
新出炉大厂面试题100道整理(原题 + 精讲 1.2万字)(一)
大家喜欢的可以给笔者点个赞,花费了很长时间整理,这些面试题更适合中级前端,和需要进阶的高级前端的小伙伴,查缺补漏,为金九银十保驾护航😁😁😁
html篇

. 问题一:Meta标签常用属性值的写法和作用
答:
meta 标签提供关于HTML文档的元数据。元数据不会显示在页面上,但是对于机器是可读的。它可用于浏览器(如何显示内容或重新加载页面),搜索引擎(关键词),或其他 web 服务。
必要属性
name:属性名
content:属性内容
charset: charset为HTML5中新增的,用来声明字符编码;
http-equiv:属性在HTML4中有很多值,在HTML5中只有refresh、default-style、content-type可用
name的值和说明
application name 当前页所属Web应用系统的名称
keywords 描述网站内容的关键词,以逗号隔开,用于SEO搜索
description 当前页的说明
author 当前页的作者名
copyright 版权信息
renderer renderer是为双核浏览器准备的,用于指定双核浏览器默认以何种方式渲染页面
viewreport 它提供有关视口初始大小的提示,仅供移动设备使用
viewreport
meta标签的name属性值为viewreport时的视口的大小
1.content内容为空时,默认视口宽度为980
2.content设置width,不设置initail-scale时,视口宽度为设置的width值
3.content不设置width,只设置initail-scale时,是可以根据initail-scale的值计算出视口的宽度
initail-scale = 屏幕宽度 / 视口宽度
4.content同时设置width和initail-scale时,视口宽度为width的值,页面显示按照initail-scale比率进行缩放
5.一般都是进行如下设置,来实现视口宽等于设备宽,布局完成后屏幕显示也不进行缩放
<meta name="viewport" content="width=device-width, initial-scale=1.0">
声明字符编码
charset属性为HTML5新增的属性,用于声明字符编码,以下两种写法效果一样
<meta charset="utf-8"> //HTML5
模拟http标头字段
http-equiv属性与content属性结合使用, http-equiv属性为指定所要模拟的标头字段的名称,content属性用来提供值。
<meta http-equiv="参数" content="具体的描述">
content-Type 声明网页字符编码:
<meta http-equiv="content-Type" content="text/html charset=UTF-8">
refresh 指定一个时间间隔(以秒为单位),在此时间过去之后从服务器重新载入当前页面,也可以另外指定一个页面.
<meta http-equiv="refresh" content="2;URL=http://www.baidu.com">//2秒后在当前页跳转到百度
X-UA-Compatible 浏览器采取何种版本渲染当前页面
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"> //指定IE和Chrome使用最新版本渲染当前页面
expires 用于设定网页的到期时间,过期后网页必须到服务器上重新传输
<meta http-equiv="expires" content="Sunday 22 July 2016 16:30 GMT">
catch-control 用于指定所有缓存机制在整个请求/响应链中必须服从的指令
<meta http-equiv="cache-control" content="no-cache">
js篇

. 问题1: 给对象加上iterator接口,使之能被 for of遍历
ES6 规定,默认的 Iterator 接口部署在数据结构的 Symbol.iterator 属性,或者说,一个数据结构只要具有Symbol.iterator属性,就可以认为是“可遍历的”(iterable)。Symbol.iterator 属性本身是一个函数,就是当前数据结构默认的遍历器生成函数
因为object 没有 Symbol.iterator 属性,所以不能被 for of 遍历。
const text = {
a: 1,
b: 2,
c:3
}
for(let i of text){
console.log(i) //报错:Uncaught TypeError: text is not iterable
}
所以,object想要被 for … of遍历 ,必须在原来的基础上加上 Symbol.iterator 接口属性。
const text = {
a: 1,
b: 2,
c:3
}
text[Symbol.iterator] = function (){
const _this = this
return {
index:-1,
next(){
const arr = Object.keys( _this )
if(this.index < arr.length){
this.index++
return {
value:_this[arr[this.index]],
done:false
}
}else{
return {
value:undefined,
done:true
}
}
}
}
}
for(let i of text){
console.log(i) // 1 2 3 undefined
}
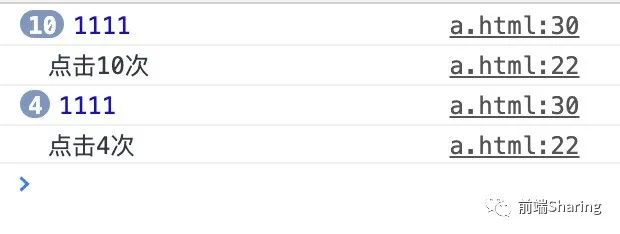
. 问题2:统计按钮一秒钟点击次数?
