 执行环境,而call也需要redux-saga的执行环境。双重要求之下,实例代码自然无法正常运行。
useRef 的「排除万难」
从本义上来说,useRef其实是 Class Component 时代React.createRef()的等价替代。
官方文档中最开始的示例代码可以佐证这一点(如下所示,有删减):
function TextInputWithFocusButton() {
const inputEl = useRef(null);
return (
type="text" />
);
}
但因为其实现特殊,也常作他用。
React Hooks 源码中,useRef仅在 Mount 时期初始化对象,而 Update 时期返回 Mount 时期的结果(memoizedState)。这意味着一次完整的生命周期中,useRef保留的引用始终不会改变。
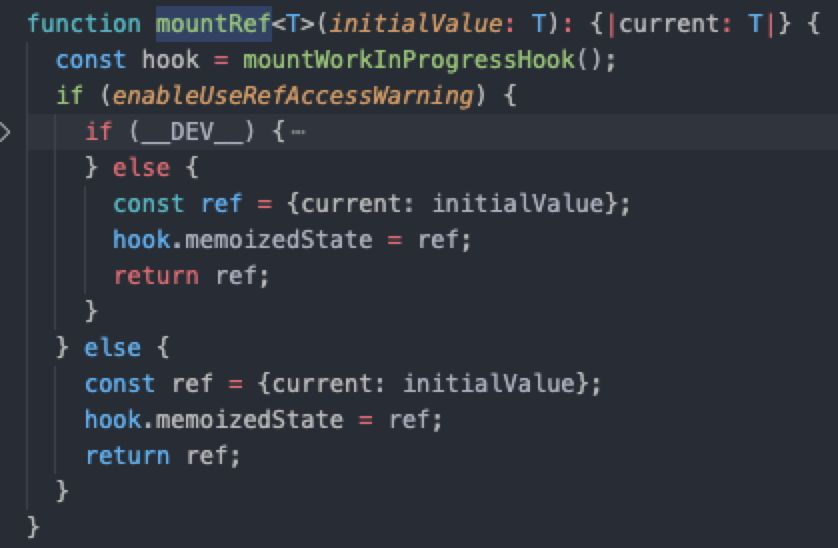

而这一特点却让它成为了 Hooks 闭包救星。
「遇事不决,useRef !」(useRef存在许多滥用的情况,本文不多赘述)
每一个 Function 的执行都有与之相应的 Scope,对于面向对象来说,this引用即是连接了所有 Scope 的 Context(当然前提是在同一个 Class 下)。
class Runner {
runCount = 0
run() {
console.log('run')
this.runCount += 1
}
xrun() {
this.run()
this.run()
this.run()
}
output() {
this.xrun()
// 即便是「间接调用」`run`,这里「仍然」能获取 `run` 的执行信息
console.log(this.runCount) // 3
}
}
在 React Hooks 中,每一次的 Render 由彼时的 State 决定,Render 完成 Context 即刷新。优雅的 UI 渲染,干净而利落。
但useRef多少违背了设计者的初衷, useRef可以横跨多次 Render 生成的 Scope,它能保留下已执行的渲染逻辑,却也能使已渲染的 Context 得不到释放,威力无穷却也作恶多端。
而如果说 this引用是面向对象中最主要的副作用,那么 useRef亦同。从这一点来说,拥有 useRef写法的 Function Component 注定难以达成「函数式」。
有缺陷的生命周期
构造时
Class Component 和 Function Component 之间还有一个很大的「Bug」,Class Component 仅实例化一次后续仅执行render() ,而 Function Component 却是在不断执行自身。
这导致 Function Component 相较 Class Component 实际缺失了对应的constructor构造时。当然如果你有办法只让 Function 里的某段逻辑只执行一遍,倒是也可以模拟出constructor。
// 比如使用 useRef 来构造
function useConstructor(callback) {
const init = useRef(true)
if (init.current) {
callback()
init.current = false
}
}
生命周期而言, constructor 不能类同 useEffect ,如果实际节点渲染时长较长,二者会有很大时差。
也就是说,Class Component 和 Function Component 的生命周期 API 并不能完全一一对应,这是一个很引发错误的地方。
设计混乱的 useEffect
在了解useEffect的基本用法后,加上对其字面意思的理解(监听副作用),你会误以为它等同于 Watcher。
useEffect(() => {
// watch 到 `a` 的变化
doSomething4A()
}, [a])
但很快你就会发现不对劲,如果变量a未能触发 re-render,监听并不会生效。也就是说,实际还是应该用于监听 State 的变化,即useStateEffect。但参数deps却并未限制仅输入 State。如果不是为了某些特殊动作,很难不让人认为是设计缺陷。
const [a] = useState(0)
const [b] = useState(0)
useEffect(() => {
// 假定此处为 `a` 的监听
}, [a])
useEffect(() => {
// 假定此处为 `b` 的监听
// 实际即便 `b` 未变化也并未监听 `a`,但此处仍然因为会因为 `a` 变化而执行
}, [b, Date.now()]) // 因为 Date.now() 每次都是新的值
useStateEffect的理解也并不到位,因为useEffect实际还负责了 Mount 的监听,你需要用「空依赖」来区分 Mount 和 Update。
useEffect(onMount, [])
单一 API 支持的能力越多,也意味着其设计越混乱。复杂的功能不仅考验开发者的记忆,也难于理解,更容易因错误理解而引发故障。
useCallback
性能问题?
