
责任链模式,一门甩锅的技术
你知道的越多,不知道的就越多,业余的像一棵小草!
你来,我们一起精进!你不来,我和你的竞争对手一起精进!
编辑:业余草
来源:juejin.cn/post/6963266532621156389
推荐:https://www.xttblog.com/?p=5357
自律才能自由
好的程序员他实现的不仅仅是一个业务功能,而是一件艺术品。
这到底是谁的锅
我们在平常的业务开发中,经常会遇到很多复杂的逻辑判断,大概的框架可能是像下面这样子的:
public void request() {
if (conditionA()) {
// ...
return;
}
if (conditionB()) {
throw new RuntimeException("xxx");
}
if (conditionC()) {
// do other things
}
}
private boolean conditionC() {
return false;
}
private boolean conditionB() {
return false;
}
private boolean conditionA() {
return true;
}
如果是简单的、不多变的业务,倒也没什么大问题。但要是在比较核心的、复杂的业务,且同一个系统的代码有多人去维护,那么要在上面的这段代码中插入一段逻辑将会非常困难。在实现时,你可能会遇到这些问题:
实现前:我需要考虑这个逻辑分支,应该加在什么地方才能满足要求?会不会被前置条件拦截了? 实现时:逻辑分支要用到一些函数参数,这些参数会不会对后续的逻辑有影响?而且参数会不会被前面的哪些参数给修改掉了?这样我就得去了解前后所有的判断逻辑才能正确实现我要的功能,不然就是要碰碰运气,赌它没改过了... 实现后:加完之后,我要怎么测试?貌似还得构造条件让前面的判断都通过才行...还是要了解前置条件的逻辑
如果放到真实的业务场景,遇到的问题可能还不止这些。不禁感叹,我就想多加一个逻辑分支!怎么就这么难!
有什么办法解决这些问题呢?显然,当要实现一个功能时,需要了解的细节太多了,不符合单一职责的原则。无论是新增逻辑还是修改逻辑,都是有很强的侵入性的,也不符合开闭原则。我前后的逻辑细节不是我负责的,我要把这些锅甩出去才行,要更好地甩锅,那么这时候就要用到责任链模式了。
甩锅的套路
责任链,顾名思义,是一个链条,链条中有很多个节点。映射到数据结构上,则是一个有序的队列,队列中有很多个元素,每个元素都独立处理自己的逻辑,并且在处理完之后,将流程传递到下一个节点。所以,在这个模式里,可以抽象出两个角色:链和节点。其中,链负责处理请求和组装节点,而每个节点则负责处理自己的业务逻辑,无需关心这个节点的上下游是如何处理的。
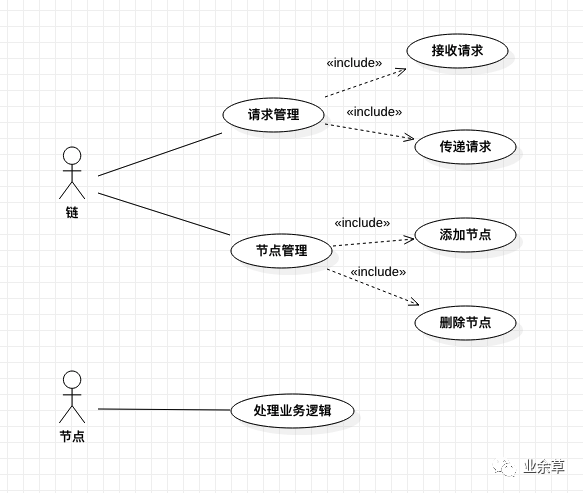
因此,从用例的视角来看,可以得出下面的用例图:
那么,责任链是否可以解决上述的问题呢?上述问题,其实对应着下面的几个问题:
要满足需求,应该在什么地方实现需求? 实现这个需求会不会对其他模块带来影响,其他模块又会不会对我实现的逻辑带来什么影响? 需求实现后该如何测试?
由责任链的角色划分可以很清楚地知道:
对于第一个问题,应该是链条这个角色应该关心的,从业务的视角来安排节点在哪个位置实现即可。 对于第二个问题,需求的实现由节点负责。对于责任链中的入参,只提供读方法,不提供写方法,这样可以很好地避免某个节点偷偷篡改参数的风险,对于其他节点来说,无需担心其他节点对入参进行了修改。每个节点之间的职责分明,由责任链本身的结构就决定了模块之间的影响很小。 对于第三个问题,节点的逻辑实现后,只需对节点逻辑本身做测试,至于能否逻辑能否执行到这个节点上,则由链条设置的节点顺序做保证。测试时只需保证顺序正确即可,完全没有必要从请求开始的地方开始执行,构造一堆条件让代码执行到自己的逻辑上。
上面提到的问题,都可以利用责任链模式很好地解决这些问题。那又该如何实现责任链模式呢?