这道题是变相考对防抖函数+闭包的理解
<script>
const button = document.getElementById('button')
function debounce(fn, time) {
let number = 0 , timer = null
return function(...arg) {
fn.apply(this, arg)
number++
if (timer) return
timer = setTimeout(() => {
console.log( '点击'+ number + '次' )
number = 0
timer = null
}, time)
}
}
button.onclick = debounce(()=>{
console.log(1111)
},1000)
script>
效果如下

. 问题3:单页面应用路由的原理
无论我们用vue还是react构建单页面应用,都离不开路由的概念,路由跳转监听url改变,根据路由的改变来决定渲染的页面。
hash模式
改变路由
const path = "home"
window.location.hash = path
监听路由
window.addEventListener('hashchange',function(e){
//路由发生改变时切换渲染组件...
});
histroy模式
改变路由
var path = "home"
history.pushState(null,null,'?='+path);
监听路由
window.addEventListener('popstate',function(e){
//路由发生改变时切换渲染组件...
})
. 问题4:如下打印结果
执行如下代码,回发生什么?
function fn1(){
console.log(a)
}
var a = 1
function fn2(){
console.log(a)
let a = 2;
console.log(a)
fn1()
}
fn2()
结果://Uncaught ReferenceError: Cannot access 'a' before initialization
let 暂时性死区
let/const是使用区块作用域;var是使用函数作用域
在let/const声明之前就访问对应的变量与常量,会抛出ReferenceError错误;但在var声明之前就访问对应的变量,则会得到undefined
console.log(a) // undefined
console.log(b) // causes ReferenceError: b is not defined
var a = 1
let b = 2
. 问题5:apply和call,bind的区别
apply,call和bind都是 用来改变this的指向
apply和call会让当前函数立即执行,而bind会返回一个函数,后续需要的时候再调用执行
apply,call的区别实参数不同
const foot ={
apple:'苹果'
}
function eat(a,b){
console.log(a,b,this)
}
const bindEat = eat.bind(foot)
eat(1,2) // 1 2 Window
bindEat(1,2) //1 2 foot
eat.call(foot,1,2) //1 2 foot
/* apply参数已数组形式传递 */
eat.apply(foot,[1,2]) //1 2 foot
. 问题6:开发过程中遇到的内存泄露情况,如何解决的?
javascript内存泄漏几种情况
1 意外的全局变量
function foo(arg) {
bar = "this is a hidden global variable";
}
另一种意外的全局变量可能由 this 创建:
function foo() {
this.variable = "potential accidental global";
}
// Foo 调用自己,this 指向了全局对象(window)
// 而不是 undefined
foo();
尽管我们讨论了一些意外的全局变量,但是仍有一些明确的全局变量产生的垃圾。它们被定义为不可回收(除非定义为空或重新分配)。尤其当全局变量用于 临时存储和处理大量信息时,需要多加小心。如果必须使用全局变量存储大量数据时,确保用完以后把它设置为 null 或者重新定义。与全局变量相关的增加内存消耗的一个主因是缓存。缓存数据是为了重用,缓存必须有一个大小上限才有用。高内存消耗导致缓存突破上限,因为缓 存内容无法被回收。
2被遗忘的计时器或回调函数
var someResource = getData();
setInterval(function() {
var node = document.getElementById('Node');
if(node) {
// 处理 node 和 someResource
node.innerHTML = JSON.stringify(someResource));
}
}, 1000);
与节点或数据关联的计时器不再需要,node 对象可以删除,整个回调函数也不需要了。可是,计时器回调函数仍然没被回收(计时器停止才会被回收)。同时,someResource 如果存储了大量的数据,也是无法被回收的。
3脱离 DOM 的引用
var elements = {
button: document.getElementById('button'),
image: document.getElementById('image'),
text: document.getElementById('text')
};
function doStuff() {
image.src = 'http://some.url/image';
button.click();
console.log(text.innerHTML);
// 更多逻辑
}
function removeButton() {
// 按钮是 body 的后代元素
document.body.removeChild(document.getElementById('button'));
// 此时,仍旧存在一个全局的 #button 的引用
// elements 字典。button 元素仍旧在内存中,不能被 GC 回收。
}
4 闭包的错误使用
var theThing = null;
var replaceThing = function () {
var originalThing = theThing;
var unused = function () {
if (originalThing)
console.log("hi");
};
theThing = {
longStr: new Array(1000000).join('*'),
someMethod: function () {
console.log(someMessage);
}
};
};
setInterval(replaceThing, 1000);
每次调用 replaceThing ,theThing 得到一个包含一个大数组和一个新闭包(someMethod)的新对象。同时,变量 unused 是一个引用 originalThing 的闭包(先前的 replaceThing 又调用了 theThing )。思绪混乱了吗?最重要的事情是,闭包的作用域一旦创建,它们有同样的父级作用域,作用域是共享的。someMethod 可以通过 theThing 使用,someMethod 与 unused 分享闭包作用域,尽管 unused从未使用,它引用的 originalThing 迫使它保留在内存中(防止被回收)。当这段代码反复运行,就会看到内存占用不断上升,垃圾回收器(GC)并无法降低内存占用。本质上,闭包的链表已经创建,每一个闭包作用域携带一个指向大数组的间接的引用,造成严重的内存泄露。
