
Java不适合做爬虫?试试这个工具!
大家好,我是TJ
一个励志推荐10000款开源项目与工具的程序员

TJ君前几天不能用电脑的时候,就在逛各种论坛,逛着逛着就想,是不是可以弄个爬虫,把这些网上的信息都下下来,自己有空时慢慢研究来着,也是赶巧,这么想的时候正好看到一个爬虫项目,用了下感觉还不错,赶紧来和大家分享以下~
项目的名字很有意思,Spiderman,是指想和蜘蛛侠一样可以发射蛛网,将所有内容一网打尽吗?

Spiderman是一款基于Java开源Web数据抽取的工具。
工具的目标就是收集指定的Web页面并从这些页面中提取有用的数据给用户。
Spiderman主要运用了XPath、正则表达式等基础技术来实数据的抽取与分析。
工具的特点在于使用微内核与插件的不同组合架构,使得工具在扩展性上更强,使用及二次开发更灵活方面,同时对于一些初学者来说不需要额外的编写代码就可以直接使用,并且抽取页面数据的时候还可以以多线程来保证性能。
使用的时候其实只要三步:
确认好想要的目标网站以及目标网页,就是你要爬取的数据目标 打开目标页面获取该页面数据的XPath 在xml配置文件里填写好参数,运行Spiderman即可
那有的初来乍到的小伙伴可能要问了,获取该页面数据的XPath,怎么做?其实也不难。
首先,第一步,下载xpathonclick插件,如果不知道哪里下的话,项目里有提供。 等安装之后,打开Chrome浏览器,可以看到右上角多了一个图标。
在浏览器打开目标网页,然后点击右上角的这个图标,然后再点击网标上想要获取XPath的地方,例如某个标题
按住F12打开JS控制台,拖到底部,可以看到一串XPath内容,进行一些必要的修改,当然这里需要用到一些XPath的语法,可以参考官网教程:https://www.w3school.com.cn/xpath/index.asp
TJ君看代码的时候还发现一个测试代码,其中有如下内容:
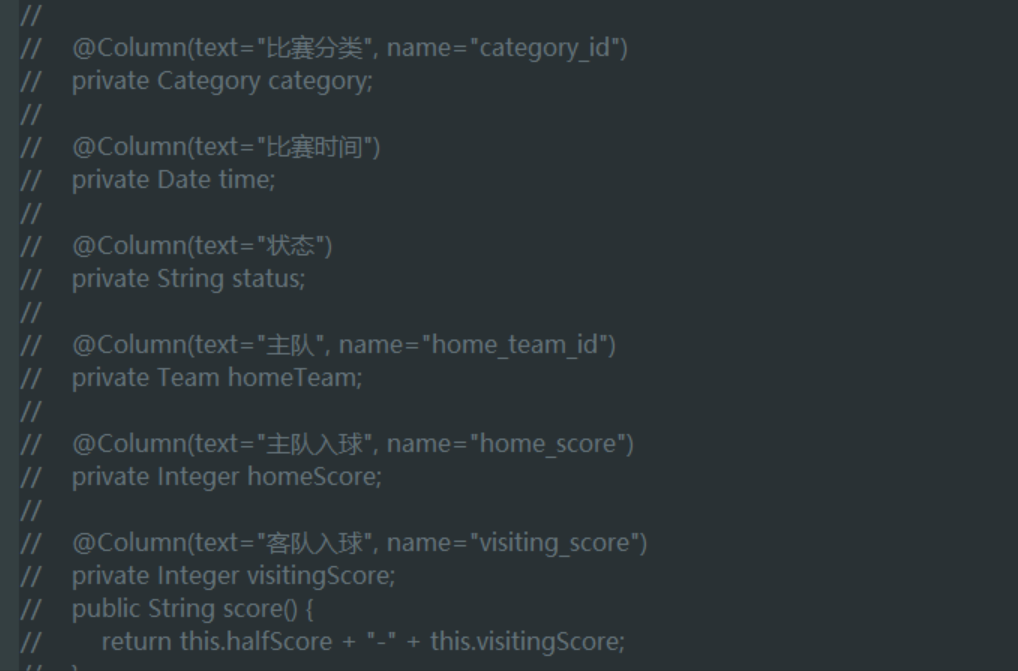
嗯嗯,看到这个,TJ君不由想到了今天五大联赛有什么比赛,不说了,TJ君要去爬比赛信息了~想要程序的小伙伴,赶紧上车:
点击下方卡片,关注公众号“TJ君”
回复“爬取”,获取仓库地址
关注我,每天了解一个牛x、好用、有趣的东东
往期推荐