
SHEIN提前批NLP面试题5道|含解析


从GCN的角度就是探索更多的权重矩阵。原文的解释是MultiHead-Attention 提供了多个“表示子空间”,可以使模型在不同位置上关注来自不同“表示子空间”的信息。即通过MultiHead,模型可以捕捉到更加丰富的特征信息。这里的多个表示子空间其实就是GCN里的多个权重矩阵。
问题2:无序数组的中位数
方法一:快排一次后,检查k落在哪个区域,然后对那个区域再进行一次快排。如此反复,可得答案。
方法二:同样使用快排,但是对基准数不再随机,而是尽可能找出让两段区域长度相等的划分。(把原来的数组分成五份,然后找中位数,然后再在这些中位数里找出中位数作为基准)
问题3:一个元素在一个有序数组的第一次出现位置?
要找到一个元素在一个有序数组中第一次出现的位置,你可以使用二分查找算法的变种。
def first_occurrence(arr, target):left, right = 0, len(arr) - 1result = -1 # 初始化结果为-1,表示未找到元素while left <= right:mid = left + (right - left) // 2 # 计算中间索引if arr[mid] == target:result = mid # 找到目标元素,更新结果right = mid - 1 # 继续在左侧查找第一次出现的位置elif arr[mid] < target:left = mid + 1else:right = mid - 1return result# 示例用法arr = [1, 2, 2, 2, 3, 4, 4, 5]target = 2first_index = first_occurrence(arr, target)if first_index != -1:print(f"元素 {target} 第一次出现的位置是 {first_index}")else:print(f"元素 {target} 在数组中未找到")
这段代码首先初始化左右指针,然后在循环中执行二分查找,查找目标元素的第一次出现位置。如果找到了目标元素,则更新结果为中间索引,然后继续在左侧查找以找到第一次出现的位置。如果未找到目标元素,返回结果为-1。
问题4:blip2的架构,优势和之前多模态模型的区别?
blip2是图像-语言多模态模型的预训练方法。这个架构是2023年才提出的,也看出来面试紧跟时事了。
blip2的一个常见模式是输入一张图片,输出这张图片的描述。
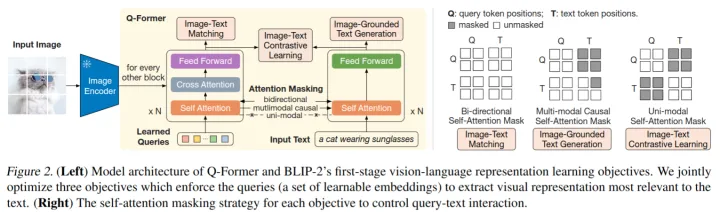
bilp2是在冻结的图像模型(负责从图像中提取特征,比如vit)和冻结的语言模型(负责生成语言)中间放入一个Q-Former,我们的目标就是训练这个Q-Former。Q-Former包含图像Transformer和语言Transformer,图像Transformer包含CA和SA,SA和语言Transformer共享参数,CA只接受图像模型提取的图像特征,图像模型的输入是一个查询值,这个查询值将在SA中和自己交互,在CA中和图像特征交互。最后图像Transformer输出一个综合图像特征的向量,同时语言Transformer输入一个文本,进行encode,得到一个文本的向量。然后根据具体的任务选择不同的方式对这两个向量进行操作。最后,Q-former把得到的向量传给冻结的语言模型。语言Transformer训练的时候做解码器,预测的时候是解码器。
训练的时候先训练Q-Former和图像模型的交互,然后把Q-Former的结果和语言模型连接(中间可以加入全连接,前缀词等操作)。如下图
问题5: 知识蒸馏和无监督样本训练?
知识蒸馏是利用大模型把一个大模型的知识压缩到一个小模型上。具体来说你在一个训练集上得到了一个非常好的较大的模型,
然后你把这个模型冻结,作为Teacher模型也叫监督模型,然后你再造一个较小参数的模型叫做Student模型,我们的目标就是利用冻结的Teacher模型去训练Student模型。
A.离线蒸馏:Student在训练集上的loss和与Teacher模型的loss作为总的loss,一起优化。
B.半监督蒸馏:向Teacher模型输入一些input得到标签,然后把input和标签传给Student模型
还有个自监督蒸馏,直接不要Teacher模型,在最后几轮epoch,把前面训练好的模型作为Teacher进行监督。
目前知识蒸馏的一个常见应用就是对齐ChatGPT。
然后这个无监督样本训练,我看不懂意思。如果是传统的无监督学习,那就是聚类,主成分分析等操作。如果是指知识蒸馏的话,就是离线蒸馏的方式,只不过损失只有和Teacher的loss。
免费送


扫码回复【999】免费领10本电子书
(或找七月在线其他老师领取)
点击“阅读原文”抢宠粉福利~
