
面试题:new String()创建几个对象?
常见面试问题
下面代码中创建了几个对象?
new String("abc");
答案众说纷纭,有说创建了1个对象,也有说创建了2个对象。答案对,也不对,关键是要学到问题底层的原理。
底层原理分析
在上篇文章《面试题系列第1篇:说说==和equals的区别?你的回答可能是错误的》中我们已经提到,String的两种初始化形式是有本质区别的。
String str1 = "abc"; // 在常量池中
String str2 = new String("abc"); // 在堆上
当直接赋值时,字符串“abc”会被存储在常量池中,只有1份,此时的赋值操作等于是创建0个或1个对象。如果常量池中已经存在了“abc”,那么不会再创建对象,直接将引用赋值给str1;如果常量池中没有“abc”,那么创建一个对象,并将引用赋值给str1。
那么,通过new String("abc");的形式又是如何呢?答案是1个或2个。
当JVM遇到上述代码时,会先检索常量池中是否存在“abc”,如果不存在“abc”这个字符串,则会先在常量池中创建这个一个字符串。然后再执行new操作,会在堆内存中创建一个存储“abc”的String对象,对象的引用赋值给str2。此过程创建了2个对象。
当然,如果检索常量池时发现已经存在了对应的字符串,那么只会在堆内创建一个新的String对象,此过程只创建了1个对象。
在上述过程中检查常量池是否有相同Unicode的字符串常量时,使用的方法便是String中的intern()方法。
public native String intern();
