
Go:你真的了解 timeout 嘛?
服务为什么需要 timeout 呢?提前释放资源
记得在上家公司时,一个 python 服务与公网交互,request 库发出去的请求没有设置 timeout ... 而且还是个定时任务,占用了超多 fd
同时微服务场景下某下游的服务阻塞卡顿,这样会造成他的级联上下游都雪崩了。
语言层面:对于使用线程池的语言,会消耗所有线程,work 不够用。其实对于 go 来说,创建大量 goroutine 也会有 runtime 开销的, 只是慢性死亡罢了
内核层面:还有一点超时配置的必要性,如果某服务挂了,那么内核会帮忙收尾,根据情况或走 RST 或走 FIN,访问者就知道链接关了。但如果主机挂了,或者中间网络设备挂了,客户端没有超时配置,就只能 tcp keepalive 来判断死链接,按照默认内核配置语言两个多小时。文末提到 redis 就是例子
Latency
业界都用 P99 分位来衡量服务的 latency, 即使这样如果 QPS 非常高,另外 1% 的请求也会出现 long tail. 再来看几个不同侧重点的概念:
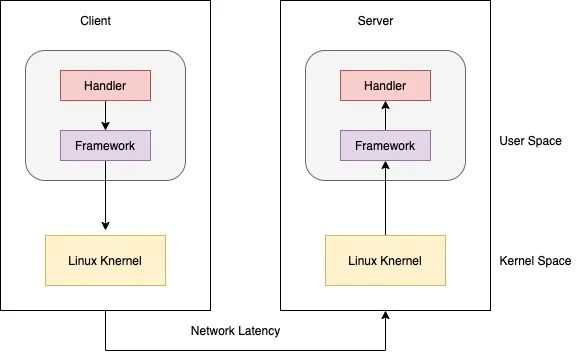
Server Side P99 统计的只是 server handler 处理时间
Client P99 = client framework 时间 + client 内核处理时间 + 网络传输时间 + server 处理时间
当你发现 latency 比较高,想去 challenge 下游时,请对好口径。通常 client p99 > server p99
这还是普通的 server/client 模式,如果中间涉及了 lb, 或是 mesh 排查问题很要命
可观测性
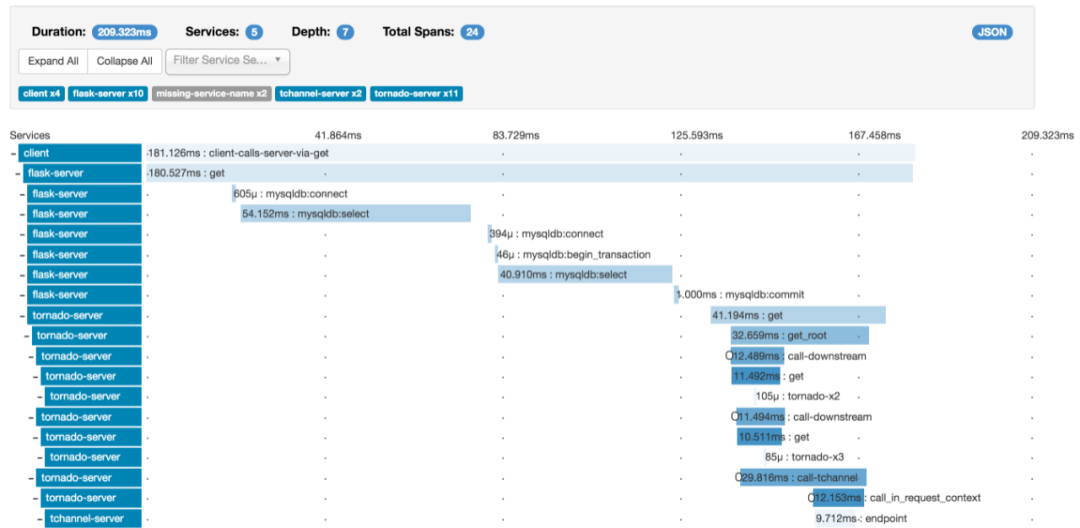
现在都是微服务场景,一个订单全链路涉及几十个服务,查起问题非常困难,所以分布式的 tracing 系统非常重要
另外现在也都拥抱云原生环境,如果引入 service mesh 的话更难以排查问题
一般 tracing 系统都是根据 google 论文 Dapper, a Large-Scale Distributed Systems Tracing Infrastructure[1] 发展而来的
除了自己造轮子,主流的有 zipkin[2], opentelemetry[3]
底层实现
定时器这块业务早有标准实现:小顶堆, 红黑树 和 时间轮. 感兴趣的同学可以搜索相关文章
原理不难,但是有公司面试都要求手写红黑树!!!这就过份了吧
Linux 内核和 Nginx 的定时器采用了 红黑树 实现,好多长连接系统多采用 时间轮
Go 使用 小顶堆, 四叉堆,比较矮胖,不是最朴素的二叉堆。
最早版本只有一个 timer 堆,所以性能非常差,精度也有问题。一般都用户实现多堆,或是用时间轮实现。这方面的轮子比写公众号的码农都多 ^_^
后来经过优化 Go 内置多堆实现,每个 P 一个 timer 堆,性能好了很多。注意,Go 的 conn timeout 是通过用户层 timer 实现的,而不是内核的 setsockopt
HTTP
这里要区分 http1 和 http2, 以前写过一篇 HOL blocking 的文章,感兴趣可以翻下历史
Http1 如果超时到了,那么底层库是要关闭 tcp connection 的,强制丢弃未读到的数据,这时会产生大量的 timewait, 要注意
但是对于 Http2 来说,虚拟出来了 stream, 做到了多路复用,只要关闭 stream 即可,底层 socket 还可以正常使用
对于 go http 还有一个坑,可以参考 i/o timeout , 希望你不要踩到这个net/http包的坑[4]
func init() {
tr = &http.Transport{
MaxIdleConns: 100,
Dial: func(netw, addr string) (net.Conn, error) {
conn, err := net.DialTimeout(netw, addr, time.Second*2) //设置建立连接超时
if err != nil {
return nil, err
}
