
教你用 Python 快速获取相关概念股,辅助价值投资!

下面以「 市盈率 」为例,讲解使用 Python 获取相关概念股的完整流程
# 1. 市盈率 PE
股票市盈率,简称 PE,是股票价格除以每股盈利的值,是价值投资中一个非常重要的财务指标
一般来说,市盈率越低,投资风险越小,投资价值越高
市盈率也分为 3 种
市盈利 - 静
市盈率 - 动
市盈率 - 滚动 TTM
其中
市盈率(静)的值为总市值除以去年一年的总净利润
市盈率(动)的值为总市值除以预估今年全年的总净利润
市盈率(滚动)TTM 的值为总市值除以最近 4 个季度的总净利润
总体来说,市盈率 TTM 相比前两者,数据值更具体参考性
# 2. 爬取相关概念列表
目标对象:
aHR0cDovL3N0b2NrLmpyai5jb20uY24vY29uY2VwdC9jb25jZXB0cGFnZS5zaHRtbD90bz1wYw==
首先,利用 requests + lxml 获取网页元素进行解析
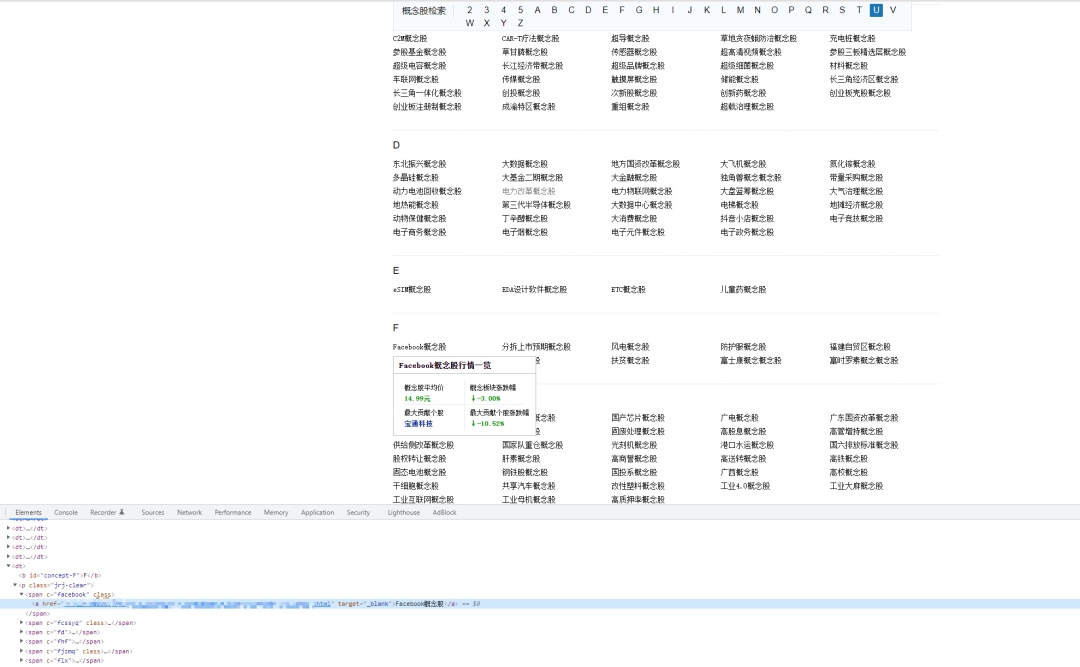
接着,利用正则过滤出关键数据,包含:相关概念名称、链接地址、相关概念 ID
import requests
from lxml import etree
import re
...