下面通过一个简单的示意图看一下String在内存中的两种存储模式。
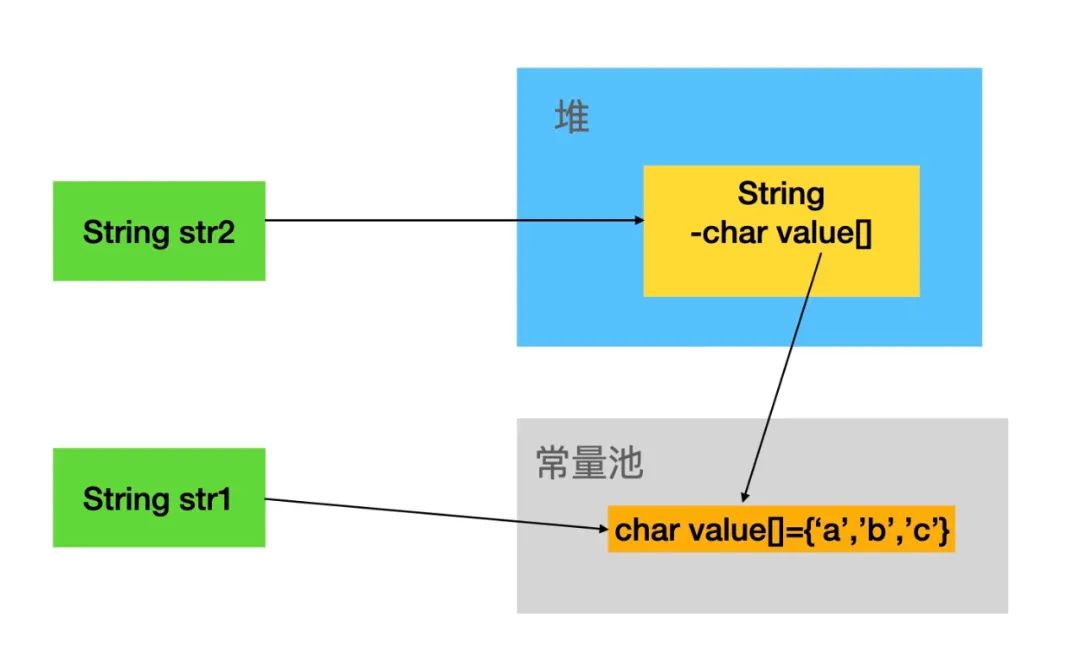
上面的示意图我们可以看到在堆内创建的String对象的char value[]属性指向了常量池中的char value[]。
还是上面的示例,如果我们通过debug模式也能够看到String的char value[]的引用地址。
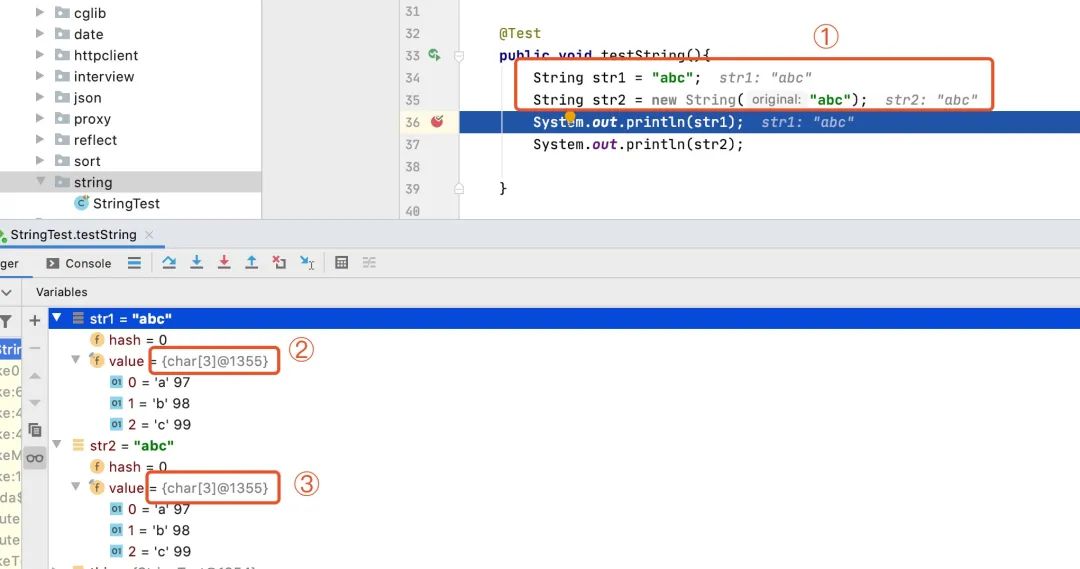
图中两个String对象的value值的引用均为{char[3]@1355},也就是说,虽然是两个对象,但它们的value值均指向常量池中的同一个地址。当然,大家还可以拿一个复杂对象(Person)的字符串属性(name)相同时的debug结果进行比对,结果是一样的。
深入问法
如果面试官说程序的代码只有下面一行,那么会创建几个对象?
new String("abc");
答案是2个?
还真不一定。之所以单独列出这个问题是想提醒大家一点:没有直接的赋值操作(str="abc"),并不代表常量池中没有“abc”这个字符串。也就是说衡量创建几个对象、常量池中是否有对应的字符串,不仅仅由你是否创建决定,还要看程序启动时其他类中是否包含该字符串。
升级加码
以下实例我们暂且不考虑常量池中是否已经存在对应字符串的问题,假设都不存在对应的字符串。
以下代码会创建几个对象:
String str = "abc" + "def";
