
Elasticsearch 跨网络、跨集群同步选型指南
1、两个同步实战问题
问题1:我想从目前的阿里云上6.7版本的es商业版,迁移到自己的7.10的自建环境,证书不一样,无法远程 无法ccr,有没有实时同步的工具呀?还是只能用logstash ?
问题2:es 2个索引数据同步有什么组件或者方案吗?
2、问题解析
这是个经常被问到的问题。涉及到跨版本、跨网络、跨集群的索引数据的迁移或同步。我们拆解一下:
2.1 跨版本
7.X 是当前的主流版本,早期的业务系统会停留在6.X、5.X 甚至 2.X、1.X 版本。
同步数据要注意:7.X 和 早期版本的不同?
7.X 版本已经经历了7.0——7.12 12+个小版本的迭代了,且7.0版本发布时间:2019-04-10,已经过去了2年+时间。
同步要关注的一个核心点:
官方说明更具备说服力:“Before 7.0.0, the mapping definition included a type name. Elasticsearch 7.0.0 and later no longer accept a default mapping. ”
6.X版本:还有 type 的概念,可以自己定义。
7.X版本:type 就是_doc。
实战举例说明:在 7.X 指定 type 写入数据:
PUT test-002/mytype/1
{
"title":"testing"
}
会有如下的警告:
#! [types removal] Specifying types in document index requests is deprecated, use the typeless endpoints instead (/{index}/_doc/{id}, /{index}/_doc, or /{index}/_create/{id}).
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping.html
2.2 跨网络
两个集群不在一个局域网内,一个挂在云端、一个在本地。
这是常见的业务场景之一,至少我也这么干过。
2.3 跨集群
源数据和目的数据分布在两个不同的集群。
3、同步方案对比
如下几个同步方案,我们边实战边解读。

3.0 实战环境准备
为了演示方便,我们把环境简化。复杂环境,原理一致。
集群1:云端,单结点源集群:172.21.0.14:19022。
集群2:云端,单结点目的集群:172.21.0.14:19205。
两个集群共享一台云服务器,CPU:4核,内存:8G。
版本都一致,都是 7.12.0 版本。
测试数据:100W条(脚本自动生成)。
单条记录如下:
"_source" : {
"name" : "9UCROh3",
"age" : 16,
"last_updated" : 1621579460000
}
3.1 方案一:reindex 跨集群同步
3.1.1 reindex 前置条件:设置白名单
在目标集群上设置源集群的白名单,具体设置只能在:elasticsearch.yml 中。
reindex.remote.whitelist: "172.21.0.14:19022"
注意,如下实战不要在kibana dev tools测试,除非你已经修改了默认超时时间。
3.1.2 reindex 同步实战
POST _reindex
{
"source": {
"remote": {
"host": "http://172.21.0.14:19022"
},
"index": "test_data",
"size":10000,
"slice": {
"id": 0,
"max": 5
}
},
"dest": {
"index": "test_data_from_reindex"
}
}
两个核心参数说明如下:
size:默认一次 scroll 值大小是 1000,这里设置大了 10 倍,是 10000。
slice:把大的请求切分成小的请求,并发执行。(ps:我这里用法不严谨)。
3.1.3 reindex 同步实战结论

脚本测试,reindex 同步 100W 数据,耗时:34 s。
3.2 方案二:elasticdump 同步
https://github.com/elasticsearch-dump/elasticsearch-dump

3.2.1elasticdump 安装注意事项
elasticdump 前置依赖是 node,node要8.0+之后的版本。
[root@VM-0-14-centos test]# node -v
v12.13.1
[root@VM-0-14-centos test]# npm -v
6.12.1
安装成功标志:
[root@VM-0-14-centos test]# elasticdump --help
elasticdump: Import and export tools for elasticsearch
version: 6.71.0
Usage: elasticdump --input SOURCE --output DESTINATION [OPTIONS]
... ...
3.2.2 elasticdump 同步实战
elasticdump \
--input=http://172.21.0.14:19022/test_data \
--output=http://172.21.0.14:19205/test_data_from_dump \
--type=analyzer
elasticdump \
--input=http://172.21.0.14:19022/test_data \
--output=http://172.21.0.14:19205/test_data_from_dump \
--type=mapping
elasticdump \
--input=http://172.21.0.14:19022/test_data \
--output=http://172.21.0.14:19205/test_data_from_dump \
--type=data \
--concurrency=5 \
--limit=10000
基本上面的参数能做到:见名识意。
input :源集群索引。
output :目标集群索引。
analyzer :同步分词器。
mapping :同步映射schema。
data :同步数据。
concurrency :并发请求数。
limit:一次请求同步的文档数,默认是100。
3.2.3 elasticdump 同步实战验证结论

