
Kafka实战:如何跨机房传输数据
工作中遇到Kafka跨机房传输到远程机房的场景,之前的方案是使用Flume消费后转发到目标kafka,当topic增多并且数据量变大后,维护性较差且Flume较耗费资源。
一、原理
参考官网:http://kafka.apache.org/10/documentation.html#basic_ops_mirror_maker
参考:https://www.sohu.com/a/217316110_411876
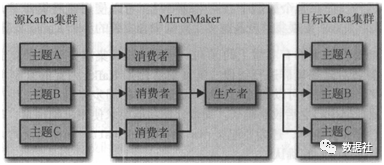
MirrorMaker 为Kafka 内置的跨集群/机房数据复制工具,二进制包解压后bin目录下有kafka-mirror-maker.sh,Mirror Maker启动后,包含了一组消费者,这些消费者属于同一个group,并从多个topic上读取数据,所有的topic均使用该group.id,每个MirrorMaker 进程仅有一个生产者,该生产者将数据发送给目标集群的多个topic;
Kafka MirrorMaker的官方文档一直没有更新,因此新版Kafka为MirrorMaker增加的一些参数、特性等在文档上往往找不到,需要看Kafka MirrorMaker的源码,Kafka MirrorMaker启动脚步如下,发现其主类位于kafka.tools.MirrorMaker,尤其是一些参数的解析逻辑和主要的执行流程,会比较有助于我们理解和运维Kafka MirrorMaker;
代码示例
exec $(dirname $0)/kafka-run-class.sh kafka.tools.MirrorMaker"$@"
MirrorMaker 为每个消费者分配一个线程,消费者从源集群的topic和分区上读取数据,然后通过公共生产者将数据发送到目标集群上,官方建议尽量让 MirrorMaker 运行在目标数据中心里,因为长距离的跨机房网络相对而言更加不可靠,如果发生了网络分区,数据中心之间断开了连接,无法连接到集群的消费者要比一个无法连接到集群的生产者要安全得多。
如果消费者无法连接到集群,最多也就是无法消费数据,数据仍然会在 Kafka 集群里保留很长的一段时间,不会有丢失的风险。相反,在发生网络分区时如果 MirrorMaker 已经读取了数据,但无法将数据生产到目标集群上,就会造成数据丢失。所以说远程读取比远程生成更加安全。
建议:
建议启动多个kafak-mirror-maker.sh 进程来完成数据同步,这样就算有进程挂掉,topic的同组消费者可以进行reblance;
建议将kafka-mirror-maker.sh进程启动在目标集群,原因上文有提及;
kafak-mirror-maker.sh启动默认不会后台运行,调用kafka-run-class.sh的启动内存256M,需要修改一下启动参数(内存大小、日志);
建议对source 集群的whitelist中的topic的消费情况,加实时的积压量监控;
建议producer.properties配置中开启auto.create.topics.enable=true;
二、使用和配置
消费端配置(consumer.properties)
生产环境的source kafka版本是0.10,使用zk指定集群地址,配置方式如下:
zo
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
group.id=groupyzg-02
# 选取镜像数据的起始?即镜像MirrorMaker启动后的数据,参数latest,还是镜像之前的数据,参数earliest
auto.offset.reset=largest
# 更改分区策略,默认是range,虽然有一定优势但会导致不公平现象,特别是镜像大量的主题和分区的时候,0.10版本设置
partition.assignment.strategy=roundrobin
source kafka版本是1.0,配置bootstrap-server指定kafka集群地址,配置方式如下:
bootstrap.servers=kafka1:9092,kafka2:9092,kafka3:9092
group.id=groupyzg-02
# 选取镜像数据的起始?即镜像MirrorMaker启动后的数据,参数latest,还是镜像之前的数据,参数earliest
auto.offset.reset=latest
# 消费者提交心跳周期,默认3000,由于是远程镜像,此处设为30秒
heartbeat.interval.ms=30000
# 消费连接超时值,默认10000,由于远程镜像,此处设为100秒
session.timeout.ms=100000
# 更改分区策略,默认是range,虽然有一定优势但会导致不公平现象,特别是镜像大量的主题和分区的时候
partition.assignment.strategy=org.apache.kafka.clients.consumer.RoundRobinAssignor
# 单个poll()执行的最大record数,默认是500
max.poll.records=20000
# 读数据时tcp接收缓冲区大小,默认是65536(64KiB)
receive.buffer.bytes=4194304
# 设置每个分区总的大小,默认是1048576
max.partition.fetch.bytes=10485760
生产者配置(producer.properties)
配置mirror-maker的source集群和target集群的版本多不一致,当前生产使用的kafka版本是1.0.0版本,producer的配置如下:
bootstrap.servers = 192.168.xxx:9092,192.168.xxx:9092
