背景是这样的:他用 cp 拷贝了一个 100 G的文件,竟然一秒不到就拷贝完成了!用 ls 看一把文件,显示文件确实是 100 G。
sh-4.4# ls -lh
-rw-r--r-- 1 root root 100G Mar 6 12:22 test.txt
sh-4.4# time cp ./test.txt ./test.txt.cp
real 0m0.107s
user 0m0.008s
sys 0m0.085s
一个 SATA 机械盘的写能力能到 150 M/s (大部分的机械盘都是到不了这个值的)就算非常不错了,正常情况下,copy 一个 100G 的文件至少要 682 秒 ( 100 G/ 150 M/s ),也就是 11 分钟。实际情况却是 cp 一秒没到就完成了工作,惊呆了,为啥呢?更诡异的是:他的文件系统只有 40 G,为啥里面会有一个 100 G的文件呢?我让他先用 du 命令看一下,却只有 2M ,根本不是100G,这是怎么回事?
sh-4.4# du -sh ./test.txt
2.0M ./test.txt
sh-4.4# stat ./test.txt
File: ./test.txt
Size: 107374182400 Blocks: 4096 IO Block: 4096 regular file
Device: 78h/120d Inode: 3148347 Links: 1
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2021-03-13 12:22:00.888871000 +0000
Modify: 2021-03-13 12:22:46.562243000 +0000
Change: 2021-03-13 12:22:46.562243000 +0000
Birth: -
- Size 为 107374182400(知识点:单位是字节),也就是 100G ;
- Blocks 这个指标显示为 4096(知识点:一个 Block 的单位固定是 512 字节,也就是一个扇区的大小),这里表示为 2M;
- Size 表示的是文件大小,这个也是大多数人看到的大小;
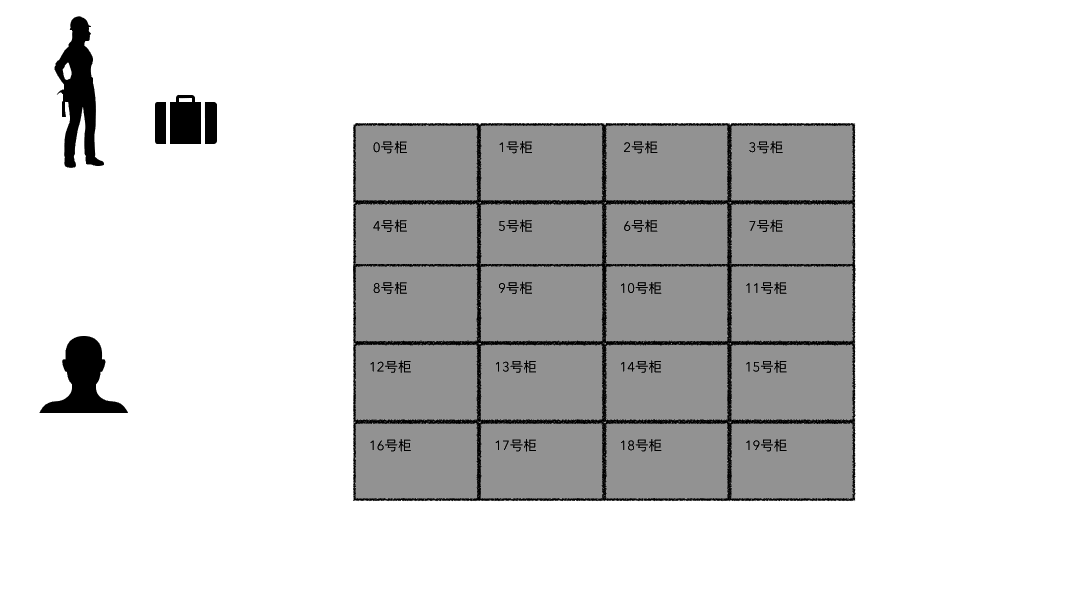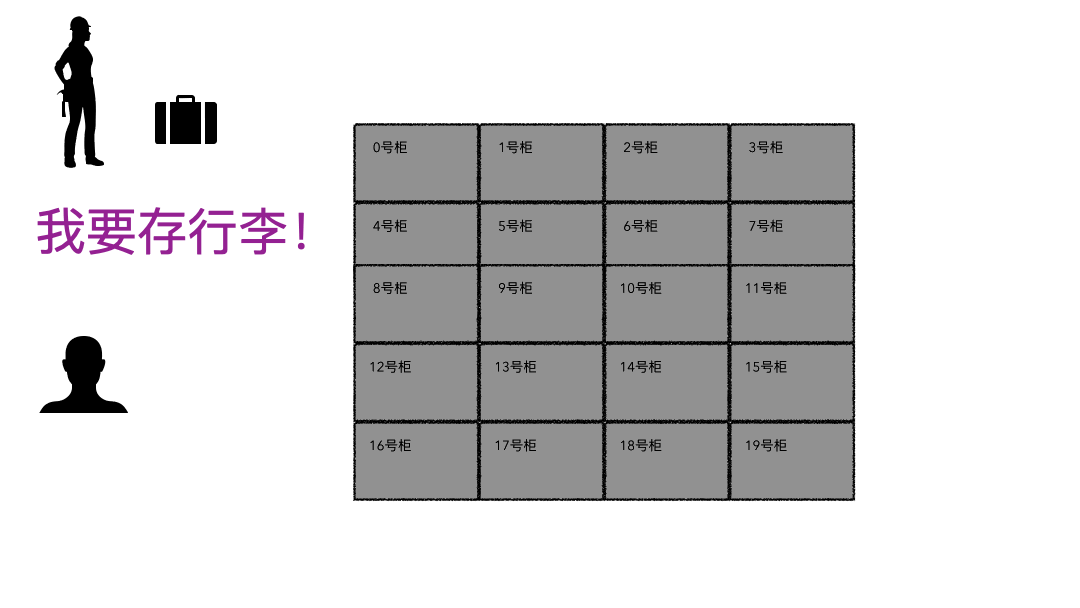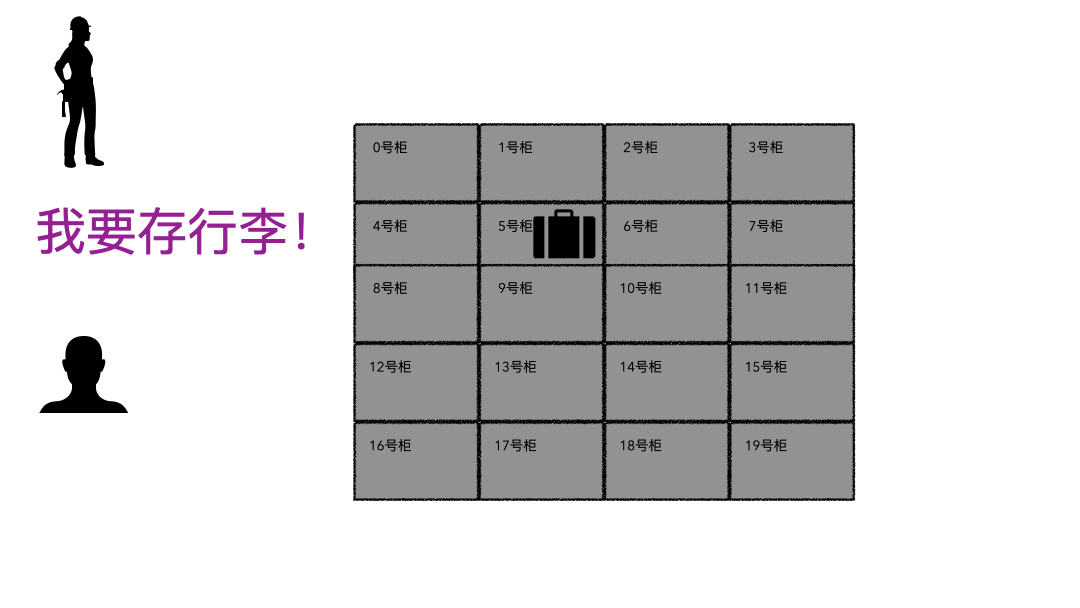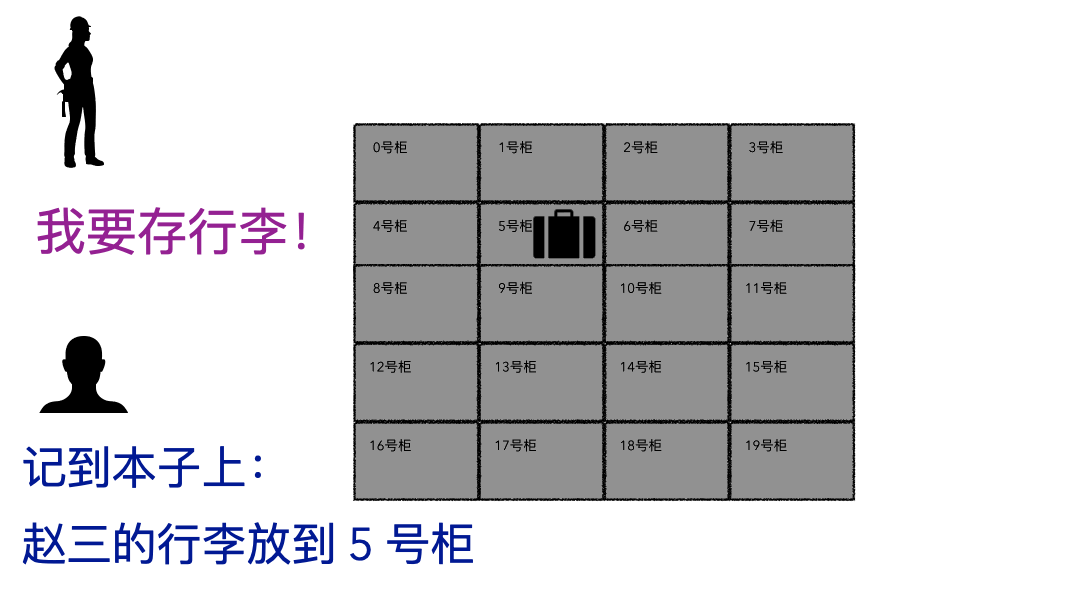