elasticdump 同步 100W数据,耗时:106 s。
3.3 方案四:ESM 工具同步
ESM 是 medcl 开源的派生自:Elasticsearch Dumper 的工具,基于 go 语言开发。
地址:https://github.com/medcl/esm
3.3.1 ESM 工具安装注意事项
依赖 go 版本:>= 1.7。
3.3.2 ESM 工具同步实战
esm -s http://172.21.0.14:19022 -d http://172.21.0.14:19205 -x test_data -y test_data_from_esm -w=5 -b=10 -c 10000
w:并发数。
b:bulk 大小,单位MB。
c:scroll 批量值大小。
3.3.3 ESM 工具同步实战结论
100万 数据 38 s 同步完,速度极快。
esm -s http://172.21.0.14:19022 -d http://172.21.0.14:19205 -x test_data -y test_data_from_esm -w=5 -b=10 -c 10000
test_data
[05-19 13:44:58] [INF] [main.go:474,main] start data migration..
Scroll 1000000 / 1000000 [================================================================================================================] 100.00% 38s
Bulk 999989 / 1000000 [===================================================================================================================] 100.00% 38s
[05-19 13:45:36] [INF] [main.go:505,main] data migration finished.
同步时:CPU 被打爆,说明并发参数生效了。
3.4 方案五:logstash 同步
3.4.1 logstash 同步注意事项
本文基于 logstash 7.12.0,相关插件:logstash_input_elasticsearch 和 logstash_output_elasticsearch 都已经集成安装,无需再次安装。
注意:配置的输入、输出即是插件的名字,要小写。国外的很多博客都有错误,要实战一把甄别。
3.4.2 logstash 同步实战
input {
elasticsearch {
hosts => ["172.21.0.14:19022"]
index => "test_data"
size => 10000
scroll => "5m"
codec => "json"
docinfo => true
}
}
filter {
}
output {
elasticsearch {
hosts => ["172.21.0.14:19205"]
index => "test_data_from_logstash"
}
}
3.4.3 logstash同步测试
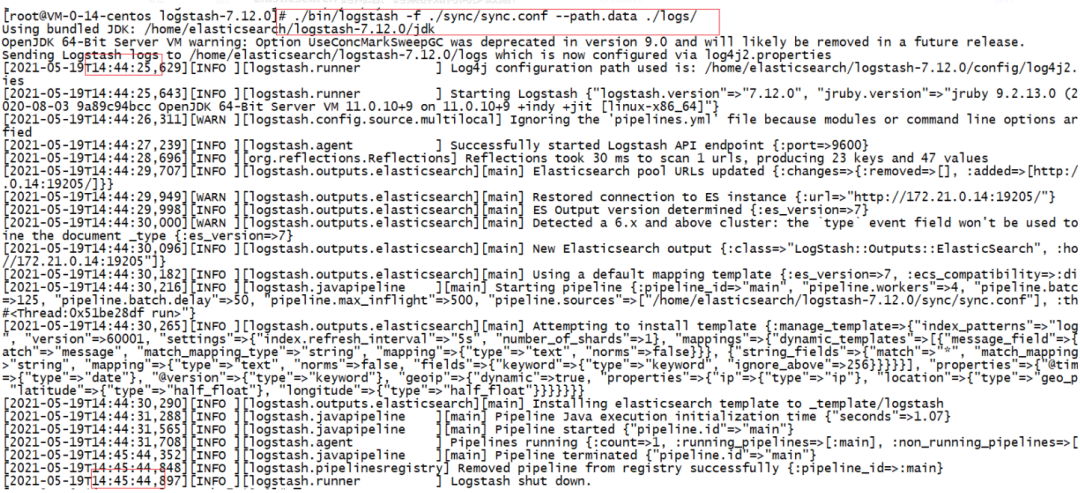
100W 数据 74 s 同步完。
3.5 方案三:快照&恢复同步
3.5.1 快照&恢复配置注意事项
提前在 elasticsearch.yml 配置文件配置快照存储路径。
path.repo: ["/home/elasticsearch/elasticsearch-7.12.0/backup"]
详细配置参考:干货 | Elasitcsearch7.X集群、索引备份与恢复实战。
3.5.2 快照&恢复实战
# 一个节点创建快照
PUT /_snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/home/elasticsearch/elasticsearch-7.12.0/backup"
}
}
PUT /_snapshot/my_backup/snapshot_testdata_index?wait_for_completion=true
{
"indices": "test_data_from_dump",
"ignore_unavailable": true,
"include_global_state": false,
"metadata": {
"taken_by": "mingyi",
"taken_because": "backup before upgrading"
}
}
# 另外一个恢复快照
curl -XPOST "http://172.21.0.14:19022/_snapshot/my_backup/snapshot_testdata_index/_restore"
3.5.2 快照&恢复实战结论
执行快照时间:2 s。
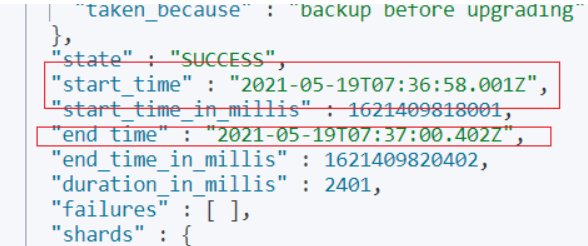
恢复快照时间:1s 之内。
4、小结
本文针对 Elasticsearch 跨网络、跨集群之间的数据同步(模拟),给出了5 种方案,并分别在实战环境进行了验证。