解决内存泄漏方式
1 使用严格模式,合理声明变量。使用严格模式可以避免第一种情况的发生。
2 及时清理定时器,延时器,对于不需要的定时器和延时器,一定要及时清除。
3 合理应用闭包,合理的应用闭包,避免闭包函数反复执行导致内存无法及时释放。
. 问题7:介绍一下proto和prototype
proto和prototype 是我们在平时工作中容易忽略的问题,对象原型 和 原型链 的概念也容易混淆。
proto是每个对象都有的属性 ,在JS里,万物皆对象。方法(Function)是对象,方法的原型(Function.prototype)是对象。因此,它们都会具有对象共有的特点。即:对象具有属性proto,可称为隐式原型,一个对象的隐式原型指向构造该对象的构造函数的原型,这也保证了实例能够访问在构造函数原型中定义的属性和方法。
prototypee是函数才有的属性,方法(Function)方法这个特殊的对象,除了和其他对象一样有上述proto属性之外,还有自己特有的属性——原型属性(prototype),这个属性是一个指针,指向一个对象,这个对象的用途就是包含所有实例共享的属性和方法就是该实例的proto。原型对象也有一个属性,叫做constructor,这个属性包含了一个指针,指回原构造函数。
let a = function (){
}
a.prototype.eat = function(){ console.log(111) }
const na = new a()
console.log( na.__proto__ === a.prototype ) // ture
. 问题8:说一下arguments对象
在函数调用的时候,浏览器每次都会传递进arguments对象,arguments 对象实际上是所在函数的一个内置类数组对象,arguments对象不是一个 Array 。它类似于Array,但除了length属性和索引元素之外没有任何Array属性。例如,它没有 pop 方法。但是它可以被转换为一个真正的Array.typeof参数返回 'object'。
属性
arguments.callee指向参数所属的当前执行的函数。指向调用当前函数的函数。
arguments.length传递给函数的参数数量。
arguments[@@iterator]返回一个新的Array 迭代器 对象,该对象包含参数中每个索引的值。
. 问题9:怎么实现一个队列的数据结构?
介绍
队列也是一种线性表。它允许在表的一端插入数据,在另一端删除元素。插入元素的这一端称之为队尾。删除元素的这一端我们称之为队首。
特性
1 在队尾插入元素,在队首删除元素。
2 FIFO(先进先出),就向排队取票一样。
简单js实现
class Queue {
constructor(){
this.queue = []
}
/* 进入队列 */
enqueue(item){
this.queue.push(item)
}
/* 移除队列 */
dequeue(){
this.queue.shift()
}
/* 获取队列长度 */
size(){
return this.queue.length
}
/* 判断是否为空 */
}
css

. 问题一:什么是vw+vh布局?有哪些有优点?有哪些缺陷?
解答:
1什么是什么是vw/vh
css3中引入了一个新的单位vw/vh,与视图窗口有关,vw表示相对于视图窗口的宽度,vh表示相对于视图窗口高度,除了vw和vh外,还有vmin和vmax两个相关的单位。各个单位具体的含义如下:
单位含义vw相对于视窗的宽度,视窗宽度是100vwvh相对于视窗的高度,视窗高度是100vhvminvw和vh中的较小值vmaxvw和vh中的较大值;
这里我们发现视窗宽高都是100vw/100vh,那么vw或者vh,下简称vw,很类似百分比单位。vw和%的区别为:
单位含义%大部分相对于祖先元素,也有相对于自身的情况比如(border-radius、translate等)vw/vh相对于视窗的尺寸
从对比中我们可以发现,vw单位与百分比类似,单确有区别,前面我们介绍了百分比单位的换算困难,这里的vw更像"理想的百分比单位"。任意层级元素,在使用vw单位的情况下,1vw都等于视图宽度的百分之一。
2vw单位换算
同样的,如果要将px换算成vw单位,很简单,只要确定视图的窗口大小(布局视口),如果我们将布局视口设置成分辨率大小,比如对于iphone6/7 375*667的分辨率,那么px可以通过如下方式换算成vw:
1px = (1/375)*100 vw
3缺陷
1 绝大多数的浏览器支持vw单位,但是ie9-11不支持vmin和vmax,考虑到vmin和vmax单位不常用,vw单位在绝大部分高版本浏览器内的支持性很好,但是opera浏览器整体不支持vw单位,如果需要兼容opera浏览器的布局,不推荐使用vw。
2 由于是相对手机窗口,针对不同的手机视图大小不同,所以需要对单位进行换算处理。
. 问题二:什么是rem布局?rem布局的缺陷。
答:
rem布局
rem是一个灵活的、可扩展的单位,由浏览器转化像素并显示。与em单位不同,rem单位无论嵌套层级如何,都只相对于浏览器的根元素(HTML元素)的font-size。默认情况下,html元素的font-size为16px,所以:
1 rem = 12px
为了计算方便,通常可以将html的font-size设置成:
html{ font-size: 62.5% }
这种情况下:
1 rem = 10px
rem单位都是相对于根元素html的font-size来决定大小的,根元素的font-size相当于提供了一个基准,当页面的size发生变化时,只需要改变font-size的值,那么以rem为固定单位的元素的大小也会发生响应的变化。因此,如果通过rem来实现响应式的布局,只需要根据视图容器的大小,动态的改变font-size即可。
rem布局缺陷
1 在响应式布局中,必须通过js来动态控制根元素font-size的大小。
1 css样式和js代码有一定的耦合性。且必须将改变font-size的代码放在css样式之前
. 问题三:怎么让Chrome支持小于12px 的文字
谷歌浏览器默认最小字体为12px,若想让chorme支持12px字体,只需要用css3属性transform就可以
🌰例子:在谷歌浏览器写出10px字体
transform:scale(0.5);
font-size:20px;
搞定收工~~~
. 问题四:透明度opacity和rgba的区别
opacity
取值在0到1之间,0表示完全透明,1表示完全不透明。
.box{opacity: 0.5;}
rgba
rgba中的R表示红色,G表示绿色,B表示蓝色,三种颜色的值都可以是正整数或百分数。A表示Alpha透明度。取值0~1之间,类似opacity。
.box{background: rgba(255,0,0,0.5);}
rgba和opacity的区别
rgba()和opacity都能实现透明效果,但最大的不同是opacity作用于元素,以及元素内的所有内容的透明度,而rgba()只作用于元素的颜色或其背景色。
. 问题五:position的属性值有哪些?