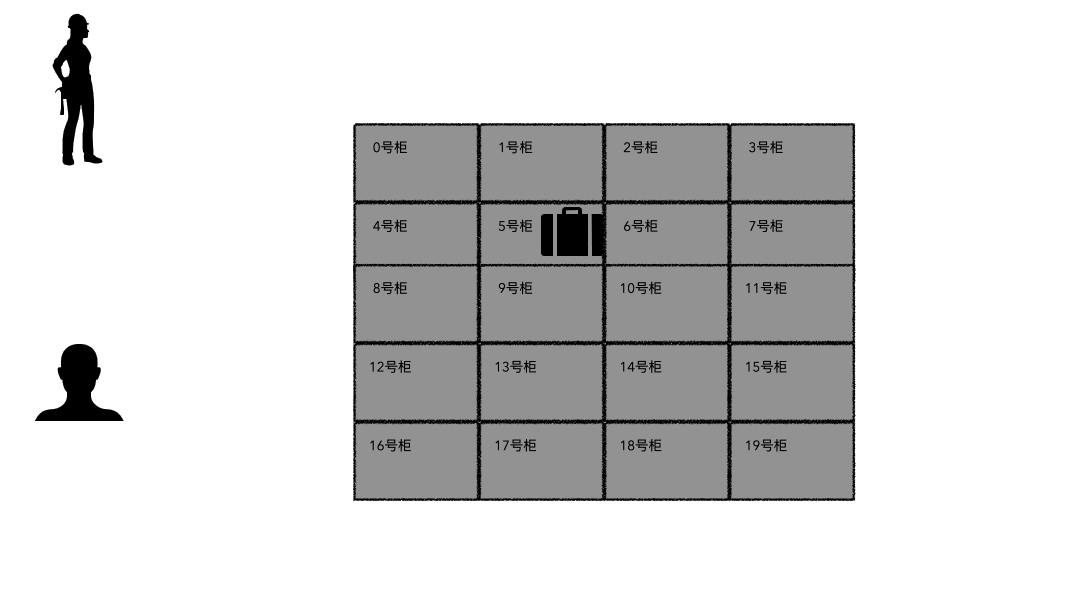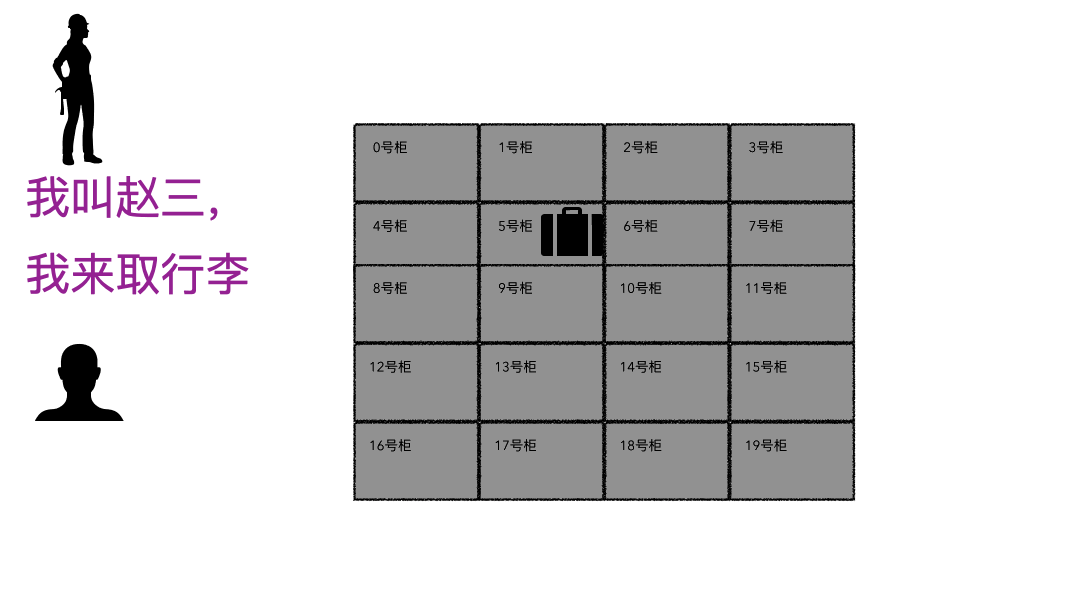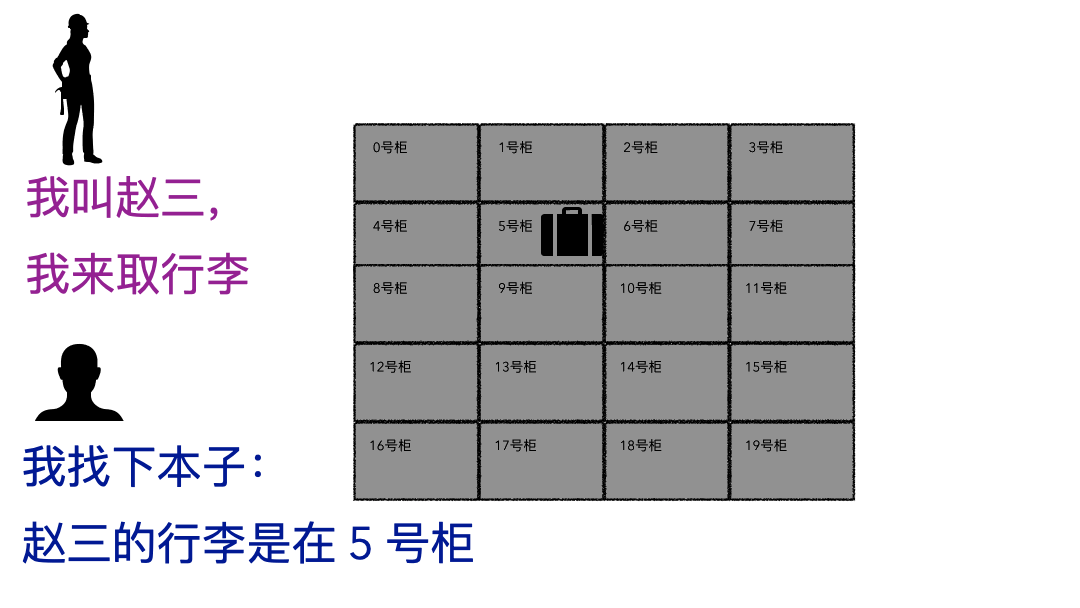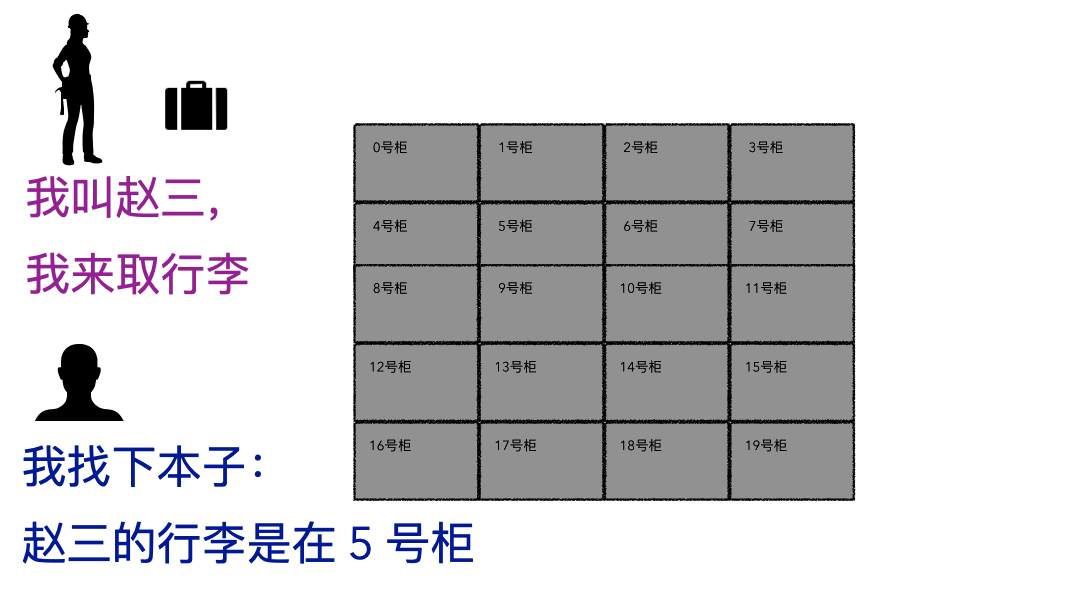
同事问道:“文件大小和实际物理占用,这两个竟然不是相同的概念 !为什么是这样? ” “看来,我们必须得深入文件系统才能理解了,来,我给你好好讲讲。”文件系统听起来很高大上,通俗话就用来存数据的一个容器而已,本质和你的行李箱、仓库没有啥区别,只不过文件系统存储的是数字产品而已。我有一个视频文件,我把这个视频放到这个文件系统里,下次来拿,要能拿到我完整的视频文件数据,这就是文件系统,对外提供的就是存取服务。存行李的时候,是不是要登记一些个人信息?对吧,至少自己名字要写上。可能还会给你一个牌子,让你挂手上,这个东西就是为了标示每一个唯一的行李。取行李的时候,要报自己名字,有牌子的给他牌子,然后工作人员才能去特定的位置找到你的行李划重点:存的时候必须记录一些关键信息(记录ID、给身份牌),取的时候才能正确定位到。回到我们的文件系统,对比上面的行李存取行为,可以做个简单的类比;