在 Class Component 中我们常常把函数绑在this上,保持其的唯一引用,以减少子组件不必要的重渲染。
class App {
constructor() {
// 方法一
this.onClick = this.onClick.bind(this)
}
onClick() {
console.log('I am `onClick`')
}
// 方法二
onChange = () => {}
render() {
return (
)
}
}
在 Function Component 中对应的方案即useCallback :
// ✅ 有效优化
function App() {
const onClick = useCallback(() => {
console.log('I am `onClick`')
}, [])
return (
}
// ❌ 错误示范,`onClick` 在每次 Render 中都是全新的, 会因此重渲染
function App() {
// ... some states
const onClick = () => {
console.log('I am `onClick`')
}
return (
}
useCallback可以在多次重渲染中仍然保持函数的引用, 第2行的onClick也始终是同一个,从而避免了子组件的重渲染。
useCallback源码其实也很简单:

Mount 时期仅保存 callback 及其依赖数组
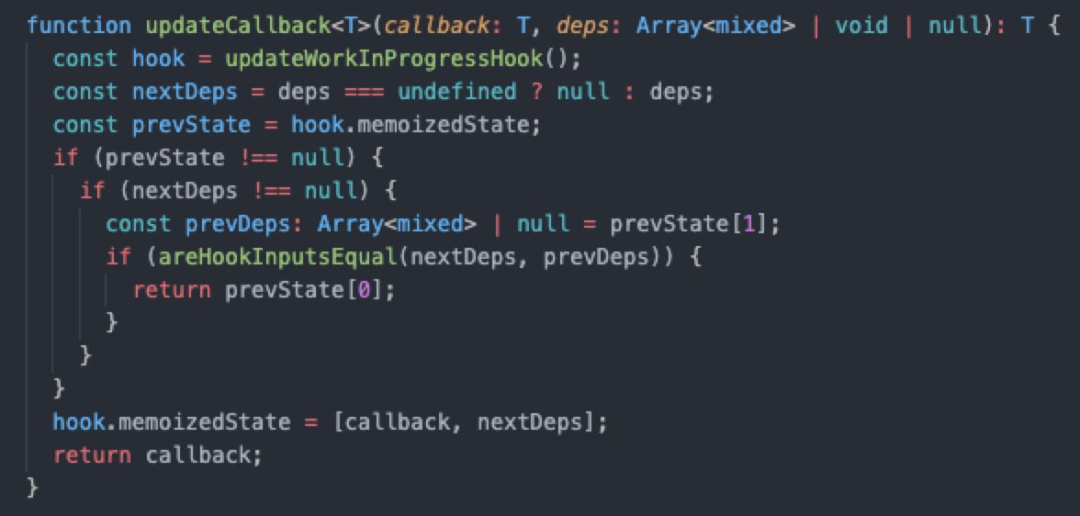
Update 时期判断如果依赖数组一致,则返回上次的 callback
顺便再看看useMemo的实现,其实它与 useCallback 的区别仅仅是多一步 Invoke:
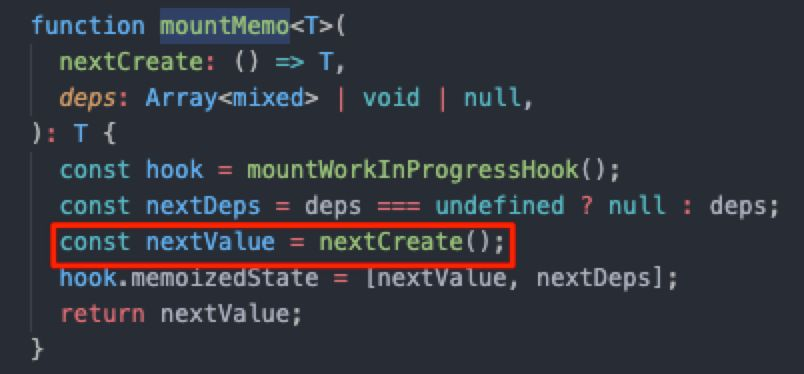
无限套娃✓
相比较未使用useCallback带来的性能问题,真正麻烦的是useCallback带来的引用依赖问题。
// 当你决定引入 `useCallback` 来解决重复渲染问题
function App() {
// 请求 A 所需要的参数
const [a1, setA1] = useState('')
const [a2, setA2] = useState('')
// 请求 B 所需要的参数
const [b1, setB1] = useState('')
const [b2, setB2] = useState('')
// 请求 A,并处理返回结果
const reqA = useCallback(() => {
requestA(a1, a2)
}, [a1, a2])
// 请求 A、B,并处理返回结果
const reqB = useCallback(() => {
reqA() // `reqA`的引用始终是最开始的那个,
requestB(b1, b2) // 当`a1`,`a2`变化后`reqB`中的`reqA`其实是过时的。
}, [b1, b2]) // 当然,把`reqA`加到`reqB`的依赖数组里不就好了?
// 但你在调用`reqA`这个函数的时候,
// 你怎么知道「应该」要加到依赖数组里呢?
return (
<>
)
}
从上面示例可以看到,当useCallback之前存在依赖关系时,它们的引用维护也变得复杂。调用某个函数时要小心翼翼,你需要考虑它有没有引用过时的问题,如有遗漏又没有将其加入依赖数组,就会产生 Bug。
Use-Universal
Hooks 百花齐放的时期诞生了许多工具库,仅ahooks就有 62 个自定义 Hooks,真可谓「万物皆可 use」~ 真的有必要封装这么多 Hooks 吗?又或者说我们真的需要这么多 Hooks 吗?
合理封装?
尽管在 React 文档中,官方也建议封装自定义 Hooks 提高逻辑的复用性。但我觉得这也要看情况,并不是所有的生命周期都有必要封装成 Hooks。
// 1. 封装前
function App() {
