
Hudi 实践|阿里云基于 Apache Hudi 构建 Lakehouse 实践探索

本文是阿里云高级技术专家王烨(萌豆)在Apache Hudi 与 Apache Pulsar 联合 Meetup 杭州站上的演讲整理稿件,介绍了阿里云如何使用 Hudi 和 OSS 对象存储构建 Lakehouse,为大家分享了什么是 Lakehouse,阿里云数据库 OLAP 团队如何构建 Lakehouse,也介绍了在构建 Lakehouse 时遇到的问题和挑战,以及如何解决这些问题和挑战。演讲PPT详见文末“阅读原文”
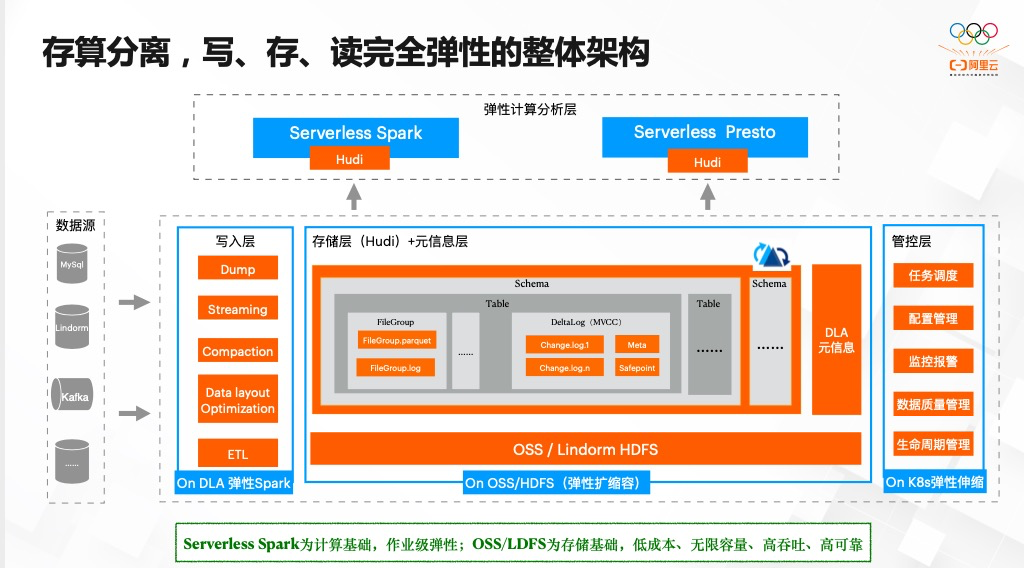