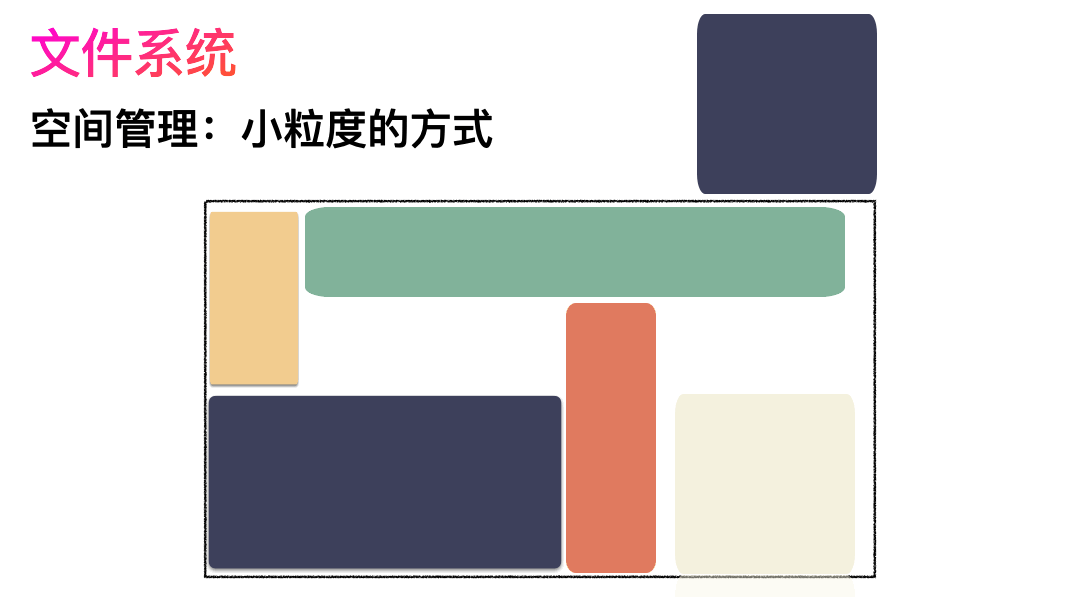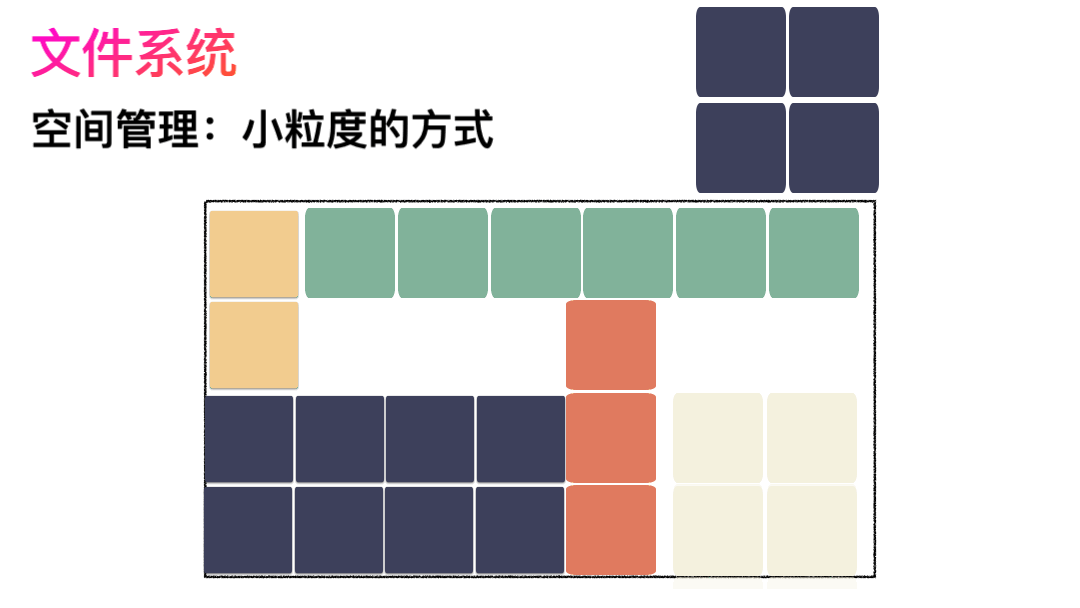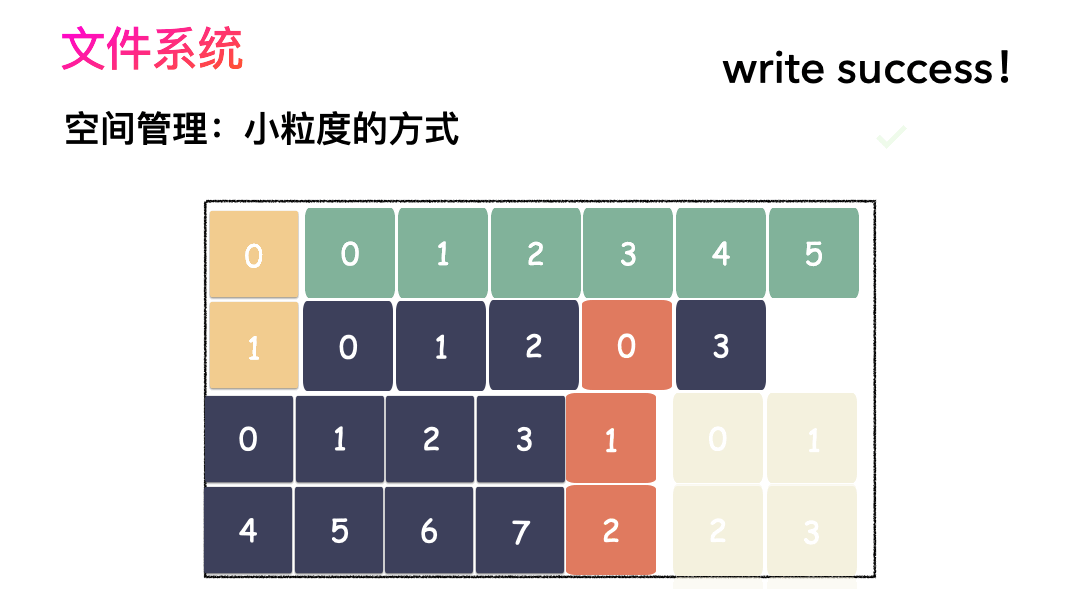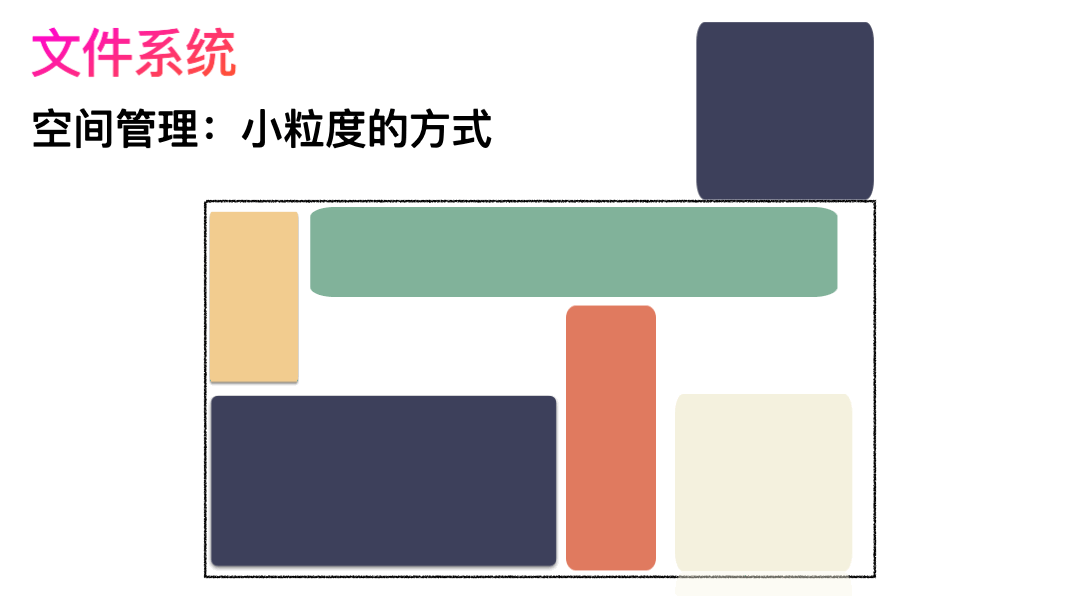
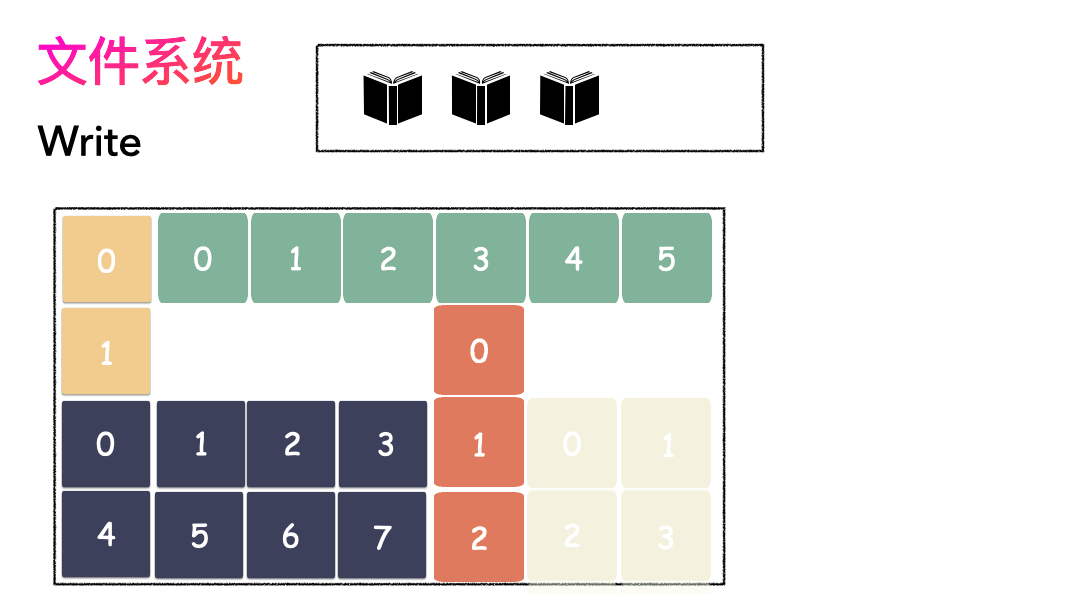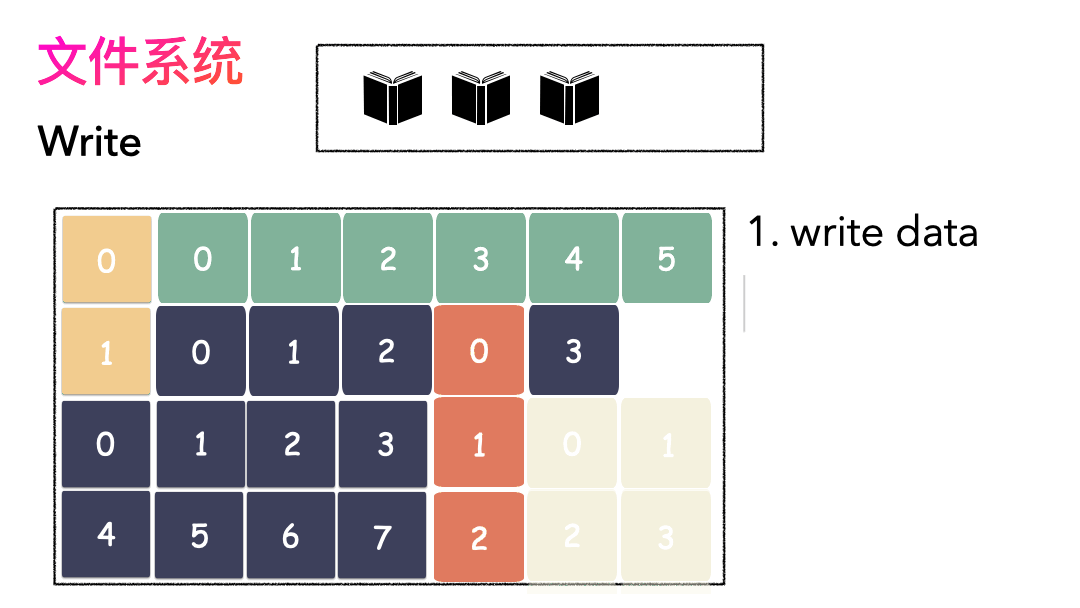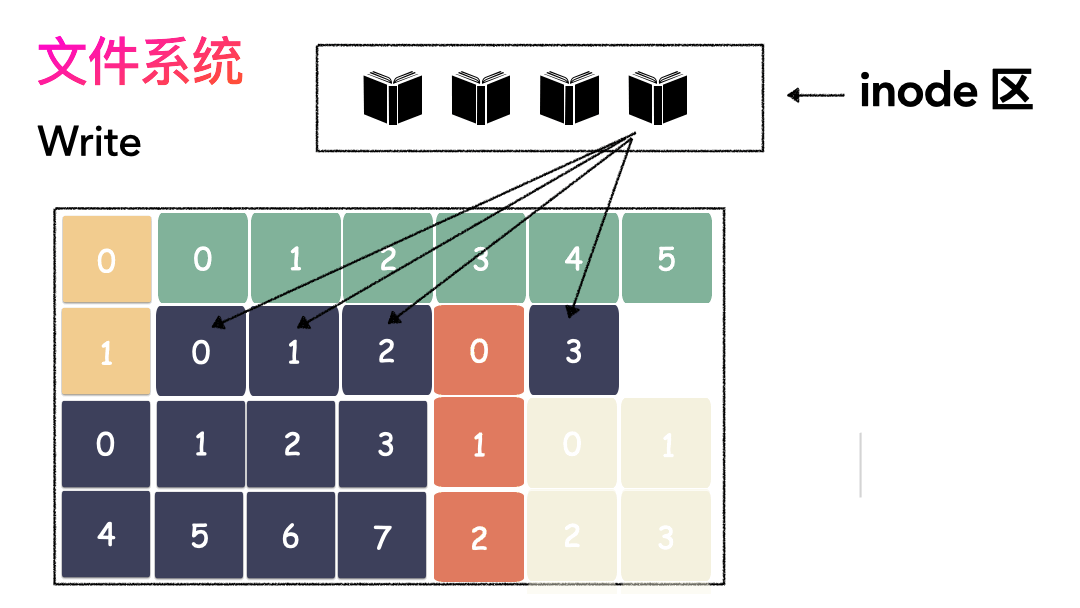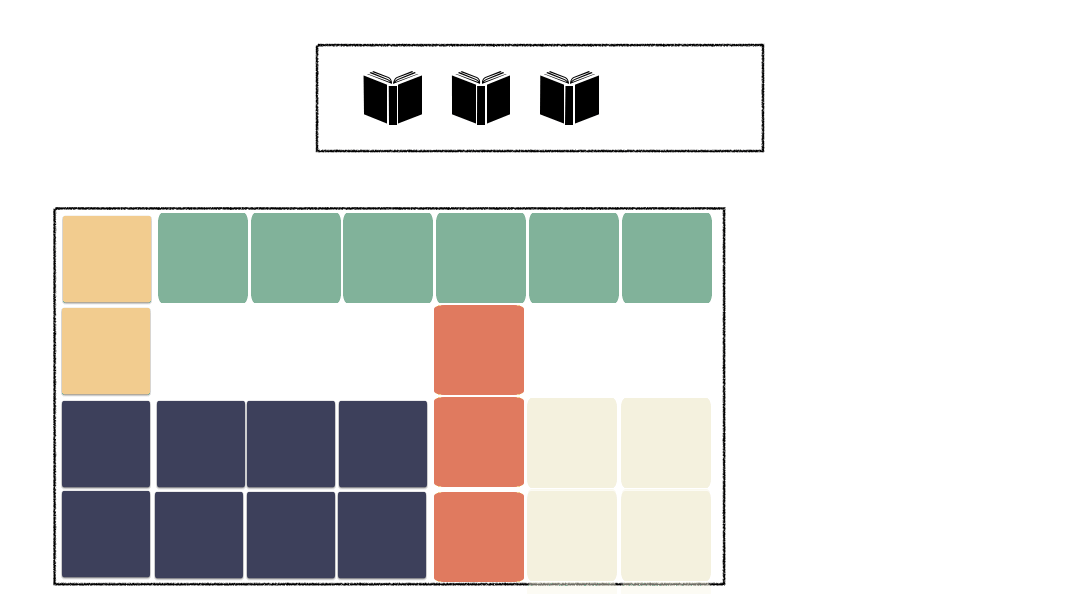
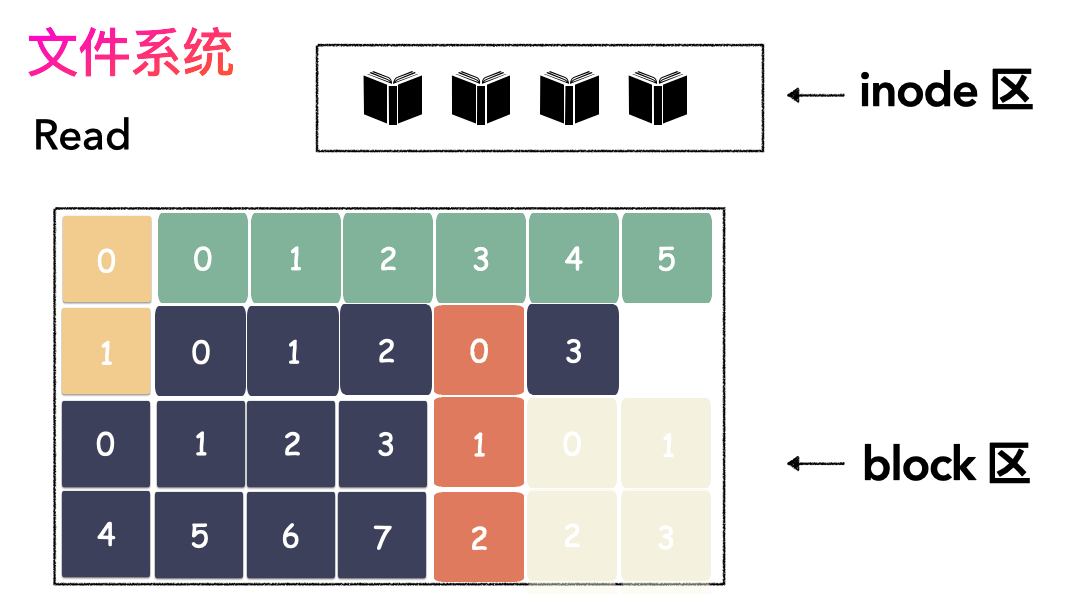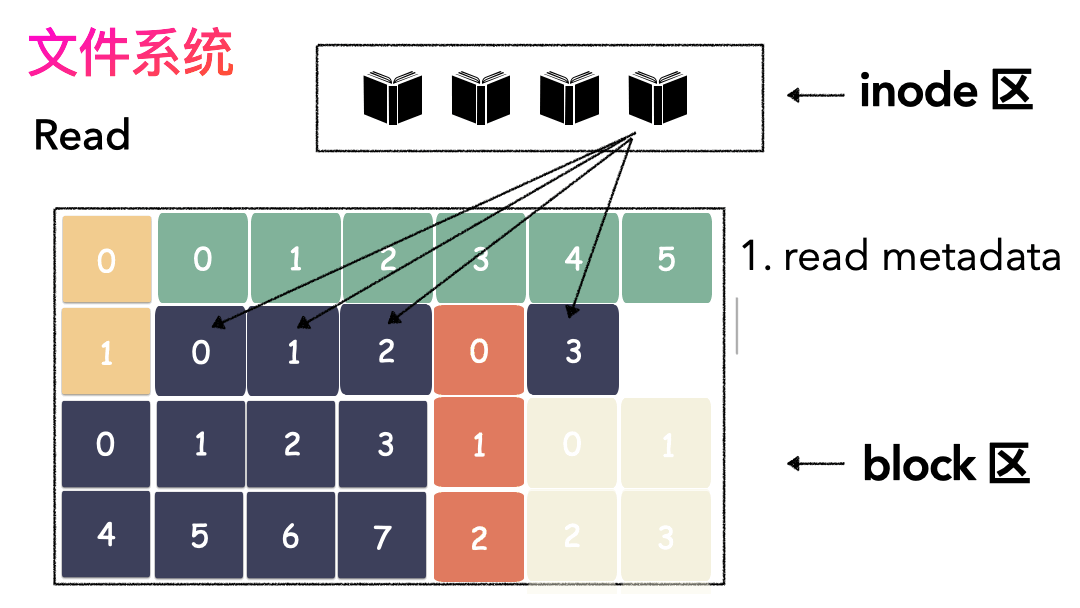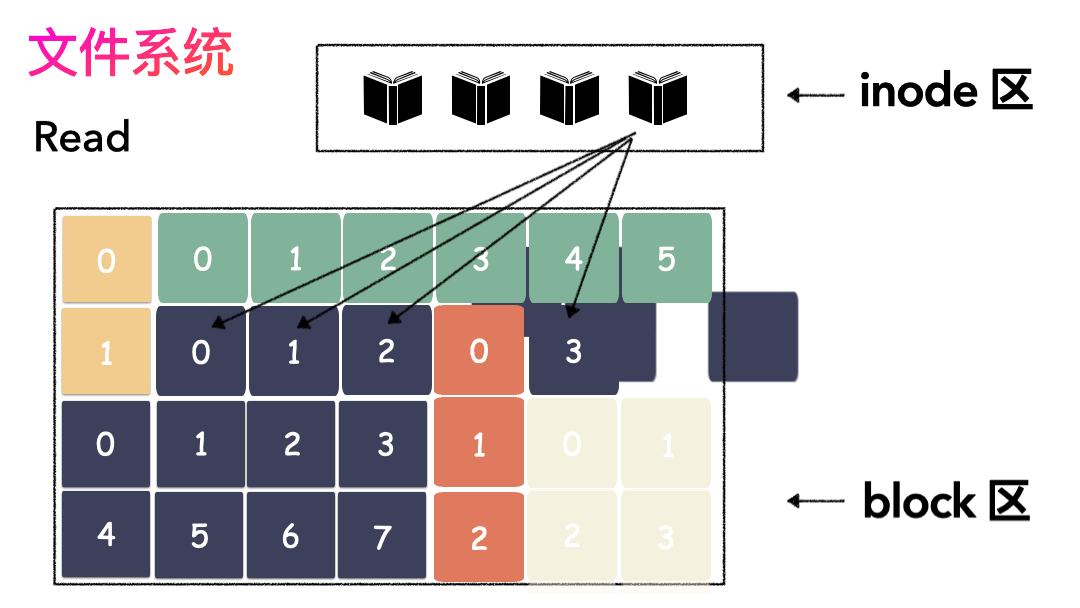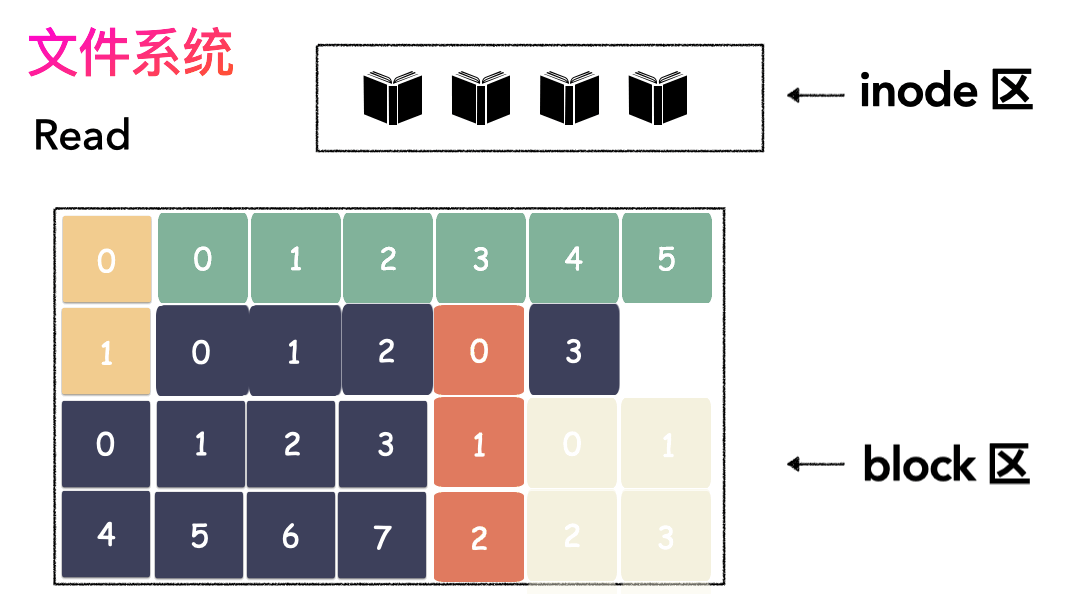
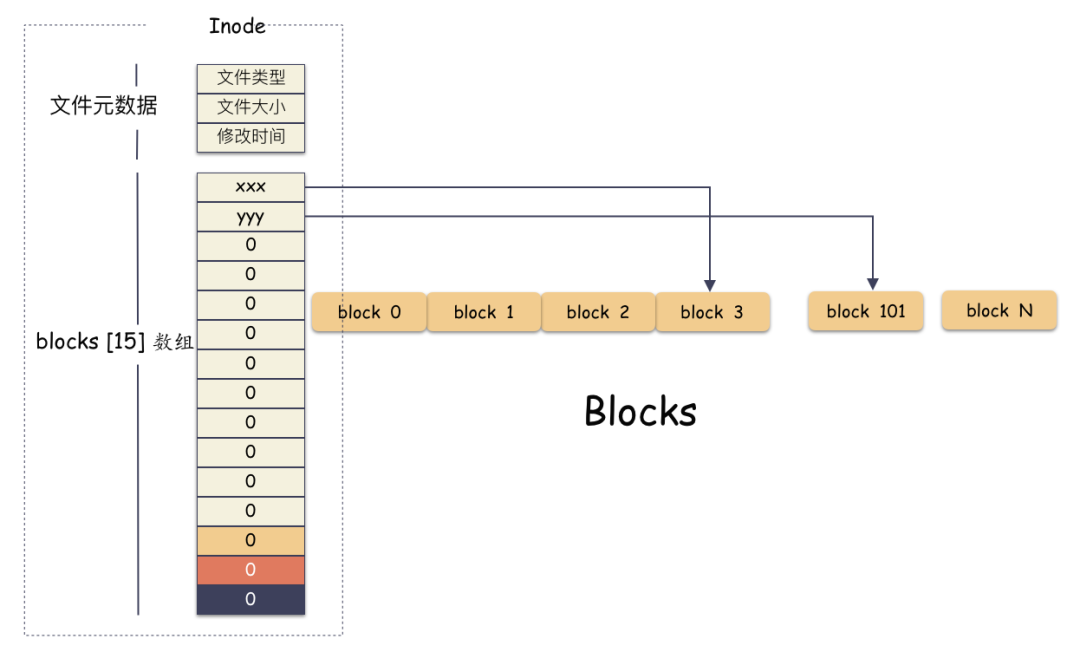
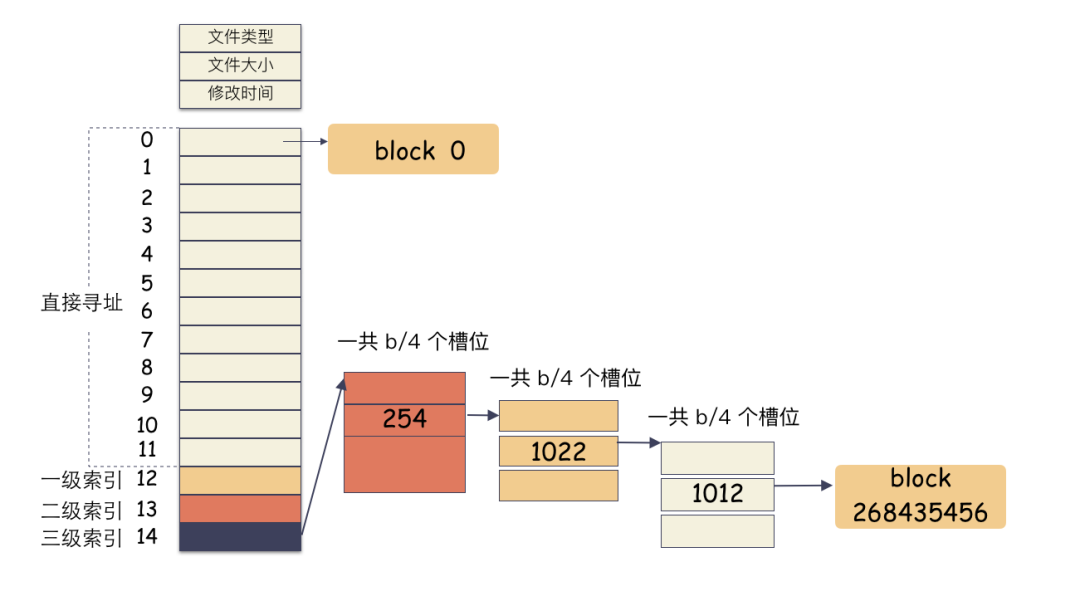