def __get_concept_stocks_info(self):
"""
获取概念股信息
:return:
"""
html_element = etree.HTML(self.session.get(self.home_url).text)
a_elements = html_element.xpath('//p[@class="jrj-clear"]//a')
result = []
for a_element in a_elements:
a_element_text = a_element.xpath('./text()')[0].replace('概念股', '')
a_element_href = a_element.xpath('./@href')[0]
if self.keyword in a_element_text:
a_element_tag = re.findall(r'^.*_(.*).shtml$', a_element_href)[-1]
result.append({
"cs": a_element_text,
"href": a_element_href,
"tag": a_element_tag
})
return result
...# 3. 爬取概念个股
分析个股列表页面后,发现列表数据来源于 JS 文件,URL 中的变量为上面的概念 ID
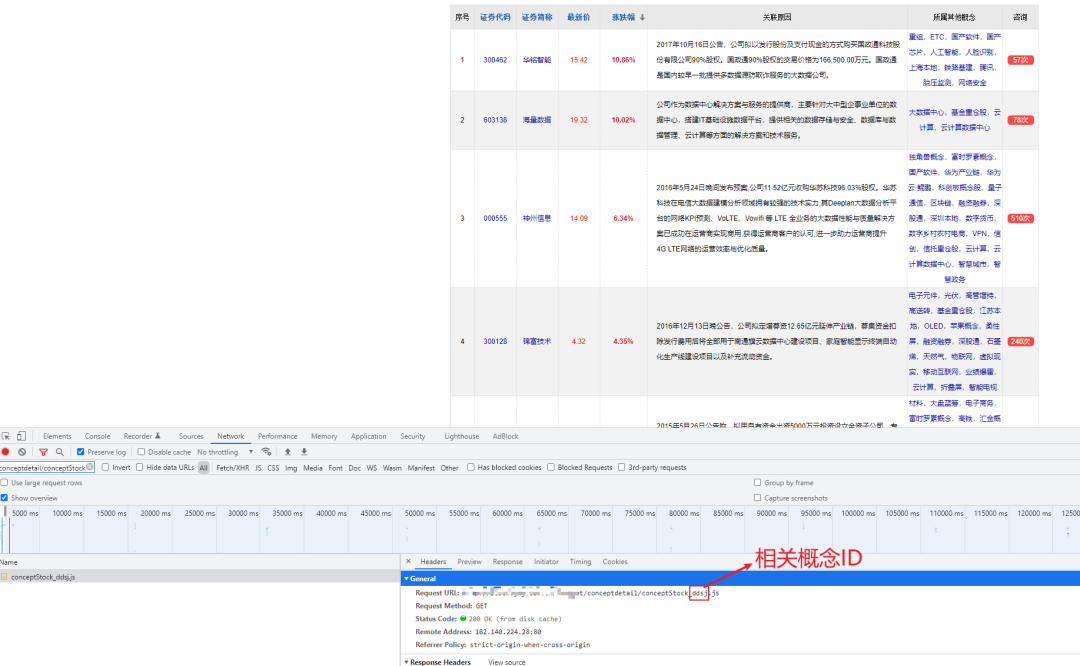
遍历相关概念列表,就可以获取到所有个股数据
PS:这里仅获取股票名称及编号
...
def __get_concept_stocks(self, concept_stocks_info):
"""
获取相关概念股列表
:param concept_stocks_info:
:return:
"""
url = f'http://**/concept/conceptdetail/conceptStock_{concept_stocks_info.get("tag")}.js'
headers = {'User-Agent': UserAgent().random}
# 去掉换行符,转为中文
resp = self.session.get(url, headers=headers).text.replace('\n', '').encode('utf-8').decode(
'unicode_escape')
# 正则匹配,获取对应股票
stocks_list = json.loads(re.findall(r'^.*"stockData":(.*)};$', resp, re.IGNORECASE)[0].replace("\'", "\""))
return [(item[1], item[0]) for item in stocks_list]
...