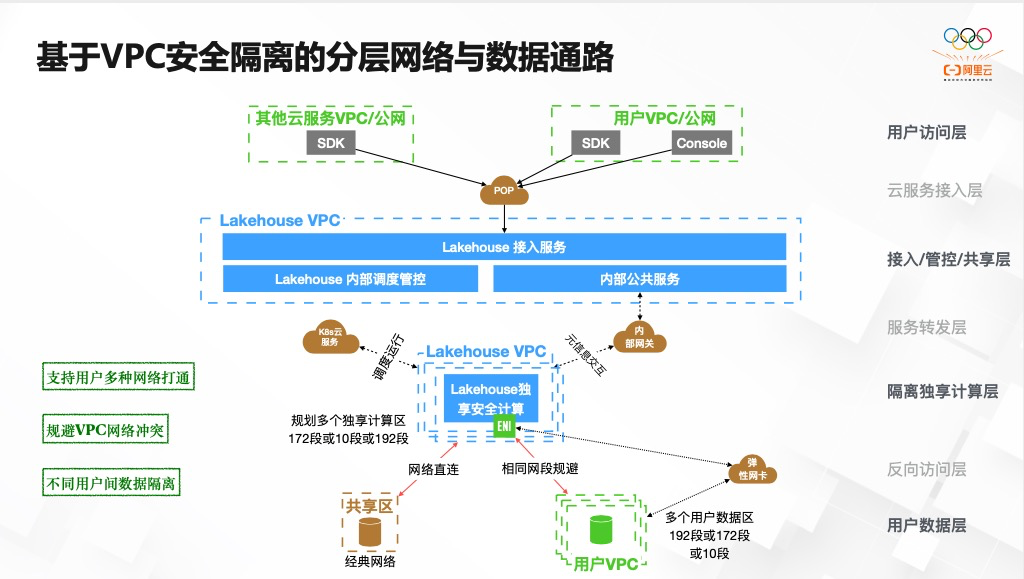
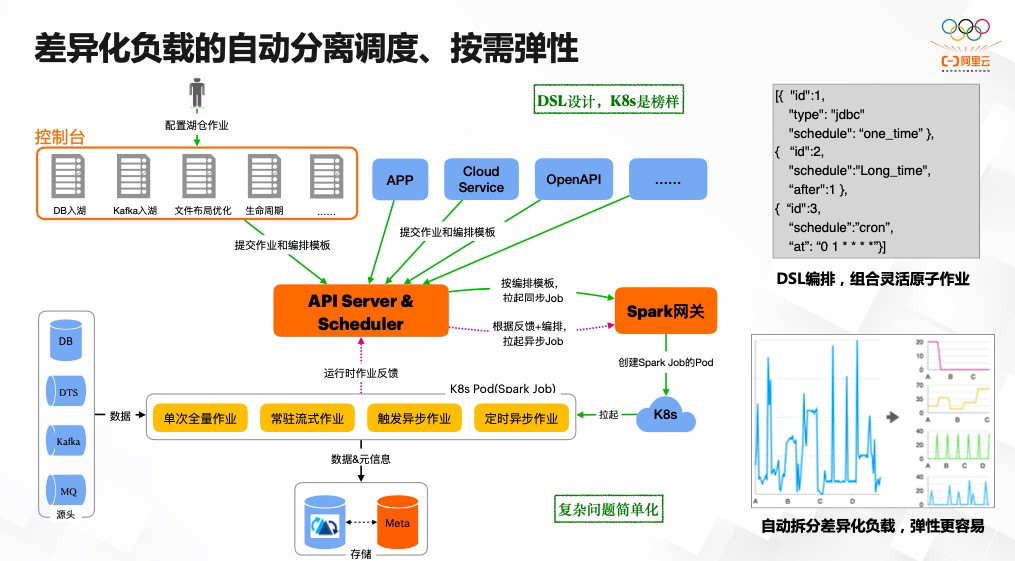
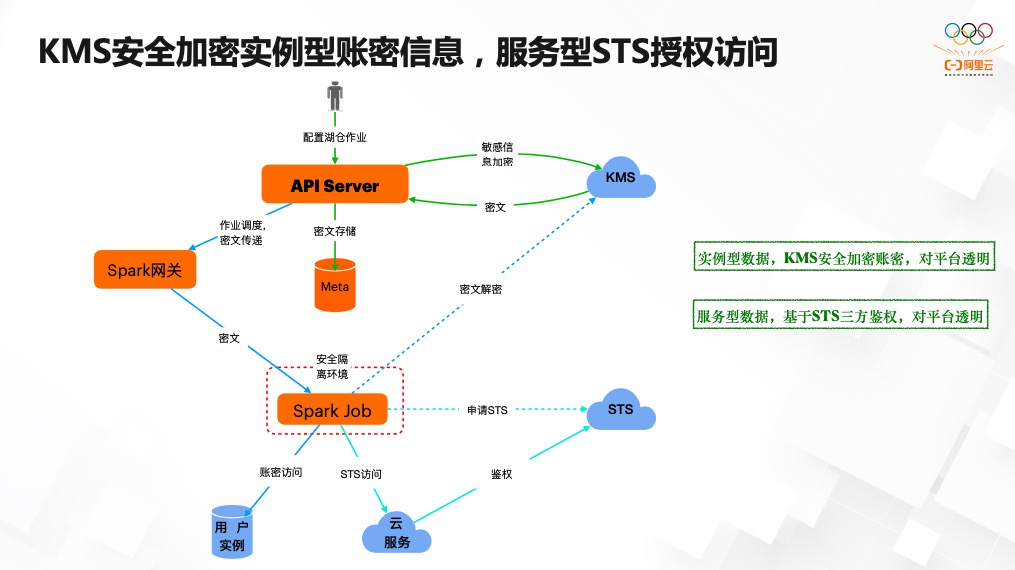
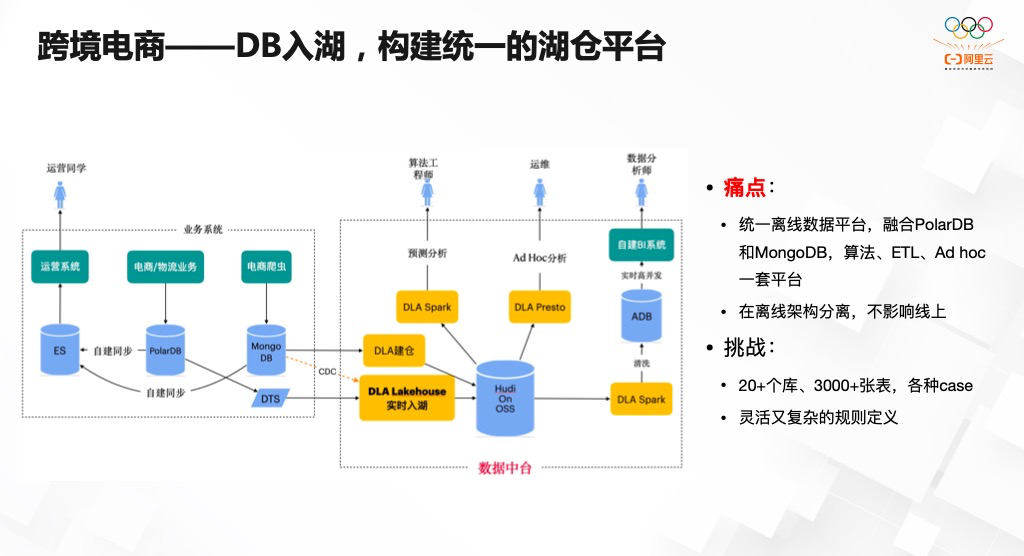