上面的对应并不是非常严谨,仅仅是帮助大家理解文件系统而已,让大家知道其实文件系统是非常朴实的一个东西,思想都来源于生活。如果,一个连续的大磁盘空间给你使用,你会怎么使用这段空间呢?这种方式非常容易实现,属于眼前最简单,以后最麻烦的方式。因为会造成很多空洞,明明还有很多空间位置,但是由于整个太大,形状不合适(数据大小),哪里都放不下。因为你要放一个完整的空间。怎么改进?有人会想,既然整个放不进去,那就剁碎了呗。这里塞一点,那里塞一点,就塞进去了。对,思路完全正确。改进的方式就是切分,把空间按照一定粒度切分。每个小粒度的物理块命名为 Block,每个 Block 一般是 4K 大小,用户数据存到文件系统里来自然也是要切分,存储到磁盘上各个角落。图示标号表示这个完整对象的 Block 的序号,用来复原对象用的。随之而来又有一个问题:你光会切成块还不行,取文件数据的时候,还得把它们给组合起来才行。所以,要有一个表记录文件对应所有 Block 的位置,这个表被文件系统称为inode。
- 先写数据:数据先按照 Block 粒度存储到磁盘的各个位置;
- 再写元数据:然后把 Block 所在的各个位置保存起来,即inode(我用一本书来表示);
这个inode有文件元数据和Block数组(长度是15),数组中前两项指向Block 3和Block 11,表示数据在这两个块中存着。 