上面的问题涉及到字符串常量重载“+”的问题,当一个字符串由多个字符串常量拼接成一个字符串时,它自己也肯定是字符串常量。字符串常量的“+”号连接Java虚拟机会在程序编译期将其优化为连接后的值。
就上面的示例而言,在编译时已经被合并成“abcdef”字符串,因此,只会创建1个对象。并没有创建临时字符串对象abc和def,这样减轻了垃圾收集器的压力。
我们通过javap查看class文件可以看到如下内容。 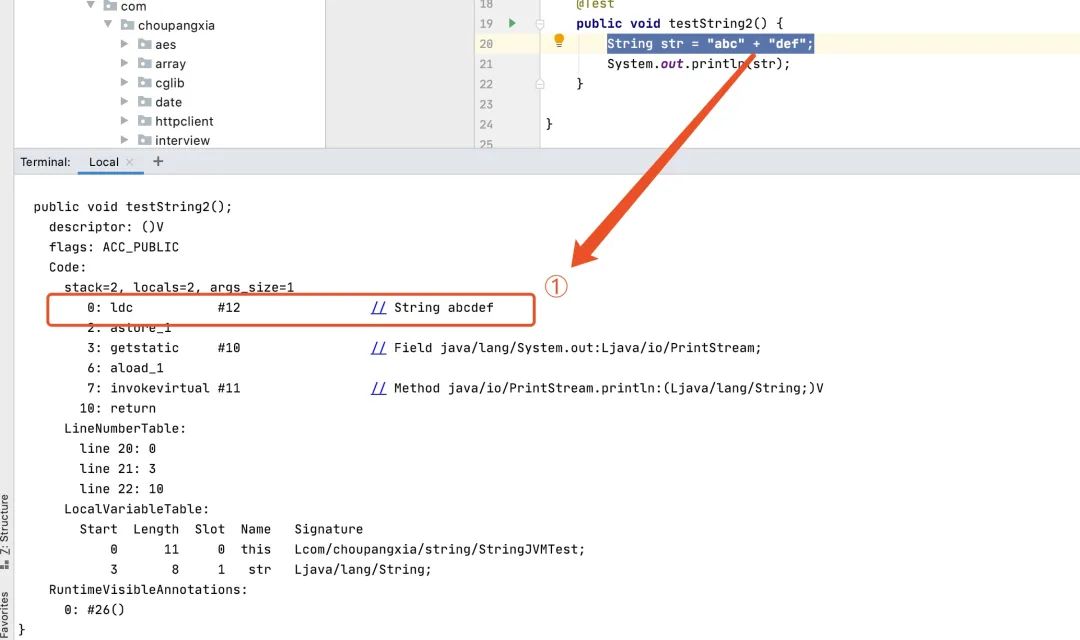 很明显,字节码中只有拼接好的abcdef。
很明显,字节码中只有拼接好的abcdef。
针对上面的问题,我们再次升级一下,下面的代码会创建几个对象?
String str = "abc" + new String("def");
创建了4个,5个,还是6个对象?
4个对象的说法:常量池中分别有“abc”和“def”,堆中对象new String("def")和“abcdef”。
这种说法对吗?不完全对,如果说上述代码创建了几个字符串对象,那么可以说是正确的。但上述的代码Java虚拟机在编译的时候同样会优化,会创建一个StringBuilder来进行字符串的拼接,实际效果类似:
String s = new String("def");
new StringBuilder().append("abc").append(s).toString();
很显然,多出了一个StringBuilder对象,那就应该是5个对象。
那么创建6个对象是怎么回事呢?有同学可能会想了,StringBuilder最后toString()之后的“abcdef”难道不在常量池存一份吗?