absolute
生成绝对定位的元素,相对于 static 定位以外的第一个父元素进行定位。
元素的位置通过 "left", "top", "right" 以及 "bottom" 属性进行规定。
fixed
生成绝对定位的元素,相对于浏览器窗口进行定位。
元素的位置通过 "left", "top", "right" 以及 "bottom" 属性进行规定。
relative
生成相对定位的元素,相对于其正常位置进行定位。因此,"left:20" 会向元素的 LEFT 位置添加 20 像素。
static
默认值。没有定位,元素出现在正常的流中(忽略 top, bottom, left, right 或者 z-index 声明)。
inherit
规定应该从父元素继承 position 属性的值。
. 问题六:display的属性值有哪些?
none(元素不会被显示);
block(元素将显示为块级元素,元素前后会带有换行符);
inline(元素会被显示为内联元素,元素前后没有换行符);
inline-block(行内块元素。CSS2.1新增的值);
table(元素会作为块级表格来显示,类似table,表格前后带有换行符);
table-row(元素会作为一个表格行显示,类似tr);
table-cell(元素会作为一个表格单元格显示,类似td和th)
flex 弹性盒结构
gird 网格结构
. 问题七:垂直水平居中的方案有哪些(尽量说全面一些)
position absolute 50% + 负margin -50%
.container {
position: relative;
}
.box {
position: absolute;
top: 50%;
left: 50%;
margin-top: -50%;
margin-left: -50%;
}
position absolute 50% + transform -50%
.container {
position: relative;
}
.box {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}
css-table
/* 此处引用上面的公共代码 */
.container {
display: table-cell;
text-align: center;
vertical-align: middle;
}
.box {
display: inline-block;
}
flex
/* 此处引用上面的公共代码 */
.container {
display: flex;
justify-content: center;
align-items: center;
}
.box-center {
text-align: center;
}
grid
/* 此处引用上面的公共代码 */
.container {
display: grid;
justify-items: center;
align-items: center;
}
.box-center {
text-align: center;
}
vue 篇

. 问题1:vue各个生命周期及其作用
1.初始化
beforeCreate:大vue已经初始化,只是数据初始化与事件系统构建尚未形成,不能获取DOM节点(没有data,没有el)
使用场景:因为此时data和methods都拿不到,所以通常在实例以外使用。
created:实例已经创建,仍然不能获取DOM节点(有data,没有el)
使用场景:模板渲染成html前调用,此时可以获取data和methods, 可以初始化进行数据请求,得到渲染数据,,异步操作可以放在这里
2 挂载
beforeMount是个过渡阶段,此时依然获取不到具体的DOM节点,但是vue挂载的根节点已经创建(有data,有el)
mounted:组件挂载完成,数据和DOM都已经被渲染出来了
使用场景:模板渲染成html后调用,通常是初始化页面完成后再对数据和DOM做一些操作,需要操作DOM的方法可以放在这里
3.更新
beforeUpdate:检测到数据更新时,但在DOM更新前执行
updated:更新结束后执行
使用场景:需要对数据更新做统一处理的;如果需要区分不同的数据更新操作可以使用$nextTick
4.销毁
beforeDestroy:当要销毁vue实例时,在销毁前执行
destroyed:销毁vue实例时执行
父子组件mounted和destroyed顺序
beforeMount执行顺序 先父后子
mounted执行顺序,先子后父
beforeDestroy 执行顺序,先父后子
destroyed 执行顺序 , 先子后父
. 问题2:vue3的双向绑定原理,与vue2.0比起来有那些优势?