你肯定会意识到:Block数组只有15个元素,每个Block是4K, 难道一个文件最大只能是 15 * 4K = 60 K ? 最简单的办法就是:把这个Block数组长度给扩大!比如我们想让文件系统最大支持100G的文件,Block数组需要这么长:(100*1024*1024)/4 = 26214400Block数组中每一项是4个字节,那就需要(26214400*4)/1024/1024 = 100M 为了支持100G的文件,我们的Block数组本身就得100M ! 并且对每个文件都是如此 !即使这个文件只有1K! 这将是巨大浪费!肯定不能这么干,解决方案就是间接索引,按照约定,把这 15 个槽位分作 4 个不同类别来用:
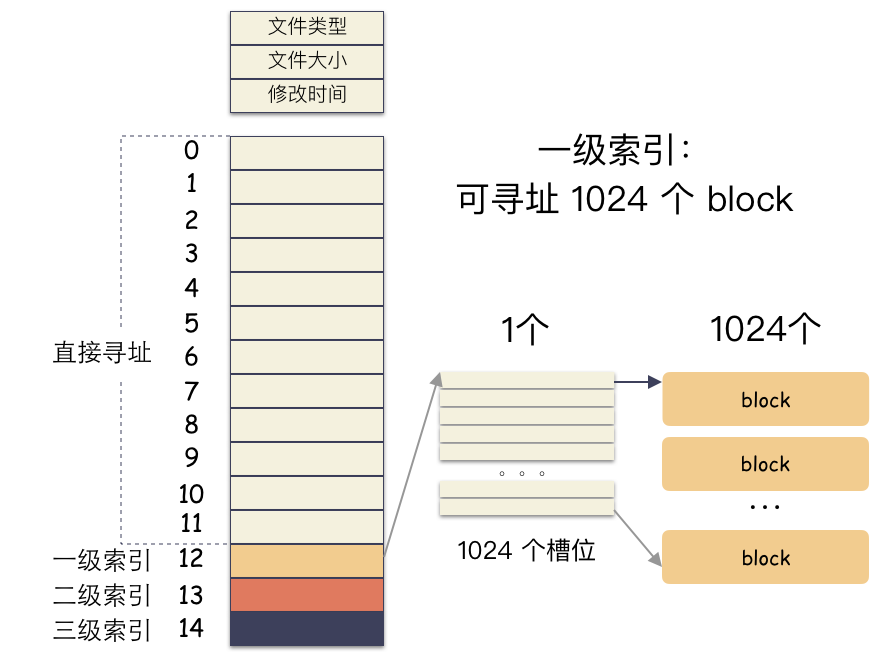
- 前 12 个槽位(也就是 0 - 11 )我们成为直接索引;
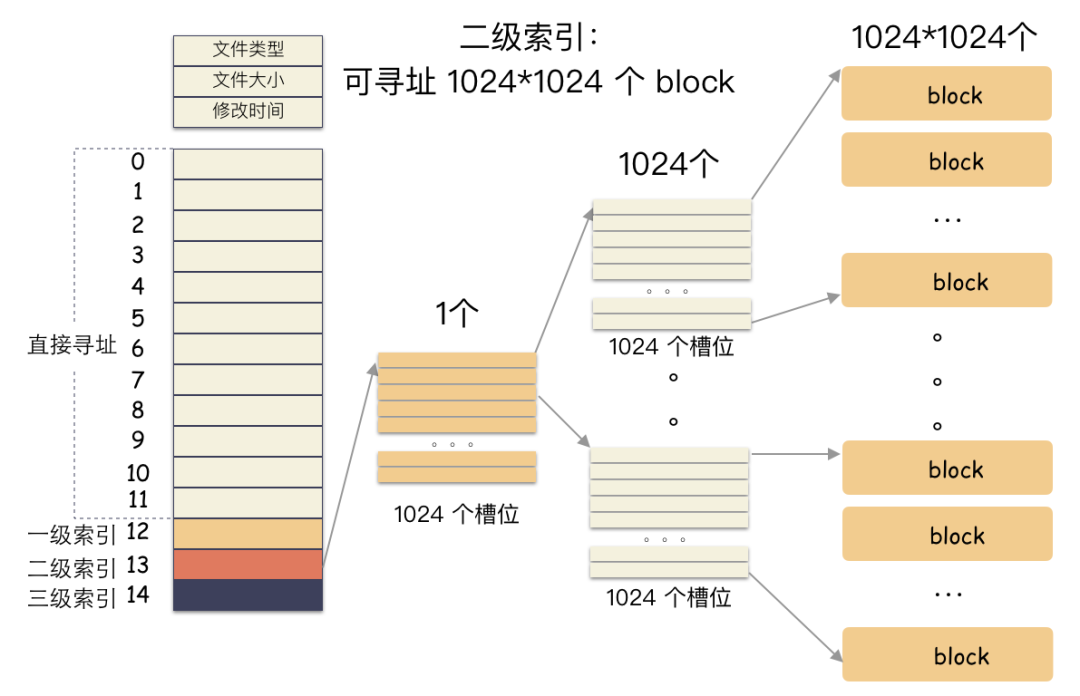
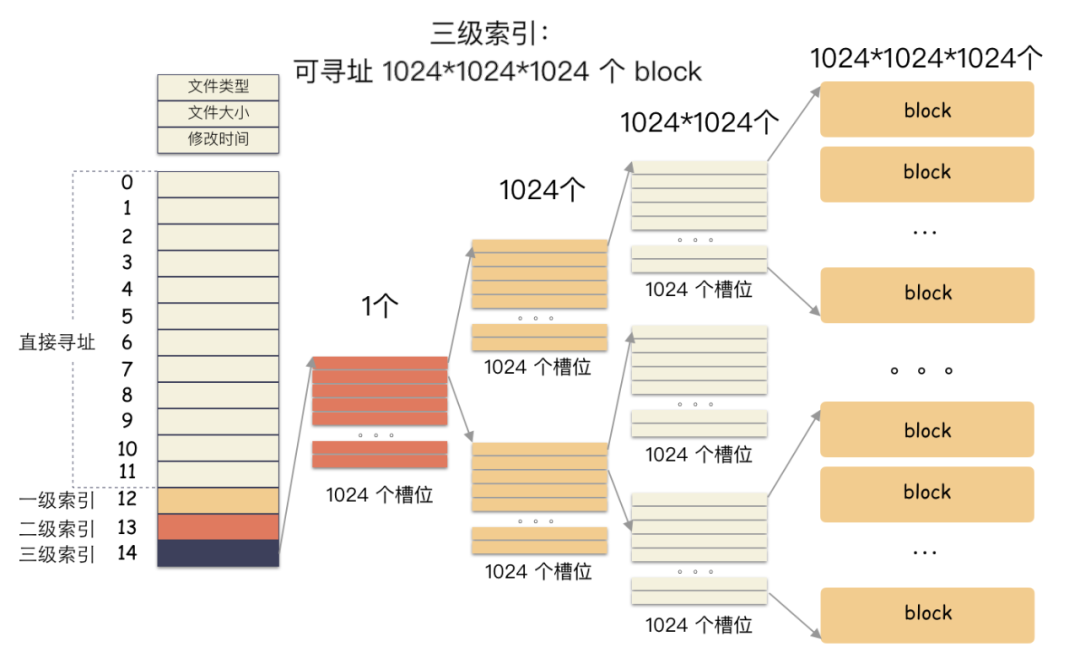
直接索引:能存 12 个 block 编号,每个 block 4K,就是 48K,也就是说,48K 以内的文件,前 12 个槽位存储编号就能完全 hold 住。也就是说这里存储的编号指向的 block 里面存储的也是 block 编号,里面的编号指向用户数据。