是时候展现真正的甩锅技术了
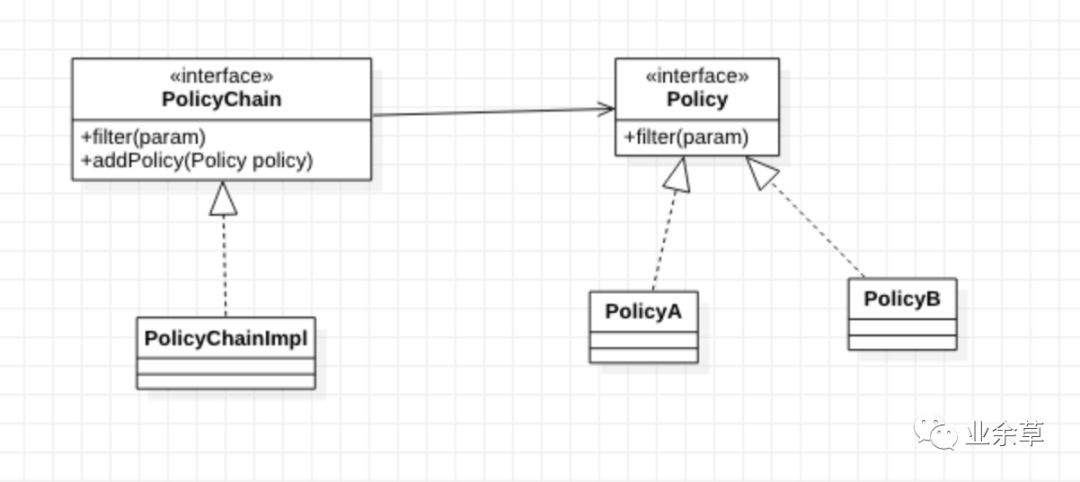
按照上面用例图的定义,链条负责管理节点,是请求的入口,而节点是链条的其中一环。那么这两者的关系属于聚合关系。得到类图如下:
甩锅秘技一
如果我们在Spring框架的基础上进行开发,那么我们很容易就可以实现一个简单的责任链模式:
@Component
@RequiredArgsConstructor
public class PolicyChain1 {
private final List<Policy<ContextParams, String>> policies;
public void filter(ContextParams contextParams) {
policies.forEach(policy -> {
policy.filter(contextParams);
});
}
}
只要将 Policy 的实现类也标记为 Component,那么 Spring 的自动注入机制帮我们实现了 addPolicy 的方法,摆脱了繁琐的添加节点的过程代码。
但是,这有一个很严重的问题,要怎么控制每个 Policy 之间的顺序呢?这时可能你会想到用@Order注解解决这个问题。但是假设 Policy 有几十个,如果你需要在第 10 和第 11 个 Policy 插入一个 Policy,那么是不是要将从第 11 个开始往后的所有 Policy 都调整一下顺序?想想都觉得麻烦。因此,这种方式,只能用于对顺序无要求的情况,比如用来做权限校验时,各个校验条件互不相关,也无先后顺序的限制,那么就可以用这种方法实现,扩展性强,实现也简单。
甩锅秘技二
可是需求上要求一定要按顺序,那该怎么办呢?上面已经分析了指定 Order 的方式不可取,还有什么方法呢?
其实上面的方法其实和插入一个数组时的操作十分相似。当要在数组中间插入一个元素时,插入位置之后的元素都要往后挪一位。对应上述的做法,其实就是对应的 Policy 的 Order 值要加 1。那么类似地,数组对插入的效率低,那换个效率高的做法,不就是链表么?我们可以将每个 Policy 都持有下一个要处理的 Policy 的引用,当这个 Policy 处理完之后,调用下一个 Policy 的 filter 方法,然后再将上一个 Policy 的引用修改一下,不就可以很好地完成插入操作了么?
