
一次流量不均衡问题的排查记录
讲一个这周排查的访问流量不均的事儿。
下游同学反馈我们的服务调用流量不均,最高的实例有 1k+ QPS,最低的才 400+ QPS,相差太大。
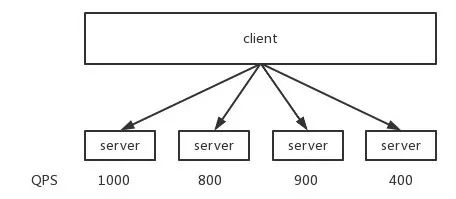 流量不均
流量不均于是拉了平台的 oncall,询问是否开了 mesh,没开。那就是框架的事了。
再拉框架的 oncall,询问是否自己加了流量均衡的策略,也没加。那就是用的默认的流量调度策略:“加权随机”。
什么是加权随机?
加权是指按节点权重进行流量分配,随机意味着相同权重下的实例随机选择。
去查下游各个 host 的 weight 值。发现确实有些 host 的 weight 值相差比较大。有的值是 10,有的值是 50。看起来是符合预期的。
这时又提出有两个 host 的 weight 值一样,但 QPS 相差 4 倍。
有同学说,直接去 access 日志里捞一下就行了。一行日志代表一个访问,积累出每秒钟的访问量,结果不就出来了吗?
grep '2021-11-20 10:01' xxx.log | awk '{print substr($3,1,8)}' | sort | uniq -c
结果会打印出在 10:01 这一分钟每秒的请求数,即 QPS。
果然,前面提到的这两台 host 访问量基本相同。看起来是监控打点出了问题。
找到其中 QPS 比较低的这一台机器,发现部署的 metricsserver CPU 受限很严重,说明丢了很多点,于是就造成了流量不均衡的假象。
之后找 metrics 的同学升级了套餐,上线完成之后,打点恢复正常。流量是均衡的。
这样一个简单的问题,还花费了一点时间。以后碰到类似的问题,第一时间看监控是否有问题。有些机器上的服务打点多,metricsserver 扛不住,丢点是在所难免的。
之前也碰到过几次打点不准的问题,查了半天,最后发现乌龙了。因此对于一些不太符合常理(例如本文的访问流量不均)的问题,先要确定打点没有问题。
评论