vue3.0 的数据绑定原理 proxy 对象
vue3.0 于 Proxy 的 observer 实现, 代替了Vue 2 系列中基于 Object.defineProperty 做为响应式原理
感兴趣的同学可以看一下笔者的vue3.0响应式原理详解
传送门:vue3.0 响应式原理(超详细)
优势:
1 对属性的添加、删除动作的监测;
2 对数组基于下标的修改、对于 .length 修改的监测;
3 对 Map、Set、WeakMap 和 WeakSet 的支持;;
4 vue3 对依赖收集用的是weaMap,WeakSet,保持了对键名所引用的对象的弱引用,即垃圾回收机制不将该引用考虑在内,一旦不再需要,WeakMap 里面的键名对象和所对应的键值对会自动消失,不用手动删除引用。
5 vue2.0 初始化data时候,对于对象等引用数据类型,进行了递归处理,也就是对于一些挂载在data上属性,但是并没有用到的属性,也同样做了响应式处理,而vue3.0之后访问到父级属性之后,在进行下一层track,也就是说初始化data时候无需把大量性能浪费在递归上。
. 问题3:vue路由卫士?
vue中路由守卫一共有三种,一个全局路由守卫,一个是组件内路由守卫,一个是router独享守卫。
一、全局路由守卫
只要全局路由变化,就会触发全局的路由守卫。
全局路由守卫有个两个:一个是全局前置守卫,一个是全局后置守卫。
router.beforeEach((to, from, next) => {
console.log(to) => // 到哪个页面去?
console.log(from) => // 从哪个页面来?
next() => // 一个回调函数
}
router.afterEach(to,from) = {}
next(false): 中断当前的导航。如果浏览器的 URL 改变了 (可能是用户手动或者浏览器后退按钮),那么 URL 地址会重置到 from 路由对应的地址,next('/') 或者 next({ path: '/' }): 跳转到一个不同的地址。当前的导航被中断,然后进行一个新的导航。你可以向 next 传递任意位置对象,且允许设置诸如 replace: true、name: 'home' 之类的选项以及任何用在 router-link 的 to prop 或 router.push 中的选项.
二、组件路由守卫
// 跟methods: {}等同级别书写,组件路由守卫是写在每个单独的vue文件里面的路由守卫
beforeRouteEnter (to, from, next) {
// 注意,在路由进入之前,组件实例还未渲染,所以无法获取this实例,只能通过vm来访问组件实例
next(vm => {})
}
beforeRouteUpdate (to, from, next) {
// 同一页面,刷新不同数据时调用,
}
beforeRouteLeave (to, from, next) {
// 离开当前路由页面时调用
}
三、路由独享守卫
路由独享守卫是在路由配置页面单独给路由配置的一个守卫
export default new VueRouter({
routes: [
{
path: '/',
name: 'home',
component: 'Home',
beforeEnter: (to, from, next) => {
// ...
}
}
]
})
. 问题4:vue 中watch和computed区别?
watch侧重点是对数据更新所产生的依赖追踪,而computed侧重点是对数据的缓存与处理引用,这就是watch和computed本质的区别 ,computed可以看作一种特殊的data数据类型 ,它内部进行了二次依赖收集 ,第一次依赖收集是引用computed属性值,而进行的依赖收集 ,第二次是对computed内部是否关联data或者props的属性,而又进行的一次依赖收集。
下面我们按照vue3.0两个例子,来分别两者之前在流程上有什么区别。
watch