err = conn.SetDeadline(time.Now().Add(time.Second * 3)) //设置发送接受数据超时
if err != nil {
return nil, err
}
return conn, nil
},
}
}
上面代码是错误使用,这个导致每次 conn 连接后只设置一次超时时间
client := &http.Client{
Transport: tr,
Timeout: 3*time.Second, // 超时加在这里,是每次调用的超时
}
正确的应该在 http.Client 结构体里设置,感兴趣的去参考全文吧
另外服务端也要设置 timeout, 以防把服务端压跨,请参考 So you want to expose Go on the Internet[5]
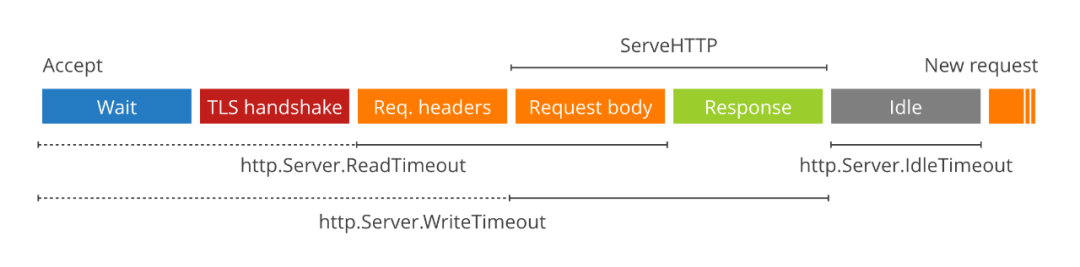
srv := &http.Server{
ReadTimeout: 5 * time.Second,
WriteTimeout: 10 * time.Second,
IdleTimeout: 120 * time.Second,
TLSConfig: tlsConfig,
Handler: serveMux,
}
log.Println(srv.ListenAndServeTLS("", ""))
数据库相关
做为 CRUD Boy, 经常和 DB 打交道,让我们来看下常见的超时设置与坑
Redis 服务端要注意两个参数:timeout 和 tcp-keepalive
其中 timeout 用于关闭 idle client conn, 默认是 0 不关闭,为了减少服务端 fd 占用,建议设置一个合理的值
tcp-keepalive 在很早的 redis 版本是不开启的,这样经常会遇到因为网格抖动等原因,socket conn 一直存在,但实际上 client 早己经不存在的情况
Redis Client 实现有一个重大问题,对于集群环境下,有些请求会做 Redirect 跳转,默认是 16 次,如果 tcp read timeout 设置了 100ms, 那总时间很可能超过了 1s
这就是一直强调的问题,tcp timeout 设置不代表实际的调用时间,因为业务层会多次调用 socket 读写。最好外面包一层 context 或是 circuit breaker
MySQL 也同样服务端可以设置 MAX_EXECUTION_TIME 来控制 sql 执行时间。不同发行版本还不一样,有的只支持 select, 有的同时支持 dml ddl ...
其它
Q: 有同事问 timeout 与 sla 什么关系?
A: 要大于 sla. 没有经过 toB 业务的重锤,感触不深,有朋友了解的可以留言讲讲 toB 业务的玩法
Q: 如何传递 timeout ?
A: 一般都是框架层传递的,比如 grpc 会在 header 里传递服务的 timeout, 每经过一个 backend, 减去相应的耗时
Q: 依赖的下游出现大量超时,应该如何处理?
A: 要做到 fast fail, 一定得有降级 (circuit breaker 熔断)措施,否则会拖垮整条链路。
小结
这次分享就这些,以后面还会分享更多的内容,如果感兴趣,可以关注并点击左下角的分享转发哦(:
参考资料
Dapper, a Large-Scale Distributed Systems Tracing Infrastructure: https://research.google/pubs/pub36356/,
[2]zipkin: https://zipkin.io/,
[3]opentelemetry: https://opentelemetry.io/docs/concepts/distributions/,
[4]i/o timeout , 希望你不要踩到这个net/http包的坑: https://mp.weixin.qq.com/s/UBiZp2Bfs7z1_mJ-JnOT1Q,
[5]So you want to expose Go on the Internet: https://blog.cloudflare.com/exposing-go-on-the-internet/,
推荐阅读