初步验证结论如下:
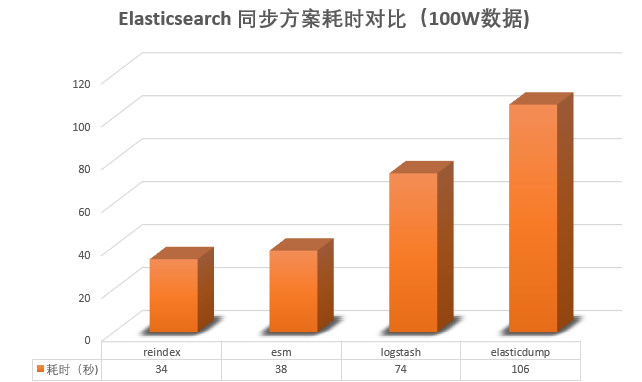
当然,结论并非绝对,仅供参考。
各同步工具本质上都是:scroll + bulk + 多线程综合实现。
本质不同是:开发语言不同、并发处理实现不同等。
reindex 基于 Java 语言开发
esm 基于 go 语言开发
logstash 基于 ruby + java 开发
elastidump 基于 js 语言开发
快照涉及异地拷贝文件,速度制约因素是网络带宽,所以没有统计在内。
如何选型?相信看了本文的介绍,应该做到胸中有数了。
reindex 方案涉及配置白名单,快照和恢复快照涉及配置快照库和文件的传输。
esm、logstash、elastidump 同步不需要特殊配置。
耗时长短和集群规模、集群各个节点硬件配置、数据类型、写入优化方案等都有关系。
你实战开发中是如何同步数据的?欢迎留言讨论。
推荐:
实战 | canal 实现Mysql到Elasticsearch实时增量同步
中国最大的 Elastic 非官方公众号
点击查看“阅读原文”,和全球近 1100 位+ Elastic 爱好者(含中国 50%+ Elastic 认证工程师)一起每日精进 ELK 技能!