<div id="app">
<p>{{ count }}p>
<button @input="add" >addbutton>
div>
<script>
const { reactive, watch, toRefs } = Vue
Vue.createApp({
setup(){
const state = reactive({
count:1,
})
const add = () => state.count++
watch(state.count,(count, prevCount) => {
console.log('新的count=' , count )
})
return {
...toRefs(state),
add
}
}
}).mount('#app')
script>
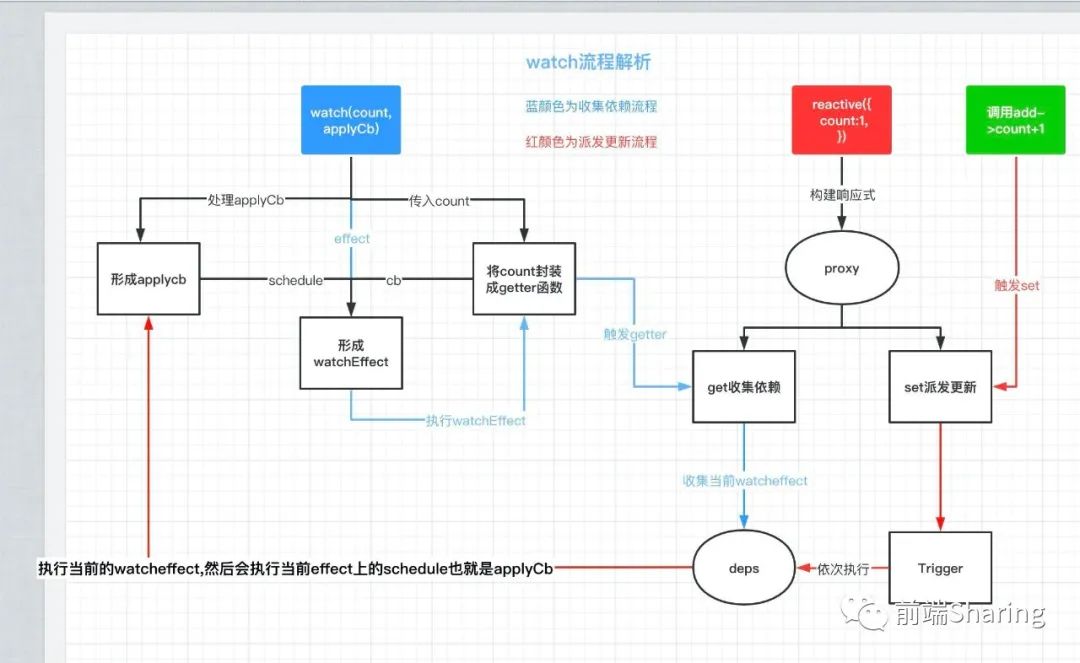
从上述例子我们看出,当点击add后count变化 ,而是 watch作用就是,追踪到count变化 ,而促使回调函数执行。我们用一张流程图来解析整个流程。
computed
<div id="app">
<p>{{ plusOne }}p>
<button @input="add" >addbutton>
div>
<script>
Vue.createApp({
data: () => ({
number: 1
}),
computed: {
plusOne() {
return this.number + 1
}
},
methods: {
add(){
this.number++
}
}
}).mount('#app')
script>
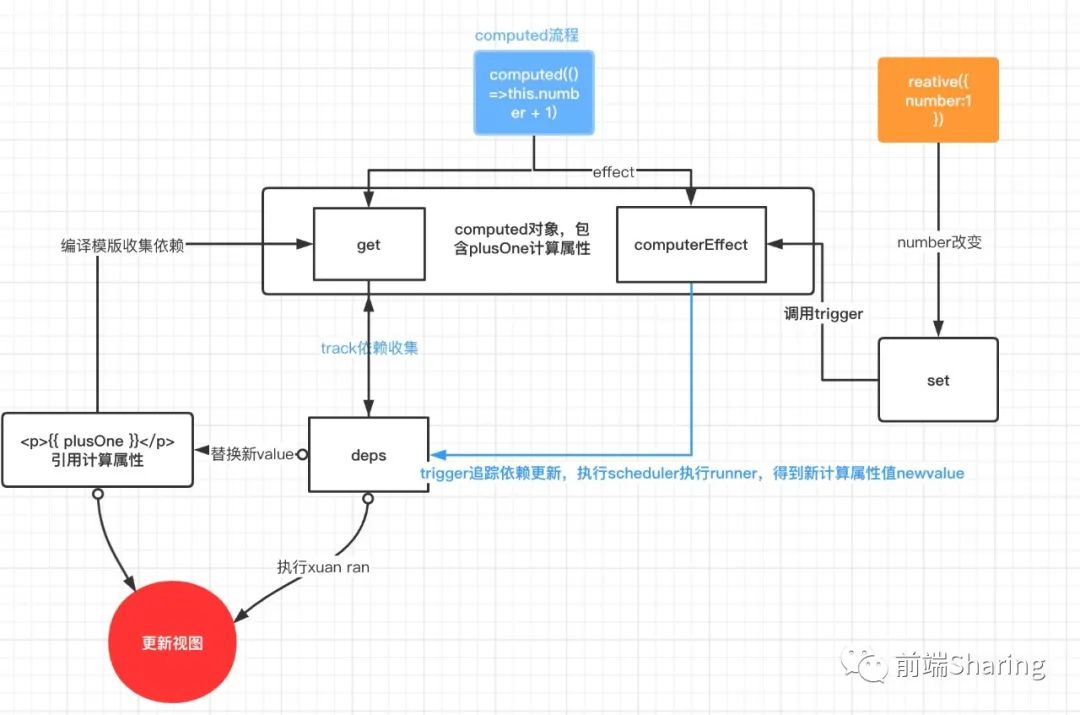
当我们点击add改变的是number,但是引用过this.number的computed也更新了新的值 ,页面更新,我们可以看出 plusOne计算属性可以看作一个对number缓存的数据类型,data下的number收集了plusOne依赖项,同样plusOne也收集了{{ plusOne }}的依赖促使更新视图,我们用一张流程图来解析整个流程。
如果想要看原理解析请看笔者的文章
传送门 vue3.0 watch 和 computed源码解析(举例图解)
. 问题5:vue中data为什么要是个函数?
vue中data必须是一个函数是和js本身特性有关。
我们做vue项目的时候,所有的vue组件都是基于大vue实例化的,我们可以用一个简单例子来解释一下:
function Vue(){
}
Vue.prototype.data = {
name:'jack',
age:22,
}
var componentA = new Vue();
var componentB = new Vue();
componentA.data.age=55;
console.log(componentA,componentB)
此时,componentA 和 componentB data之间指向了同一个内存地址,age 都变成了 55, 导致了问题!
接下来很好解释为什么 vue 组件需要 function 了:
function Vue(){
this.data = this.data()
}
Vue.prototype.data = function (){
return {
name:'jack',
age:22,
}
}
var componentA = new Vue();
var componentB = new Vue();
componentA.data.age=55;
console.log(componentA,componentB)
componentA 和 componentB data之间相互独立, age 分别是 55 和 22
当data是一个方法的时候,每一个实例化组件都会形成一个独立的data对象,相互之间没有影响。
react 篇

. 问题1:setState是同步的还是异步的?