buffer.memory = 268435456
batch.size = 104857
acks=0
linger.ms=10
max.request.size = 10485760
send.buffer.bytes = 10485760
compression.type=snappy
启动、优化、日志监控
启动命令kafka-mirror-maker.sh中添加端口约束和启动内存配置:
export KAFKA_HEAP_OPTS="-Xmx4G -Xms4G"
export JMX_PORT="8888"
exec $(dirname $0)/kafka-run-class.sh kafka.tools.MirrorMaker"$@"
日志监控:若想输出日志数据,则使用一下命令启动,日志数据会保存在kafka/logs/mirrormaker.out 中;
./kafka-run-class.sh -daemon -name mirror_maker -loggc kafka.tools.MirrorMaker--consumer.config consumer.properties --num.streams 2--producer.config producer.properties --whitelist='testnet'
积压监控:
0.10版本的积压量监控:
./kafka-run-class.sh kafka.tools.ConsumerOffsetChecker--zookeeper xxxx:21810,xxx:21810,xxx:21810--topic testnet -group testnet-group
1.0版本的积压量监控:
./kafka-consumer-groups.sh --bootstrap-server xxx:9092--describe --group testnet-group
进程数监控:建议增加mirror-maker的进程数监控,及时发现并启动挂点进程;
#!/bin/bash
###################
#
# info :5 mins to check last 5mins logs
# add by deploy
# date:20190917
#
###################
#当前时间
sj=`date "+%F %T"`
#当前时间5分钟前
last_sj=`date "+%F %T" -d '-5 min'`
#定义目录
runlog=~/kafka_2.11-1.0.0/alarm/run.log
#通知手机号
noticetel="138XXXXXXXX"
province=~/kafka_2.11-1.0.0/alarm/province.cfg
tmplog=~/kafka_2.11-1.0.0/alarm/tmp.log
###短信通知,也可以使用邮箱通知服务
smsnotice(){
info=$@
IFS=","
for i in $noticetel;do
curl -kd xx
#curl -D - -kd xx
done
}
###判断mirror-maker的进程个数;
province_all=`cat ${province}|wc -l`
mount=`ps -ef|grep -i mirror_maker-gc |wc -l`
ps -ef|grep -i mirror_maker-gc >${tmplog}
echo "the mount of mirror-maker is `expr $mount - 1`!"> $runlog
echo "the mount of province config is $province_all ! ">> $runlog
if[ `expr $mount - 1`-ge $province_all ] ;then
echo "`hostname -i` ----${sj} ---- the mirrormaker is ok!">> $runlog
else
message="`hostname -i` ----${sj} ----the mount mirror-maker processor `expr $mount - 1` is less than the mount of province_config $province_all, "
echo ${message} >> $runlog
while read line
do
province_name=`echo ${line}|awk -F '|' '{print $1}'`
province_code=`echo ${line}|awk -F '|' '{print $2}'`
mount_two=`cat ${tmplog}|grep -i ${province_code} |wc -l`
if[ $mount_two -ge 1] ;then
echo "`hostname -i` ----${sj} ---- the province of ${province_name} is ok!">> $runlog
else
message_two="${message} the province of [ ${province_name} ] mirror-maker processor is down, please check for it!"
echo ${message_two} >> $runlog
smsnotice ${message_two}
fi
done<${province}
fi
长按扫码添加“Python小助手”
进入 P Y 交 流 群
▼点击成为社区会员 喜欢就点个在看吧
