
一次简单的Java服务性能优化,实现压测 QPS 翻倍
今日推荐 华为,被谷歌正式“除名”! 我的比特币爆仓了。。。 在国企当程序员是什么体验? 盘点 12 个 GitHub 上的高仿项目 CTO 说了,用错 @Autowired 和 @Resource 的人可以领盒饭了 用鸿蒙跑了个 hello world
背景
服务器高CPU、高负载
jtop,jtop 只是一个 jar 包,它的项目地址在 yujikiriki/jtop, 我们可以很方便地把它复制到服务器上,获取到 java 应用的 pid 后,使用 java -jar jtop.jar [options] <pid> 即可输出 JVM 内部统计信息。-stack n打印出最耗 CPU 的 5 种线程栈。Heap Memory: INIT=134217728 USED=230791968 COMMITED=450363392 MAX=1908932608
NonHeap Memory: INIT=2555904 USED=24834632 COMMITED=26411008 MAX=-1
GC PS Scavenge VALID [PS Eden Space, PS Survivor Space] GC=161 GCT=440
GC PS MarkSweep VALID [PS Eden Space, PS Survivor Space, PS Old Gen] GC=2 GCT=532
ClassLoading LOADED=3118 TOTAL_LOADED=3118 UNLOADED=0
Total threads: 608 CPU=2454 (106.88%) USER=2142 (93.30%)
NEW=0 RUNNABLE=6 BLOCKED=0 WAITING=2 TIMED_WAITING=600 TERMINATED=0
main TID=1 STATE=RUNNABLE CPU_TIME=2039 (88.79%) USER_TIME=1970 (85.79%) Allocted: 640318696
com.google.common.util.concurrent.RateLimiter.tryAcquire(RateLimiter.java:337)
io.zhenbianshu.TestFuturePool.main(TestFuturePool.java:23)
RMI TCP Connection(2)-127.0.0.1 TID=2555 STATE=RUNNABLE CPU_TIME=89 (3.89%) USER_TIME=85 (3.70%) Allocted: 7943616
sun.management.ThreadImpl.dumpThreads0(Native Method)
sun.management.ThreadImpl.dumpAllThreads(ThreadImpl.java:454)
me.hatter.tools.jtop.rmi.RmiServer.listThreadInfos(RmiServer.java:59)
me.hatter.tools.jtop.management.JTopImpl.listThreadInfos(JTopImpl.java:48)
sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
... ...
熔断框架优化
resilience4j 和阿里开源的 sentinel,但由于部门内技术栈是 Hystrix,而且它也没有明显的短板,就接着用下去了。响应时间不正常
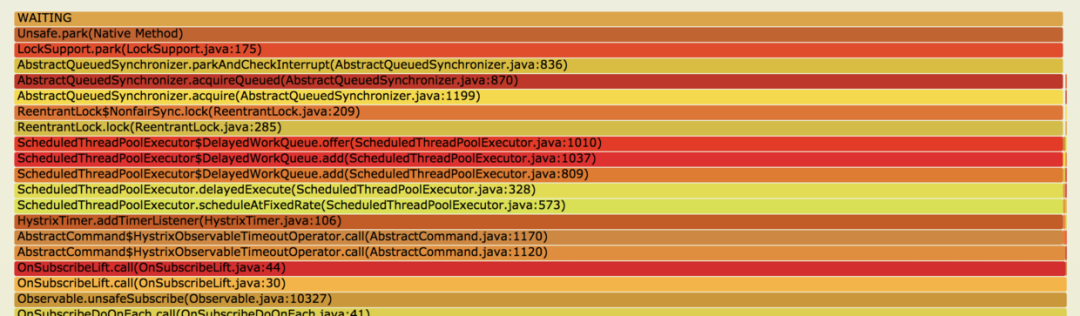
LockSupport.park(LockSupport.java:175) 处,这些线程都被锁住了,向下看来源发现是 HystrixTimer.addTimerListener(HystrixTimer.java:106), 再向下就是我们的业务代码了。@HystrixCommand(
fallbackMethod = "fallBackGetXXXConfig",
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "200"),
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50")},
threadPoolProperties = {
@HystrixProperty(name = "coreSize", value = "200"),
@HystrixProperty(name = "maximumSize", value = "500"),
@HystrixProperty(name = "allowMaximumSizeToDivergeFromCoreSize", value = "true")})
public XXXConfig getXXXConfig(Long uid) {
try {
return XXXConfigCache.get(uid);