先画一个类图
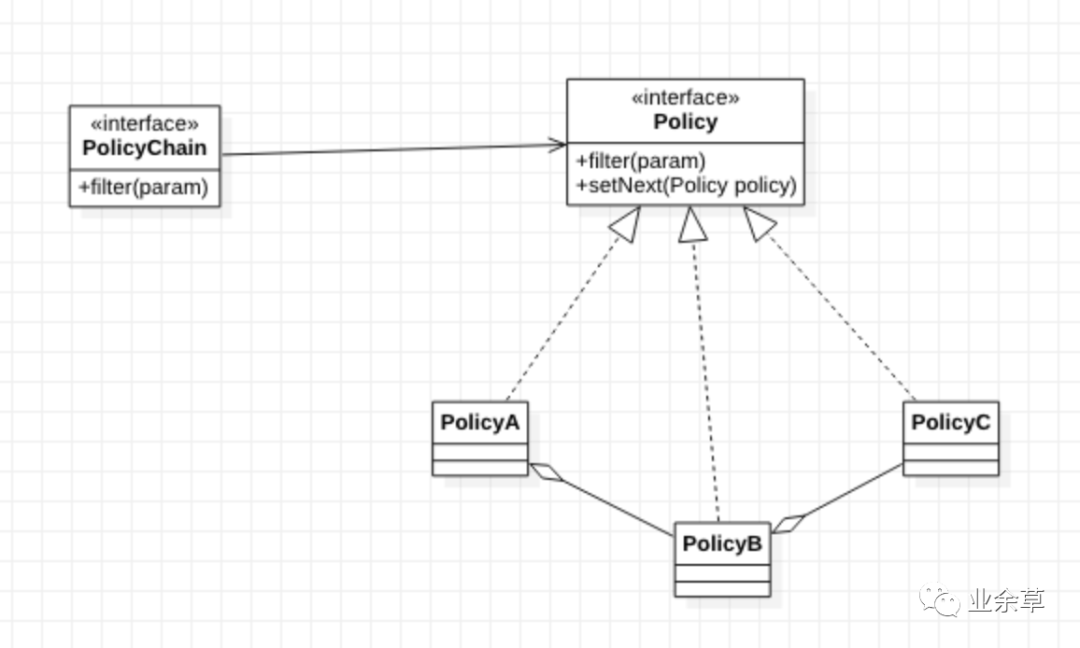
这样组织之后,PolicyA 需要持有 PolicyB 的引用,PolicyB 也需要持有 PolicyC 的引用。当需要在 B 和 C 之间加入一个 D 时,那么我就需要将 B 中的引用指向 D,然后 D 再指向 C 即可。
但是,这样组织之后,我并不知道这个链条的全貌,这个链条有哪些节点、顺序是怎样的,我并不能一下子推断出来了。另外,这和上面推断出来的用例图不符,在用例中,链条才是负责节点的组装的,现在相当于甩给了每个节点去做了,这明显违反了单一职责原则啊!
既然这样,那我仍然把节点组装放到链条里实现,节点只实现逻辑,只是在组装的时候,可以让使用方显式指定顺序,这样不就好了吗?
大概的实现是这样:
@Component
@AllArgsConstructor
public class PolicyChain2 {
private SessionJoinDeniedPolicyHandler sessionJoinDeniedPolicyHandler;
private SessionLockPolicyHandler sessionLockPolicyHandler;
private SessionPasswordPolicyHandler sessionPasswordPolicyHandler;
@PostConstruct
public void init() {
sessionLockPolicyHandler.setNextHandler(sessionJoinDeniedPolicyHandler);
sessionJoinDeniedPolicyHandler.setNextHandler(sessionPasswordPolicyHandler);
}
public void filter(ContextParams params) {
sessionLockPolicyHandler.filter(params);
}
}
这样链条本身就需要知道各个节点都是什么,这样才能把不同的节点组装起来。
// 策略抽象类
public abstract class PolicyHandler<T> {
private PolicyHandler<T> nextHandler;
void setNextHandler(PolicyHandler<T> handler) {
nextHandler = handler;
}
public void filter(T context) {
doFilter(context);
if (nextHandler != null) {
nextHandler.filter(context);
}
}
protected abstract void doFilter(T context);
}
// 策略实现类
@Component
public class SessionPasswordPolicyHandler extends PolicyHandler<ContextParams> {
@Override
public void doFilter(ContextParams context) {
String requestParam = context.getRequestParam();
if (Objects.equals(requestParam, "ok")) {
return;
}
throw new RuntimeException("session password throw exception");
}
}
对于节点本身,就只需要关注自身处理的业务逻辑了,使用方只要调用一下 PolicyChain 的 filter 方法,接下来的逻辑都会自动按顺序完成了!