这个还真没有存,我们来看一下这段代码:
@Test
public void testString3() {
String s1 = "abc";
String s2 = new String("def");
String s3 = s1 + s2;
String s4 = "abcdef";
System.out.println(s3==s4); // false
}
按照上面的分析,如果s1+s2的结果在常量池中存了一份,那么s3中的value引用应该和s4中value的引用是一样的才对。下面我们看一下debug的效果。
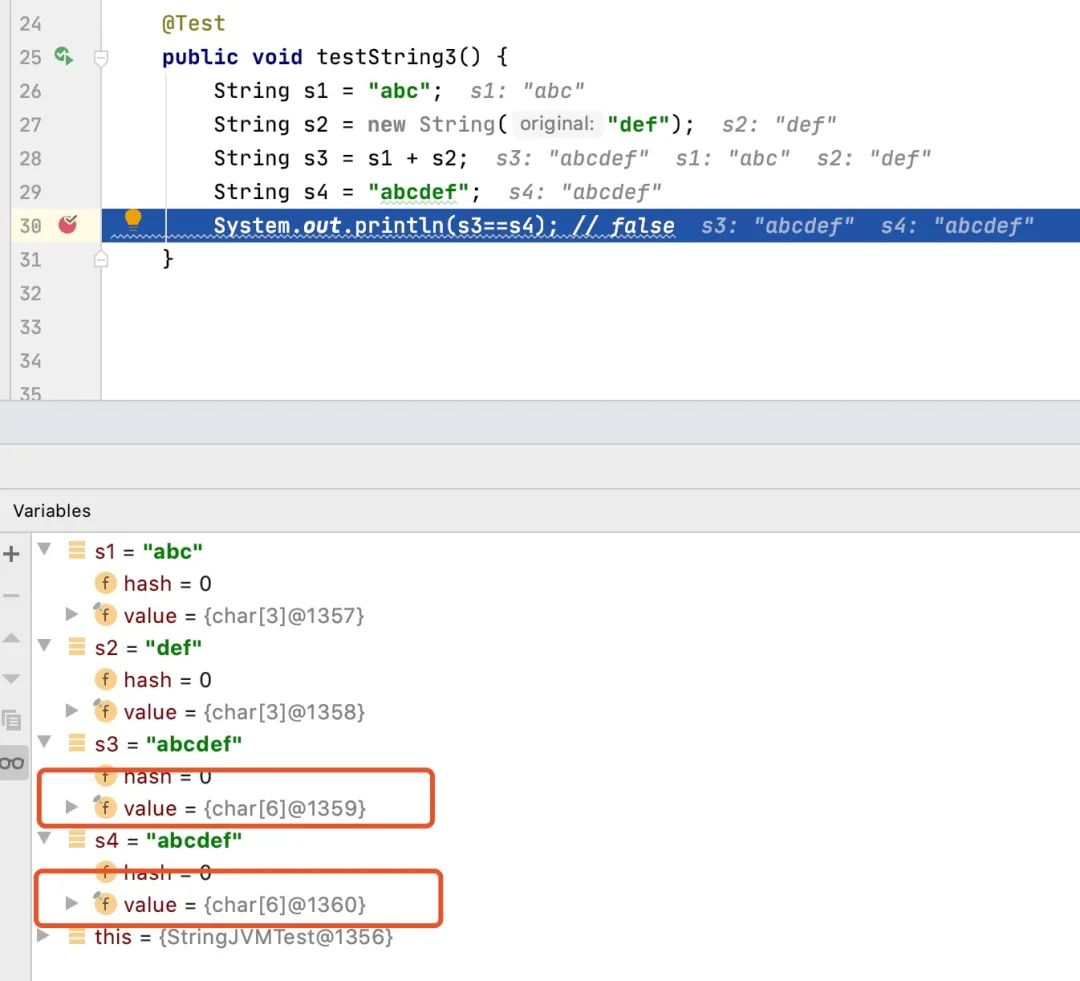
很明显,s3和s4的值相同,但value值的地址并不相同。即便是将s3和s4的位置调整一下,效果也一样。s4很明确是存在于常量池中,那么s3对应的值存储在哪里呢?很显然是在堆对象中。
我们来看一下StringBuilder的toString()方法是如何将拼接的结果转化为字符串的:
@Override
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
很显然,在toString方法中又新创建了一个String对象,而该String对象传递数组的构造方法来创建的:
public String(char value[], int offset, int count)
也就是说,String对象的value值直接指向了一个已经存在的数组,而并没有指向常量池中的字符串。
因此,上面的准确回答应该是创建了4个字符串对象和1个StringBuilder对象。
小结
我们通过一行创建字符串的代码逐步分析String对象的整个构建及拼接过程,了解了底层实现原理。是不是很有意思?当你掌握了这些底层基本知识,即便面试题的形式如何变化,你必定能一眼识破真相。