# 2、获取相关概念列表
for concept_stocks_info in concept_stocks_infos:
concept_stocks = self.__get_concept_stocks(concept_stocks_info)
# print('概念个股列表如下:')
# print(concept_stocks)
...# 4. 个股详情及排序
分析个股详情页面后,发现 URL 由时间戳及股票 ID 组成
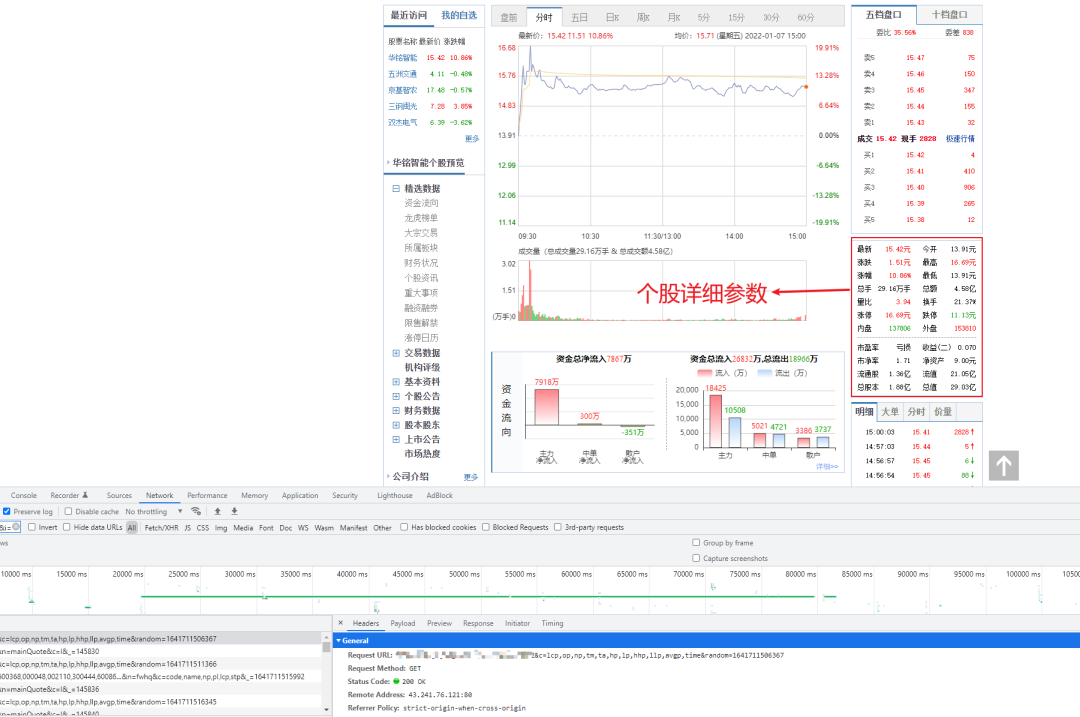
我们只需要请求接口,利用正则进行匹配获取个股中需要的数据参数即可
...
def __get_stock_info(self, concept_stock):
"""
获取个股的基本信息
:return:
"""
stock_name = concept_stock[0] # 股票名称
stock_tag = concept_stock[1] # 股票编号
url = self.stock_home.format(stock_tag)
# 编码问题
headers = {'User-Agent': UserAgent().random}
resp = self.session.get(self.stock_url.format(stock_tag, self.__get_time()),
headers=headers).text.replace('\n', '')
# 解析关键数据
resp_data = json.loads(re.findall(r'^.*HqData:(.*)};$', resp, re.IGNORECASE)[0])[0]
# print(resp_data)
# 获取股票关键信息
stock_price = resp_data[11] # 实时价格
# print(stock_price)
# 获取涨跌
stock_up_or_down = str(resp_data[19]) + "%" # 涨跌幅
# print("涨跌幅:", stock_up_or_down)
stock_num_ratio = resp_data[22] # 量比
# print(stock_num_ratio)
stock_change_ratio = str(resp_data[24]) + "%" # 换手率
# print(stock_change_ratio)
stock_pe = resp_data[-1] # 市盈率
# print(stock_pe)
return {
"name": stock_name,
"no": stock_tag,
"url": url,
"price": stock_price,
"up_or_down": stock_up_or_down,
"num_ratio": stock_num_ratio,
"change_ratio": stock_change_ratio,
"pe": stock_pe
}
...
最后,我们按照市盈率进行升序排列
...
# 4、按照市盈利排序(升序)
stocks.sort(key=lambda x: x["pe"])
# 5、打印
print(json.dumps(stocks))
...
# 5. 总结一下
在使用的时候,我们只需要传入「 相关概念关键字参数 」,就可以按市盈率升序排列后,返回相关概念股列表
当然,你也可以利用个股中的其他数据参数进行组合排序,获取适合自己的投资策略
我已将文中所有源码上传到下方公众号后台,关注公众号「 煎蛋搞钱 」后回复关键字「 220110 」即可以获取
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!

评论