useEffect(() => { // `useEffect` 参数不能是 async function
(async () => {
await Promise.all([fetchA(), fetchB()])
await postC()
})()
}, [])
return (123)
}
// --------------------------------------------------
// 2. 自定义 Hooks
function App() {
useABC()
return (123)
}
function useABC() {
useEffect(() => {
(async () => {
await Promise.all([fetchA(), fetchB()])
await postC()
})()
}, [])
}
// --------------------------------------------------
// 3. 传统封装
function App() {
useEffect(() => {
requestABC()
}, [])
return (123)
}
async function requestABC() {
await Promise.all([fetchA(), fetchB()])
await postC()
}
在上面的代码中,对生命周期中的逻辑封装为 HookuseABC反而使其耦合了生命周期回调,降低了复用性。即便我们的封装中不包含任何 Hooks,在调用时也仅仅是包一层useEffect而已,不算费事,而且让这段逻辑也可以在 Hooks 以外的地方使用。
如果自定义 Hooks 中使用到的useEffect和useState总次数不超过 2 次,真的应该想一想这个 Hook 的必要性了,是否可以不封装。
简单来说,Hook 要么「挂靠生命周期」要么「处理 State」,否则就没必要。
重复调用
Hook 调用很「反直觉」的就是它会随重渲染而不停调用,这要求 Hook 开发者要对这种反复调用有一定预期。
正如上文示例,对请求的封装,很容易依赖useEffect,毕竟挂靠了生命周期就能确定请求不会反复调。
function useFetchUser(userInfo) {
const [user, setUser] = useState(null)
useEffect(() => {
fetch(userInfo).then(setUser)
}, [])
return user
}
但,useEffect真的合适吗?这个时机如果是DidMount,那执行的时机还是比较晚的,毕竟如果渲染结构复杂、层级过深,DidMount就会很迟。
比如,ul中渲染了 2000 个 li:
function App() {
const start = Date.now()
useEffect(() => {
console.log('elapsed:', Date.now() - start, 'ms')
}, [])
return (
{Array.from({ length: 2e3 }).map((_, i) => ({i}))}
)
}
// output
// elapsed: 242 ms
那不挂靠生命周期,而使用状态驱动呢?似乎是个好主意,如果状态有变更,就重新获取数据,好像很合理。
useEffect(() => {
fetch(userInfo).then(setUser)
}, [userInfo]) // 请求参数变化时,重新获取数据
但初次执行时机仍然不理想,还是在DidMount。
let start = 0
let f = false
function App() {
const [id, setId] = useState('123')
const renderStart = Date.now()
useEffect(() => {
const now = Date.now()
console.log('elapsed from start:', now - start, 'ms')
