
【工程化】无用代码去哪了?项目减重之 rollup 的 Tree shaking
左琳,微医前端技术部前端开发工程师。身处互联网浪潮之中,热爱生活与技术。
Tip:本文所用 rollup 打包工具版本为 rollup v2.47.0。
从 Webpack2.x 通过插件逐步实现 tree-shaking,到最近炙手可热的 Vite 构建工具也借助了 rollup 的打包能力,众所周知 Vue 和 React 也是使用 rollup 进行打包的,尤其当我们创建函数库、工具库等库的打包时,首选也是 rollup!那么到底是什么魔力让 rollup 经久不衰呢?答案也许就在 tree-shaking!
一、 了解 Tree-shaking
1. 什么是 Tree-shaking?
tree-shaking 这个概念早就有,但却是在 rollup 中实现后才开始被重视,本着寻根究源好奇的心理,我们就先从 rollup 入手 tree-shaking 一探究竟吧~~
那么,先让我们来康康 tree-shaking 是干啥的?
打包工具中的 tree-shaking, 较早时候由 Rich_Harris 的 rollup 实现,官方标准说法:本质上消除无用的 JS 代码。就是说,当引入一个模块时,并不引入整个模块的所有代码,而是只引入我需要的代码,那些我不需要的无用代码就会被”摇“掉。
后面从 Webpack2 开始 Webpack 也实现了 tree-shaking 功能,具体来说,在 Webpack 项目中,有一个入口文件,相当于一棵树的主干,入口文件有很多依赖的模块,相当于树的枝杈。而在实际情况中,虽然我们的功能文件依赖了某个模块,但其实只使用其中的某些功能而非全部。通过 tree-shaking,将没有使用的模块摇掉,这样就可以达到删除无用代码的目的。
由此我们就知道了,tree-shaking 是一种消除无用代码的方式!
但要注意的是,tree-shaking 虽然能够消除无用代码,但仅针对 ES6 模块语法,因为 ES6 模块采用的是静态分析,从字面量对代码进行分析。对于必须执行到才知道引用什么模块的 CommonJS 动态分析模块他就束手无策了,不过我们可以通过插件支持 CommonJS 转 ES6 然后实现 tree-shaking,只要思想不滑坡,办法总比困难多。
总之,rollup.js 默认采用 ES 模块标准,但可以通过 rollup-plugin-commonjs 插件使之支持 CommonJS 标准,目前来说,在压缩打包体积方面,rollup 的优势相当明显!
2. 为什么需要 Tree-shaking?
今天的 Web 网页应用可以体积很大,尤其是 JavaScript 代码,但浏览器处理 JavaScript 是非常耗资源的,如果我们能将其中的无用代码去掉,仅提供有效代码给浏览器处理,无疑会大大减小浏览器的负担,而 tree-shaking 帮我们做到了这一点。
从这个角度看,tree-shaking 功能属于性能优化的范畴。
毕竟,减少 web 项目中 JavaScript 的无用代码,就是减小文件体积,加载文件资源的时间也就减少了,从而通过减少用户打开页面所需的等待时间,来增强用户体验。
二、深入理解 Tree-shaking
我们已经了解了 tree-shaking 的本质是消除无用的 js 代码。那么什么是无用代码?怎么消除无用代码?接下来让我们从 DCE 开始揭开它神秘的面纱,一探究竟吧~
1. DCE(dead code elimination)
无用代码在我们的代码中其实十分常见,消除无用代码也就拥有了自己的专业术语 - dead code elimination(DCE)。实际上,编译器可以判断出哪些代码并不影响输出,然后消除这些代码。
tree-shaking 是 DCE 的一种新的实现,Javascript 同传统的编程语言不同的是,javascript 绝大多数情况需要通过网络进行加载,然后执行,加载的文件大小越小,整体执行时间更短,所以去除无用代码以减少文件体积,对 javascript 来说更有意义。tree-shaking 和传统的 DCE 的方法又不太一样,传统的 DCE 消灭不可能执行的代码,而 tree-shaking 更关注消除没有用到的代码。
DCE
代码不会被执行,不可到达 代码执行的结果不会被用到 代码只会影响死变量,只写不读
传统编译型的预言都是由编译器将 Dead Code 从 AST (抽象语法树)中删除,了解即可。那么 tree-shaking 是如何 消除 javascript 无用代码的呢?
tree-shaking 更关注于消除那些引用了但并没有被使用的模块,这种消除原理依赖于 ES6 的模块特性。所以先来了解一下 ES6 模块特性:
ES6 Module
只能作为模块顶层的语句出现 import 的模块名只能是字符串常量 import binding 是 immutable 的
了解了这些前提,让我们动手用代码来验证下吧!