一个 block 4K,每个元素 4 字节,也就是有 1024 个编号位置可以存储。所以,一级索引能寻址 4M(1024 * 4K)空间 。二级索引是在一级索引的基础上多了一级而已,换算下来,有了 4M 的空间用来存储用户数据的编号。所以二级索引能寻址 4G (4M/4 * 4K) 的空间。三级索引是在二级索引的基础上又多了一级,也就是说,有了 4G 的空间来存储用户数据的 block 编号。所以二级索引能寻址 4T (4G/4 * 4K) 的空间。所以,在这种文件系统(如ext2)上,通过这种间接块索引的方式,最大能支撑的文件大小 = 48K + 4M + 4G + 4T ,约等于 4 T。在不超过 12 个数据块的小文件的寻址是最快的,访问文件中的任意数据理论只需要两次读盘,一次读 inode,一次读数据块。访问大文件中的数据则需要最多五次读盘操作:inode、一级间接寻址块、二级间接寻址块、三级间接寻址块、数据块。接下来我们要写入一个奇怪的文件,这个文件很大,但是真正的数据只有8K:
- 在 [ 0,4K ] 的位置写入 4K 数据,这个时候只需要 一个 block,把这个编号写到
block[0] 这个位置保存起来; - 在 [ 1T,1T+4K ] 的位置写入 4K 数据,这个时候需要分配一个 block,因为这个位置已经落到三级索引才能表现的空间了,所以需要还需要分配出 3 个索引块;
这个时候,我们的文件看起来是超大文件,size 等于 1T+4K ,但里面实际的数据只有 8 K,位置分别是 [ 0,4K ] ,[ 1T,1T+4K ]。 由于没写数据的地方不用分配物理block块,所以实际占用的物理空间只有8K。
重点:文件 size 只是 inode 里面的一个属性,实际物理空间占用则是要看用户数据放了多少个 block ,没写数据的地方不用分配物理block块。这样的文件其实就是稀疏文件, 它的逻辑大小和实际物理空间是不相等的。 所以当我们用cp命令去复制一个这样的文件时,那肯定迅速就完成了。好,我们再深入思考下,文件系统为什么能做到这一点?
- 首先,最关键的是把磁盘空间切成离散的、定长的 block 来管理;
- 然后,通过 inode 能查找到所有离散的数据(保存了所有的索引);
我把这点小知识给小伙伴讲了一小时,看到他感动欲哭的表情,我觉得他学fei了,非常满意。— 完 —
点这里👇关注我,记得标星呀~
前线推出学习交流一定要备注:研究/工作方向+地点+学校/公司+昵称(如JAVA+上海
扫码加小编微信,进群和大佬们零距离
后台回复“电子书” “资料” 领取一份干货,数百面试手册等