} catch (Exception e) {
return EMPTY_XXX_CONFIG;
}
}
服务隔离和降级
hystrix-metrics-event-stream 包并添加一个接口来输出 Metrics 信息,再启动 hystrix-dashboard 客户端并填入服务端地址即可。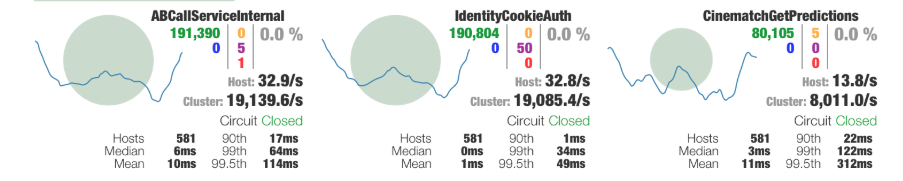
2000*50/1000=100 得到适合的信号量限制,如果被拒绝的错误数过多,可以再添加一些冗余。熔断时高负载导致无法恢复
Spring 数据绑定异常
at java.lang.Throwable.fillInStackTrace(Native Method)
at java.lang.Throwable.fillInStackTrace(Throwable.java:783)
- locked <0x00000006a697a0b8> (a org.springframework.beans.NotWritablePropertyException)
...
org.springframework.beans.AbstractNestablePropertyAccessor.processLocalProperty(AbstractNestablePropertyAccessor.java:426)
at org.springframework.beans.AbstractNestablePropertyAccessor.setPropertyValue(AbstractNestablePropertyAccessor.java:278)
...
at org.springframework.validation.DataBinder.doBind(DataBinder.java:735)
at org.springframework.web.bind.WebDataBinder.doBind(WebDataBinder.java:197)
at org.springframework.web.bind.ServletRequestDataBinder.bind(ServletRequestDataBinder.java:107)
at org.springframework.web.method.support.InvocableHandlerMethod.getMethodArgumentValues(InvocableHandlerMethod.java:161)
...
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:991)
List<PropertyAccessException> propertyAccessExceptions = null;
List<PropertyValue> propertyValues = (pvs instanceof MutablePropertyValues ?
((MutablePropertyValues) pvs).getPropertyValueList() : Arrays.asList(pvs.getPropertyValues()));
for (PropertyValue pv : propertyValues) {
try {
// This method may throw any BeansException, which won't be caught
// here, if there is a critical failure such as no matching field.
// We can attempt to deal only with less serious exceptions.
setPropertyValue(pv);
}
catch (NotWritablePropertyException ex) {
if (!ignoreUnknown) {
throw ex;
}
// Otherwise, just ignore it and continue...
}
... ...
}
@RequestMapping("test.json")
public Map testApi(@RequestParam(name = "id") String id, ApiContext apiContext) {}
小结
推荐文章
1、14个项目! 2、Spring Boot + Security + MyBatis + Thymeleaf + Activiti 快速开发平台项目 3、推荐几个支付项目! 4、写博客能月入10K? 5、一款基于 Spring Boot 的现代化社区(论坛/问答/社交网络/博客) 更多项目源码 1、推荐两个项目! 2、重磅推荐:一套开源的网校系统,无论是自建网校还是接副业都很方便 3、一款基于 Spring Boot 的现代化社区(论坛/问答/社交网络/博客) 4、13K点赞都基于 Vue+Spring 前后端分离管理系统ELAdmin,大爱 5、想接私活时薪再翻一倍,建议根据这几个开源的SpringBoot
评论