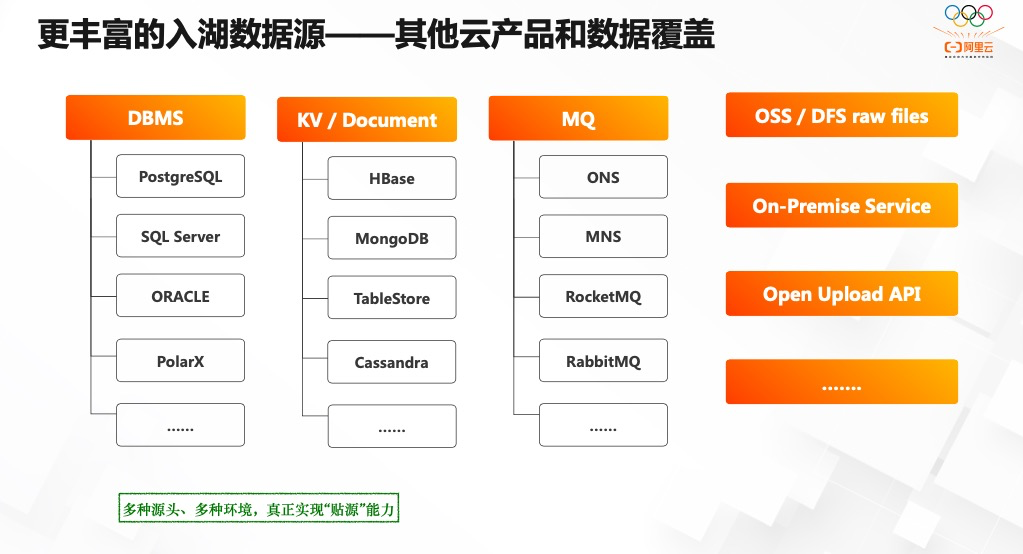
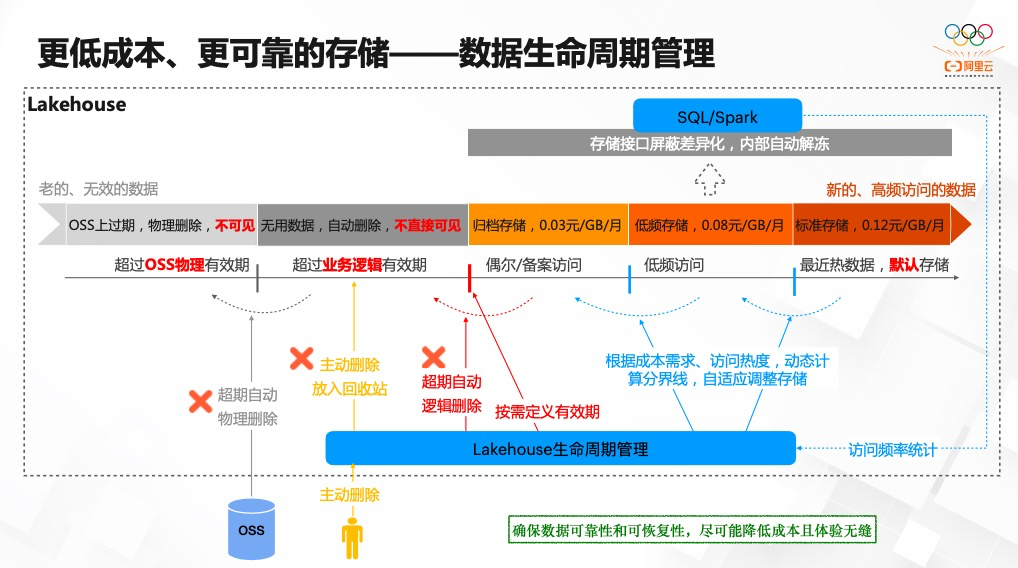
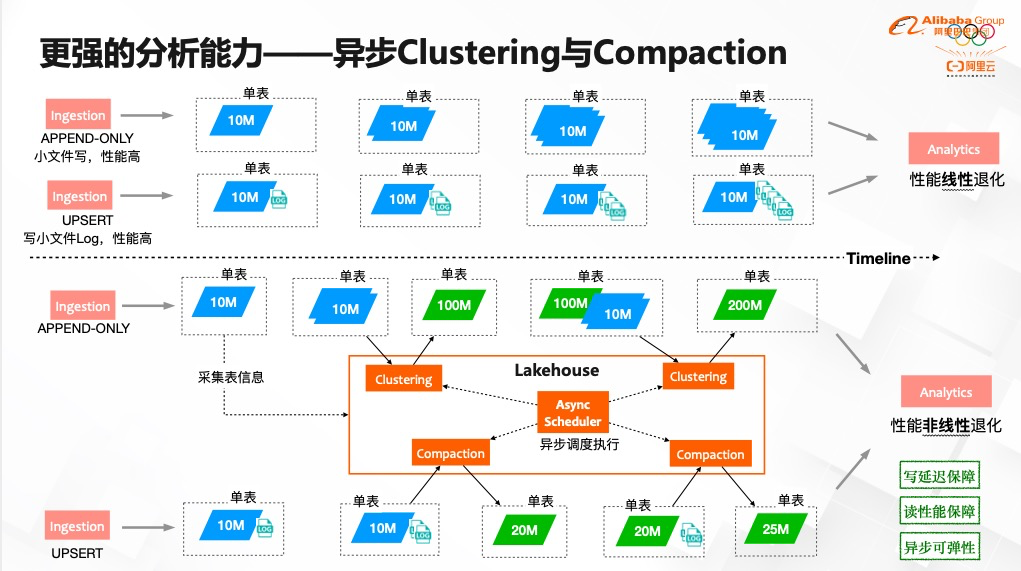
推荐阅读
 点击“阅读原文”下载本期PPT
点击“阅读原文”下载本期PPT
评论