2. Tree-shaking 消除
tree-shaking 的使用前面已经介绍过,接下来的实验中,创建了 index.js 作为入口文件,打包生成代码到 bundle.js 中,除此之外的 a.js、util.js 等文件均作为被引用的依赖模块。
1) 消除变量

从上图中可以看到,我们定义的变量 b 和变量 c 都没有使用到,它们并没有出现在打包后的文件中。
2) 消除函数
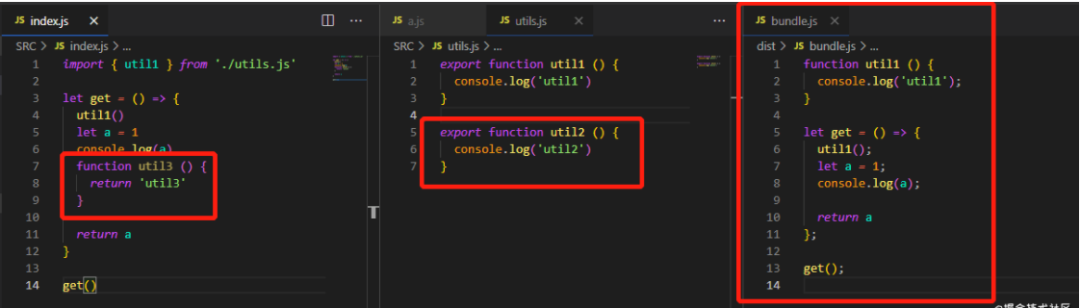
从上图中可以看到,仅引入但未使用到的 util1()和 util2()函数方法并没有打包进来。
3) 消除类
仅增加引用但不调用时

只引用类文件 mixer.js 但实际代码中并未用到 menu 的任何方法和变量时,我们通过实验可以看到,在新版本的 rollup 中消除类方法已经被实现了!
4) 副作用
但是,并不是说所有的副作用都被 rollup 解决了。参考相关文章,相对于 Webpack,rollup 在消除副作用方面有很大优势。但对于下列情况下的副作用,rollup 也无能为力:
1)模块中类的方法未被引用
2)模块中定义的变量影响了全局变量
参考下图,可以很清晰看到结果,大家也可以自己到rollup 官网提供的平台动手实践一下,:
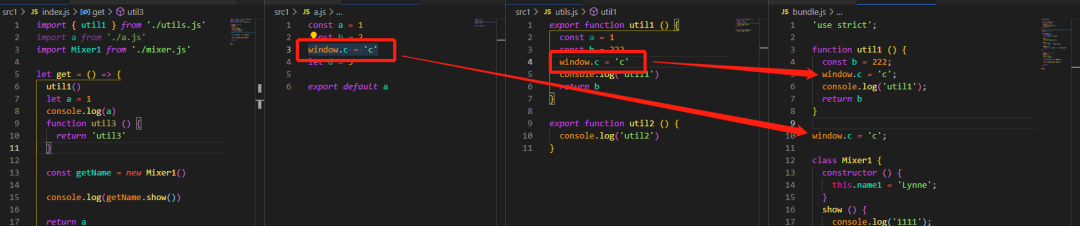
小结
从上述打包结果我们可以看到,rollup 工具用于打包是非常轻量简洁的,从入口文件导入依赖模块到输出打包后的 bundle 文件,只保留了需要的代码。也就是说,在 rollup 打包中无需增加额外配置,只要你的代码符合 ES6 语法规范,就能实现 tree-shaking。Nice!
那么,这个打包过程中的 tree-shaking 大概可以理解为必须具备以下两个关键实现:
ES6 的模块引入是静态分析的,可以在编译时正确判断到底加载了什么代码。 分析程序流,判断哪些变量被使用、引用,打包这些代码。
而 tree-shaking 的核心就包含在这个分析程序流的过程中:基于作用域,在 AST 过程中对函数或全局对象形成对象记录,然后在整个形成的作用域链对象中进行匹配 import 导入的标识,最后只打包匹配的代码,而删除那些未被匹配使用的代码。
但同时,我们也要注意两点:
尽可能少写包含副作用的代码,比如影响全局变量的这种操作尽可能避免; 引用类实例化后,也会产生 rollup 处理不了的副作用。
那么这个生成记录、匹配标识在程序流分析过程是如何实现的呢?
接下来带你走进源码,一探究竟!