看来这样的实现差不多就可以满足需求了!直到...我用这个秘技实现了一个计数器的时候...
需求是这样的,为了减少数据库的压力,我在一个加入房间的方法上加了一个注解,并用秘技二实现了一个计数器,以用于校验加入的人数是否超出了房间限制的大小,这样可以减少对数据库的查询次数。实现代码大致如下:
@ValidatePolicy
public void filter() {
join();
}
// validate注解对应的拦截方法,此处省略了切面类的相关代码,仅展示核心内容
public void validate() {
strategyRouter.applyStrategy(ContextParams.builder()
.isJoinDenied(false)
.isLocked(false)
.password("123")
.build());
}
直到有一天,房间限制 3 人加入,此时房间里有 2 个人,执行 join 方法,validate() 方法愉快地通过了校验并将自身的计数器设置为 3,但是在执行 join 方法的时候抛出了异常,原本应该加入成功的第3个人并没有加入成功。接着第 4 个人加入房间,因为房间内只有 2 个人,那么第 4 个人应该是加入成功的,但是因为计数器已经被设置为 3,那么第 4 个人直接在校验阶段就抛异常了...
那么,在秘技 2 的基础上,当执行后面的方法出异常时捕获异常,然后把计数器校正就好了!可是,在这种实现方式下根本做不到,因为每个节点只专注于处理自己成功拦截时的逻辑,而忽略了自身逻辑处理完之后,后续逻辑出了异常时该怎么办的情况。由此可得,秘技二能处理有顺序的节点,能用于无状态的前置校验,但无法支持后续逻辑出现异常时,节点本身还需要处理回滚操作的情况。
甩锅秘技三
基于上面的问题,我需要找到一种能支持回滚的实现方式。这时 我参考了 Spring Cloud Gateway 中 Filter 的实现,发现有几个特点:
每个节点会依赖链条本身,当要执行下一个节点的处理逻辑时,只需要调用 chain.filter()方法即可。将节点顺序的定义和节点的创建分开,避免了链条对具体节点的依赖,对节点的创建,可以通过工厂模式实现,增强了扩展性。
大致类图如下:
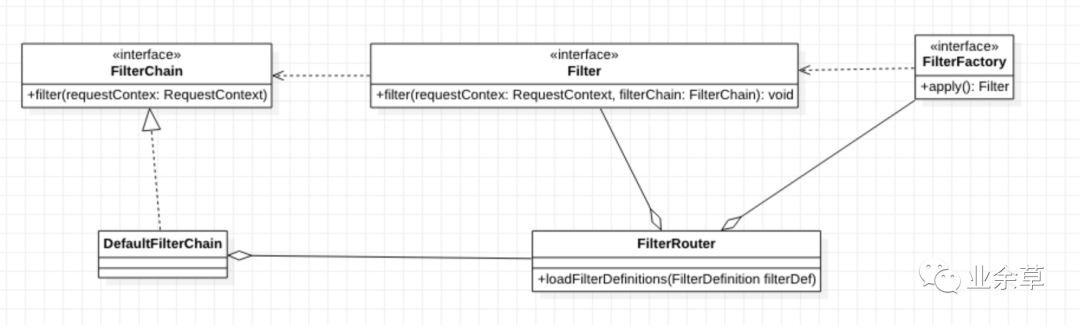
首先我们看如何支持顺序。在 FilterRouter 中,有一个 loadFilterDefinitions 的方法,子类可以重写这个方法以定义责任链中存在哪些节点。链条本身变得不关心节点的顺序了,转而将节点顺序的处理委托给另一个对象。同时,除了可以支持在 FilterRouter 用代码显式定义之外,还可以通过重写 loadFilterDefinitions 的方式,从不同的来源指定节点顺序,比如配置文件、外部系统等,使得顺序的定义更灵活,扩展性更强。
@RequiredArgsConstructor
public abstract class FilterRouter<T, R> {
private final Map<String, FilterFactory<T, R>> filterFactories;
public List<Filter<T, R>> getFilters(T filterChainContext) {
final List<FilterDefinition> filterDefinitions = new ArrayList<>();
loadFilterDefinitions(filterChainContext, filterDefinitions);
List<Filter<T, R>> filters = filterDefinitions.stream().map(filterDefinition -> {
FilterFactory<T, R> filterFactory = filterFactories.get(filterDefinition.getName());
return filterFactory.apply();
}).collect(Collectors.toList());
filterDefinitions.clear();
return filters;
}
protected abstract void loadFilterDefinitions(T filterChainContext, List<FilterDefinition> filterDefinitions);
}
@Component
public class DefaultFilterRouter extends FilterRouter<String, String> {
public DefaultFilterRouter(Map<String, FilterFactory<String, String>> filterFactories) {
super(filterFactories);
}
@Override
protected void loadFilterDefinitions(String filterChainContext, List<FilterDefinition> filterDefinitions) {
filterDefinitions.add(new FilterDefinition(PasswordFilterFactory.KEY));
}
}