对于这个问题,笔者自己总结了一下:对于setState是同步还是异步,对于整个react代码执行上下文来说,setState是同步的,但是setState触发以后,并不一定得到新的数据,这里有一个react有一个batchUpdate批量更新的概念。
我们来看一个例子🌰:
class Example extends React.Component {
constructor() {
super();
this.state = {
val: 0
};
}
componentDidMount() {
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 1 次 log
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 2 次 log
setTimeout(() => {
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 3 次 log
this.setState({val: this.state.val + 1});
console.log(this.state.val); // 第 4 次 log
}, 0);
}
render() {
return null;
}
};
答案是:0 0 2 3
在React的setState函数实现中,会根据一个变量isBatchingUpdates判断是直接更新this.state还是放到队列中回头再说,而isBatchingUpdates默认是false,也就表示setState会同步更新this.state,但是,有一个函数batchedUpdates,这个函数会把isBatchingUpdates修改为true,而当React在调用事件处理函数之前就会调用这个batchedUpdates,造成的后果,就是由React控制的事件处理过程setState不会同步更新this.state 。
. 问题2:介绍一下 react-hooks API及其如何使用?
usestate 无状态组件的state
useCallback,useMemo 性能优化利器.
useContext 可以使用操纵react context.
useEffect ,useLayoutEffect 副作用钩子 可以替代class声明组件中的声明周期 .useLayoutEffect 在浏览器渲染之前 , effect在浏览器渲染之后
useReducer 功能可以参考redux
useRef 可以获取元素和组件实例,还可以缓存数据
详细的react-hooks使用可以戳👇
传送门:react-hooks如何使用?
webpack篇

. 问题一:webpack性能优化?
打包的时间和打包之后文件的体积是影响webpack性能的主要因素。所以我们可以从这两个方面入手,来优化webpack性能。
1合理使用loader
用 include 或 exclude 来帮我们避免不必要的转译,优化loader的管辖范围。
2缓存babel编译过的文件
loader: 'babel-loader?cacheDirectory=true'
如上,我们只需要为 loader 增加相应的参数设定。选择开启缓存将转译结果缓存至文件系统,可以提交babel-loader的工作效率。
3 DllPlugin类库引入
DllPlugin 是基于 Windows 动态链接库(dll)的思想被创作出来的。这个插件会把第三方库单独打包到一个文件中,这个文件就是一个单纯的依赖库。这个依赖库不会跟着你的业务代码一起被重新打包,只有当依赖自身发生版本变化时才会重新打包。
4 happypack多进程编译
我们都知道nodejs是单线程。无法一次性执行多个任务。这样会使得所有任务都排队执行。happypack可以根据cpu核数优势,建立子进程child_process,充分利用多核优势解决这个问题。提高了打包的效率。
const HappyPack = require('happypack')
// 手动创建进程池
const happyThreadPool = HappyPack.ThreadPool({ size: os.cpus().length })
module.exports = {
module: {
rules: [
...
{
test: /\.js$/,
// 问号后面的查询参数指定了处理这类文件的HappyPack实例的名字
loader: 'happypack/loader?id=happyBabel',
...
},
],
},
plugins: [
...
new HappyPack({
// 这个HappyPack的“名字”就叫做happyBabel,和楼上的查询参数遥相呼应
id: 'happyBabel',
// 指定进程池
threadPool: happyThreadPool,
loaders: ['babel-loader?cacheDirectory']
})
],
}
`
happypack成功,启动了三个进程编译。加快了loader的加载速度。
5 scope Hoisting
scope Hoisting的作用是分析模块之前的依赖关系 , 把打包之后的公共模块合到同一个函数中去。它会代码体积更小,因为函数申明语句会产生大量代码;代码在运行时因为创建的函数作用域更少了,内存开销也随之变小。
const ModuleConcatenationPlugin = require('webpack/lib/optimize/ModuleConcatenationPlugin');
module.exports = {
resolve: {
// 针对 Npm 中的第三方模块优先采用 jsnext:main 中指向的 ES6 模块化语法的文件
mainFields: ['jsnext:main', 'browser', 'main']
},
plugins: [
// 开启 Scope Hoisting
new ModuleConcatenationPlugin(),
],
};
6 tree Shaking 删除冗余代码
Tree-Shaking可以通过分析出import/exports依赖关系。对于没有使用的代码。可以自动删除。这样就减少了项目的体积。
举个例子🌰:
import { a, b } from './pages'
a()
pages 文件里,我虽然导出了两个页面:
export const a = ()=>{ console.log(666) }
export const b = ()=>{ console.log(666) }
所以打包的结果会保留这部分:
export const a = ()=>{ console.log(666) }
b方法直接删掉,这就是 Tree-Shaking 帮我们做的事情。删掉了没有用到的代码。
7 按需加载
像vue 和 react spa应用,首次加载的过程中,由于初始化要加载很多路由,加载很多组件页面。会导致 首屏时间 非常长。一定程度上会影响到用户体验。所以我们需要换一种按需加载的方式。一次只加载想要看到的内容
require.ensure 形式
const getComponent => (location, cb) {
require.ensure([], (require) => {
cb(null, require('../pages/AComponent').default)
}, 'a')
}
"/a" getComponent={getComponent}>
import形式
import B from '@/pages/business/b.vue'
//按需加载变成了:
const B = () => import('@/pages/business/b.vue')
8 按需引用
不知道大家有没有体会到,当我们用antd等这种UI组件库的时候。明明只想要用其中的一两个组件,却要把整个组件库连同样式库一起引进来,就会造成打包后的体积突然增加了好几倍。为了解决这个问题,我们可以采取按需引入的方式。
拿antd为例,需要我们在.babelrc文件中这样声明,
{
"presets": [
[
"@babel/preset-env",
{
"targets": {
"chrome": "67"
},
"useBuiltIns": "usage",
"corejs": 2
}
],
"@babel/preset-react"
],
"plugins": [
[
"@babel/plugin-transform-runtime",
],
//重点按需引入antd里面的style
[ "import", {
"libraryName": "antd",
"libraryDirectory": "es",
"style": true
}]
]
}
经过如上配置之后,我们会发现体积比没有处理的要小很多。
. 问题二:webpack怎么配置多页面应用?
