
漫谈Go语言编译器(01)
开场白
为什么学习编译器
虽然本系列的定位是科普文,但是我也不准备从最基本的正则表达式,语法树,有向图等最基础的知识讲起;因此假设读者有一定的知识基础。
在这个前提下,我希望你看过我在Gopher China 2020上的讲座,并阅读过PPT(https://github.com/gopherchina/conference/tree/master/2020)。
除此之外,我希望你阅读过柴树杉大神写的《Go语法树入门》(https://github.com/chai2010/go-ast-book),这是关于编译前端非常优秀的入门书籍。在此基础上,本系列的重点是讲解编译中端和后端。
坦白地说,编译器确实是最难入门的领域;同时也是最难写科普文的领域:专业人士看了觉得浅显,没相关基础的读者看了觉得云山雾罩。虽然如此,我还是想挑战一下。希望能收到读者更多反馈,我会据此调节讲解的内容。
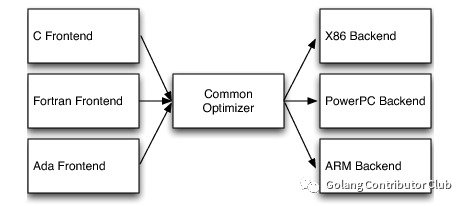
Go编译器在go-1.7之前,采用的是非常老旧的语法树(AST)覆盖的编译技术,从go-1.7开始逐步采用更主流的基于SSA-IR的前中后三阶段编译技术。虽然Go编译器无需支持别的高级编程语言,但是上述的第二点和第三点好处仍然适用。
一个额外的好处是,Go编译器的中端和后端被做成了独立的库"golang.org/x/tools/go/ssa"。这就意味着,你可以自己写一个新的语言前端(甚至不兼容Go语法),并调用Go的ssa库,生成可执行程序;甚至于你自己定义的编程语言可以无缝地调用其它Go的代码;进一步,你可以借助于Go的生态系统打造自己的编程语言!类似于Scala语言和Java语言的关系。
SSA-IR(Single Static Assignment)是一种介于高级语言和汇编语言的中间形态的伪语言,从高级语言角度看,它是(伪)汇编;而从真正的汇编语言角度看,它是(伪)高级语言。
顾名思义,SSA(Single Static Assignment)的两大要点是:
Static:每个变量只能赋值一次(因此应该叫常量更合适);
Single:每个表达式只能做一个简单运算,对于复杂的表达式a*b+c*d要拆分成:"t0=a*b; t1=c*d; t2=t0+t1;"三个简单表达式;
例如有如下Go源代码:
func foo(a, b int) int {c := 8return a*4 + b*c}
它改写成SSA形式是:
func foo(a, b int) int {c := 8t0 := a * 4t1 := b * ct2 := t0 + t1return t2}
func foo(a, b int) int {t0 := a << 2t1 := b << 3t2 := t0 + t1return t2}
func foo(a, b int) int {if (a > b) {return a + b} else {return a - b}
func foo(a, b int) int {c := a > bif (c) goto _true; else goto _false;_true:t0 := a + breturn t0_false:t1 := a - breturn t1}
Go编译器提供了完备的调试手段,正好我们可以借用过来展示Go编译器的内部工作流程。本系列文章使用go-1.14.15做演示,请读者安装此版本。
下面用一个例子test.go:
// test.gopackage mainfunc foo(a, b int) int {c := 8return a*4 + b*c}func main() {println(foo(100, 150))}
使用如下命令编译,在得到可执行目标程序的同时,还会得到一个额外的ssa.html,这个ssa.html就记录了Go编译器的工作流程和各阶段的中间结果。其中GOSSAFUNC环境变量用于指定需要被调试的函数,本例中是foo。
$ GOSSAFUNC=foo go build a.go# command-line-argumentsdumped SSA to ./ssa.html

其中,source和AST属于编译器前端,从start到writebarrier属于编译器中端,从lower到genssa属于编译器后端。
这其中的start/writebarrier/genssa三道工序的输出,请读者认真看一下。
start工序是编译器前端的最后一步,输出原始IR序列,请读者对照源码仔细体会。v10对应变量c,v11对应第一个乘法运算的乘数4,v12是第一个乘法的积,v13是第二个乘法的积,v14是加法的和。
startb1:v1 (?) = InitMem <mem>v2 (?) = SP <uintptr>v3 (?) = SB <uintptr>v4 (?) = LocalAddr <*int> {a} v2 v1v5 (?) = LocalAddr <*int> {b} v2 v1v6 (?) = LocalAddr <*int> {~r2} v2 v1v7 (4) = Arg <int> {a} (a[int])v8 (4) = Arg <int> {b} (b[int])v9 (?) = Const64 <int> [0]v10 (?) = Const64 <int> [8] (c[int])v11 (?) = Const64 <int> [4]v12 (6) = Mul64 <int> v7 v11v13 (6) = Mul64 <int> v8 v10v14 (6) = Add64 <int> v12 v13v15 (6) = VarDef <mem> {~r2} v1v16 (6) = Store <mem> {int} v6 v14 v15Ret v16 (+6)
writebarrier是编译器中端的最后一步,输出经通用优化后的IR序列。读者可以看到,最初的乘法运算(Mul64)被优化成了移位运算(Lsh64x64)。
writebarrier [549 ns]b1:v1 (?) = InitMem <mem>v2 (?) = SP <uintptr>v6 (?) = LocalAddr <*int> {~r2} v2 v1v7 (4) = Arg <int> {a} (a[int])v8 (4) = Arg <int> {b} (b[int])v15 (6) = VarDef <mem> {~r2} v1v9 (+6) = Const64 <uint64> [2]v5 (6) = Const64 <uint64> [3]v12 (+6) = Lsh64x64 <int> [false] v7 v9v13 (6) = Lsh64x64 <int> [false] v8 v5v14 (6) = Add64 <int> v12 v13v16 (6) = Store <mem> {int} v6 v14 v15Ret v16 (+6)
本文介绍了理解Go编译器的所需背景知识,以及Go编译器的整体工作流程。后续的文章会逐步针对上面的各道工序展开讲解。