console.log('elapsed from render:', now - renderStart, 'ms')
}, [id]) // 此处监听 `id` 的变化
if (!f) {
f = true
start = Date.now()
setTimeout(() => {
setId('456')
}, 10)
}
return null
}
// output
// elapsed from start: 57 ms
// elapsed from render: 57 ms
// elapsed from start: 67 ms
// elapsed from render: 1 ms
这也是上文为什么说useEffect设计混乱,你把它当做 State Watcher 的时候,其实它还暗含了「初次执行在DidMount」的逻辑。从字面意思Effect来看,这个逻辑才是副作用吧。。。
状态驱动的封装除了调用时机以外,其实还有别的问题:
function App() {
const user = useFetchUser({ // 乍一看似乎没什么问题
name: 'zhang',
age: 20,
})
return ({user?.name})
}
实际上,组件重渲染会导致请求入参重新计算 -> 字面量声明的对象每次都是全新的 -> useFetchUser因此不停请求 -> 请求变更了 Hook 内的 State user -> 外层组件
这是一个死循环!
当然,你可以用Immutable来解决同一参数重复请求的问题。
useEffect(() => {
// xxxx
}, [ Immutable.Map(userInfo) ])
但总的看来,封装 Hooks 远远不止是变更了你代码的组织形式而已。比如做数据请求,你可能因此而走上状态驱动的道路,同时,你也要解决状态驱动随之带来的新麻烦。
为了 Mixin ?
其实,Mixin 的能力也并非 Hooks 一家独占,我们完全可以使用 Decorator 封装一套 Mixin 机制。也就是说, Hooks 不能依仗 Mixin 能力去力排众议。
const HelloMixin = {
componentDidMount() {
console.log('Hello,')
}
}
function mixin(Mixin) {
return function (constructor) {
return class extends constructor {
componentDidMount() {
Mixin.componentDidMount()
super.componentDidMount()
}
}
}
}
@mixin(HelloMixin)
class Test extends React.PureComponent {
componentDidMount() {
console.log('I am Test')
}
render() {
return null
}
}
render(
不过 Hooks 的组装能力更强一些,也容易嵌套使用。但需要警惕层数较深的 Hooks,很可能在某个你不知道的角落就潜伏着一个有隐患的useEffect。
小结
本文没有鼓吹 Class Component 拒绝使用 React Hooks 的意思,反而是希望通过细致地比对二者,从而更深入理解 Hooks。 React Hooks 的各种奇怪之处,也正是潜在症结之所在。 在 Hooks 之前,Function Component 都是 Stateless 的,小巧、可靠但功能有限。Hooks 为 Function Component 赋予了 State 能力并提供了生命周期,使 Function Component 的大规模使用成为了可能。 Hooks 的「优雅」来自向函数式的致敬,但useRef的滥用让 Hooks 离「优雅」相去甚远。 大规模实践 React Hooks 仍然有诸多问题,无论是从语义理解抑或是封装的必要性。 创新不易,期待 React 官方之后会有更好的设计吧。