三、 Tree-shaking 实现流程
在解析流程中的 tree-shaking 实现之前,我们首先要了解两点前置知识:
rollup 中的 tree-shaking 使用 acorn 实现 AST 抽象语法树的遍历解析,acorn 和 babel 功能相同,但 acorn 更加轻量,在此之前 AST 工作流也是必须要了解的; rollup 使用 magic-string 工具操作字符串和生成 source-map。
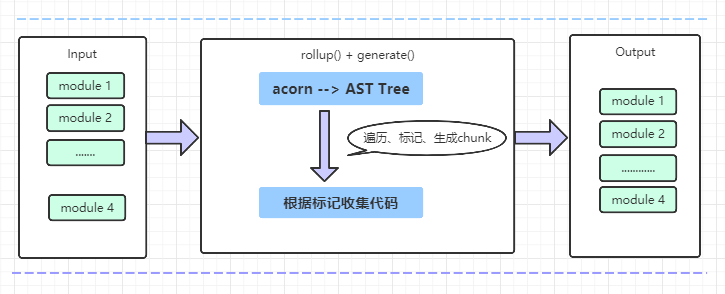
让我们从源码出发根据 tree-shaking 的核心原理详细地描述一下具体流程:
rollup()阶段,解析源码,生成 AST tree,对 AST tree 上的每个节点进行遍历,判断出是否 include(标记避免重复打包),是的话标记,然后生成 chunks,最后导出。 generate()/write()阶段,根据 rollup()阶段做的标记,进行代码收集,最后生成真正用到的代码。
拿到源码 debug 起来~
// perf-debug.js
loadConfig().then(async config => // 获取收集配置
(await rollup.rollup(config)).generate(
Array.isArray(config.output) ? config.output[0] : config.output
)
);
debug 时可能最为关注的就是这一段代码了,一句话就是将输入打包为输出,也正对应上述流程。
export async function rollupInternal(
rawInputOptions: GenericConfigObject, // 传入参数配置
watcher: RollupWatcher | null
): Promise<RollupBuild> {
const { options: inputOptions, unsetOptions: unsetInputOptions } = await getInputOptions(
rawInputOptions,
watcher !== null
);
initialiseTimers(inputOptions);
const graph = new Graph(inputOptions, watcher); // graph 包含入口以及各种依赖的相互关系,操作方法,缓存等,在实例内部实现 AST 转换,是 rollup 的核心
const useCache = rawInputOptions.cache !== false; // 从配置中取是否使用缓存
delete inputOptions.cache;
delete rawInputOptions.cache;
timeStart('BUILD', 1);
try {
// 调用插件驱动器方法,调用插件和提供插件环境上下文等
await graph.pluginDriver.hookParallel('buildStart', [inputOptions]);
await graph.build();
} catch (err) {
const watchFiles = Object.keys(graph.watchFiles);
if (watchFiles.length > 0) {
err.watchFiles = watchFiles;
}
await graph.pluginDriver.hookParallel('buildEnd', [err]);
await graph.pluginDriver.hookParallel('closeBundle', []);
throw err;
}
await graph.pluginDriver.hookParallel('buildEnd', []);
timeEnd('BUILD', 1);
const result: RollupBuild = {
cache: useCache ? graph.getCache() : undefined,
closed: false,
async close() {
if (result.closed) return;
result.closed = true;
await graph.pluginDriver.hookParallel('closeBundle', []);
},
// generate - 将遍历标记处理过作为输出的抽象语法树生成新的代码
async generate(rawOutputOptions: OutputOptions) {
if (result.closed) return error(errAlreadyClosed());
// 第一个参数 isWrite 为 false
return handleGenerateWrite(
false,
inputOptions,
unsetInputOptions,
rawOutputOptions as GenericConfigObject,
graph
);
},
watchFiles: Object.keys(graph.watchFiles),
// write - 将遍历标记处理过作为输出的抽象语法树生成新的代码
async write(rawOutputOptions: OutputOptions) {
if (result.closed) return error(errAlreadyClosed());
// 第一个参数 isWrite 为 true
return handleGenerateWrite(
true,
inputOptions,
unsetInputOptions,
rawOutputOptions as GenericConfigObject,
graph
);
}
};
if (inputOptions.perf) result.getTimings = getTimings;
return result;
}
单从这一段代码当然看不出来什么,下面我们一起解读源码来梳理 rollup 打包流程并探究 tree-shaing 的具体实现,为了更简单粗暴直接地看懂打包流程,我们对于源码中的插件配置中一律略过,只分析功能过程实现的核心流程。
1. 模块解析
获取文件绝对路径
通过 resolveId()方法解析文件地址,拿到文件绝对路径,拿到绝对路径是我们的主要目的,更为细节的处理此处不作分析。
export async function resolveId(
source: string,
importer: string | undefined,
preserveSymlinks: boolean,) {
// 不是以 . 或 / 开头的非入口模块在此步骤被跳过
if (importer !== undefined && !isAbsolute(source) && source[0] !== '.') return null;
// 调用 path.resolve,将合法文件路径转为绝对路径
return addJsExtensionIfNecessary(
importer ? resolve(dirname(importer), source) : resolve(source),
preserveSymlinks
);
}
// addJsExtensionIfNecessary() 实现
function addJsExtensionIfNecessary(file: string, preserveSymlinks: boolean) {
let found = findFile(file, preserveSymlinks);