实际这个问题变相再问webpack,配置多入口和多个html对应
entry 应该这么配 ,entry支持 string array object
{
//入口文件配置 string | array | object
entry: {
index: './src/index.js',
list: './src/list.js',
detail: './src/detail.js'
},
}
html输出配置 输出html需要webpack插件 html-webpack-plugin
{
plugins: [
new htmlWebpackPulgin({
title: 'hello 我是首页',
template: './index.html',
inject: 'head',
filename: 'index.html',
chunks: ['index'] //对应 index.js
}),
new htmlWebpackPulgin({
title: 'hello 我是列表',
template: './index.html',
inject: 'body',
filename: 'list.html',
chunks: ['list'] // 对应 list.js
}),
new htmlWebpackPulgin({
title: 'hello 我是详情',
template: './index.html',
inject: 'body',
filename: 'detail.html',
chunks: ['detail'] //对应detail.js
})
]
}
http篇

. 问题1:URL请求页面之后浏览器的解析过程
1.用户输入网址,浏览器发起DNS查询请求,域名解析。
2.三次握手
3.建立tcp连接,发送http请求
4.服务器接受到请求,并相应http请求
5.浏览器对返回的html进行解析,在这期间可能继续请求css,js等文件,浏览器渲染、构建网页
6.断开连接,四次挥手
7.浏览器对页面进行渲染呈现给用户
. 问题2:javascript的同源策略
同源策略是一个重要的安全策略,它用于限制一个origin的文档或者它加载的脚本如何能与另一个源的资源进行交互。它能帮助阻隔恶意文档,减少可能被攻击的媒介。
如果两个 URL 的 protocol、port (如果有指定的话)和 host 都相同的话,则这两个 URL 是同源。这个方案也被称为“协议/主机/端口元组”,或者直接是 “元组”。(“元组” 是指一组项目构成的整体,双重/三重/四重/五重/等的通用形式)。
源的继承
在页面中通过 about:blank 或 javascript: URL 执行的脚本会继承打开该 URL 的文档的源,因为这些类型的 URLs 没有包含源服务器的相关信息。
源的修改
满足某些限制条件的情况下,页面是可以修改它的源。脚本可以将 document.domain 的值设置为其当前域或其当前域的父域。如果将其设置为其当前域的父域,则这个较短的父域将用于后续源检查。
. 问题3:怎么解决ie浏览器对get请求的缓存?
不知道大家有没有过一种情况,在低版本ie浏览器下,在短暂的时间内发出相同的get情况(比如相同时间请求一个数据列表多次),就会发现请求只发送了一次,其他的请求都被浏览器缓存了,对于这种缓存ajax情况,我们可以在url拼上时间戳,这样浏览器就不会认为这是相同的情况,就不会缓存get情况。
以aixos为例,我们可以在每次发起请求的时候对get请求加以拦截
/* 拦截器 */
axios.interceptors.request.use(
(config) => {
const method = config.method || 'get'
if (method.toLowerCase() === 'get') { /* 防止浏览器缓存 */
const url = config.url || ''
const t = new Date().getTime()
config.url = `${url}${url.indexOf('?') === -1 ? '?' : '&'}t=${t}`
}else if(method.toLowerCase() === 'post'){ /* 设置不同请求头 */
//...
}
return config
},
(error) => {
}
)
如上,就完美解决了ajax被ie浏览器缓存的问题。
参考文档
布局常用解决方案对比(媒体查询、百分比、rem和vw/vh)
css中的多种垂直水平居中
JavaScript内存泄露的4种方式及如何避免
vue路由守卫哪几种?
Vue组件为什么data必须是一个函数?
深入 setState 机制
总结
希望看到后觉的不错的小伙伴关注一波公众号,定期分享好的技术文章。
一大波连载好文章正在路上。。。

公众号ID:前端公虾米
冰淇淋里有夏天的味道