接下来我们看下节点操作如何支持回滚。通过实现FilterFactory接口,可以在 apply 方法中执行自身的校验逻辑,并对后续的处理捕获异常,当捕获到异常时,在异常处理的代码块中处理回滚异常。另外,借助 Spring 框架的自动注入,将 Factory 声明为 Component,这样 FilterRouter 在收集 Filter 实现时,也免除了繁琐的 add 方法。
@Component
public class PasswordFilterFactory implements FilterFactory<String, String> {
public static final String KEY = "passwordFilterFactory";
@Override
public Filter<String, String> apply() {
return (filterChainContext, filterChain) -> {
// validate
try {
return filterChain.filter(filterChainContext);
} catch (Exception e) {
// rollback
}
return "";
};
}
}
至于 DefaultFilterChain 这个类,做的事情就是接收请求,将通过 FilterRouter 的 FilterFactory 生成 Filter 列表而已。代码如下:
public class DefaultFilterChain<T, R> implements FilterChain<T, R> {
private final T filterChainContext;
private int index = 0;
private final List<Filter<T, R>> filters = new ArrayList<>();
public DefaultFilterChain(FilterRouter<T, R> filterRouter, T filterChainContext) {
this.filterChainContext = filterChainContext;
filters.addAll(filterRouter.getFilters(filterChainContext));
}
public R filter() throws Throwable {
return filter(filterChainContext);
}
@Override
public R filter(T filterChainContext) throws Throwable {
int size = filters.size();
if (this.index < size) {
Filter<T, R> filter = filters.get(this.index);
index++;
return filter.filter(filterChainContext, this);
}
return null;
}
public void addLastFilter(Filter<T, R> filter) {
filters.add(filter);
}
}
使用时的代码:
@Component
@RequiredArgsConstructor
public class Client {
private final DefaultFilterRouter defaultFilterRouter;
public void filter(String param) throws Throwable {
DefaultFilterChain<String, String> filterChain = new DefaultFilterChain<>(defaultFilterRouter, param);
filterChain.filter(param);
}
}
至此,最后一种实现方式,既可以满足对节点顺序性的要求,也可以支持节点对后续逻辑出错时的后置处理。同时也具备比较好的扩展性,可以实现从不同来源加载节点顺序,可以通过 FilterFactory 实现不同的 Filter。接着将第 3 种秘技封装成组件,这样业务在接入的时候就可以优雅甩锅了。
甩锅总结
上述列举了 3 种责任链模式的实现方式,可以分别应对三种场景:
对节点顺序无要求,可用秘技一,实现方式比较简单 对节点顺序有要求,且所有节点的处理都是无状态的,不需要进行后置处理的,可使用秘技二 对节点顺序有要求,且有其中一个节点的处理是有状态的,需要进行后置处理的,可使用秘技三
设计模式经典书籍《设计模式:可复用面向对象软件的基础》中有一句话提到,“找到变化,封装变化”。其实这是设计模式的底层逻辑。
回顾整个过程,我们可以看到:
从流水账式的代码,到秘技一,变化的是新增一段插入逻辑,最终封装的效果,正是让这段插入逻辑变成了其中一个节点的处理逻辑。 从秘技一到秘技二,变化的是需要支持节点顺序,而最终封装的效果,则是将顺序的定义内聚在了链条的内部,支持了自定义顺序。 从秘技二到秘技三,变化的是节点需要支持回滚,支持后置处理,而封装的结果,就是将后续的处理的逻辑暴露给节点,但节点依赖的是链条本身,将后续的处理逻辑屏蔽起来,节点依然聚焦在自身的处理逻辑上。
由此可见,过程式的代码,到设计模式的演进,都并不是凭空捏造的,而是「由问题出发,找到其核心的变化点,并对变化点进行封装和抽象」,才慢慢形成最终比较理想的结果。