if (found) return found;
found = findFile(file + '.mjs', preserveSymlinks);
if (found) return found;
found = findFile(file + '.js', preserveSymlinks);
return found;
}
// findFile() 实现
function findFile(file: string, preserveSymlinks: boolean): string | undefined {
try {
const stats = lstatSync(file);
if (!preserveSymlinks && stats.isSymbolicLink())
return findFile(realpathSync(file), preserveSymlinks);
if ((preserveSymlinks && stats.isSymbolicLink()) || stats.isFile()) {
const name = basename(file);
const files = readdirSync(dirname(file));
if (files.indexOf(name) !== -1) return file;
}
} catch {
// suppress
}
}
rollup()阶段
rollup() 阶段做了很多工作,包括收集配置并标准化、分析文件并编译源码生成 AST、生成模块并解析依赖,最后生成 chunks。为了搞清楚 tree-shaking 作用的具体位置,我们需要解析更内层处理的代码。
首先,通过从入口文件的绝对路径出发找到它的模块定义,并获取这个入口模块所有的依赖语句并返回所有内容。
private async fetchModule(
{ id, meta, moduleSideEffects, syntheticNamedExports }: ResolvedId,
importer: string | undefined, // 导入此模块的引用模块
isEntry: boolean // 是否入口路径
): Promise<Module> {
...
// 创建 Module 实例
const module: Module = new Module(
this.graph, // Graph 是全局唯一的图,包含入口以及各种依赖的相互关系,操作方法,缓存等
id,
this.options,
isEntry,
moduleSideEffects, // 模块副作用
syntheticNamedExports,
meta
);
this.modulesById.set(id, module);
this.graph.watchFiles[id] = true;
await this.addModuleSource(id, importer, module);
await this.pluginDriver.hookParallel('moduleParsed', [module.info]);
await Promise.all([
// 处理静态依赖
this.fetchStaticDependencies(module),
// 处理动态依赖
this.fetchDynamicDependencies(module)
]);
module.linkImports();
// 返回当前模块
return module;
}
分别在fetchStaticDependencies(module),和fetchDynamicDependencies(module)中进一步处理依赖模块,并返回依赖模块的内容。
private fetchResolvedDependency(
source: string,
importer: string,
resolvedId: ResolvedId
): Promise<Module | ExternalModule> {
if (resolvedId.external) {
const { external, id, moduleSideEffects, meta } = resolvedId;
if (!this.modulesById.has(id)) {
this.modulesById.set(
id,
new ExternalModule( // 新建外部 Module 实例
this.options,
id,
moduleSideEffects,
meta,
external !== 'absolute' && isAbsolute(id)
)
);
}
const externalModule = this.modulesById.get(id);
if (!(externalModule instanceof ExternalModule)) {
return error(errInternalIdCannotBeExternal(source, importer));
}
// 返回依赖的模块内容
return Promise.resolve(externalModule);
} else {
// 存在导入此模块的外部引用,则递归获取这个入口模块所有的依赖语句
return this.fetchModule(resolvedId, importer, false);
}
}
每个文件都是一个模块,每个模块都会有一个 Module 实例。在 Module 实例中,模块文件的代码通过 acorn 的 parse 方法遍历解析为 AST 语法树。
const ast = this.acornParser.parse(code, {
...(this.options.acorn as acorn.Options),
...options
});
最后将 source 解析并设置到当前 module 上,完成从文件到模块的转换,并解析出 ES tree node 以及其内部包含的各类型的语法树。
setSource({
alwaysRemovedCode,
ast,
code,
customTransformCache,
originalCode,
originalSourcemap,
resolvedIds,
sourcemapChain,
transformDependencies,
transformFiles,
...moduleOptions
}: TransformModuleJSON & {
alwaysRemovedCode?: [number, number][];
transformFiles?: EmittedFile[] | undefined;
}) {
this.info.code = code;
this.originalCode = originalCode;
this.originalSourcemap = originalSourcemap;
this.sourcemapChain = sourcemapChain;
if (transformFiles) {
this.transformFiles = transformFiles;
}
this.transformDependencies = transformDependencies;
this.customTransformCache = customTransformCache;
this.updateOptions(moduleOptions);
timeStart('generate ast', 3);
this.alwaysRemovedCode = alwaysRemovedCode || [];
if (!ast) {
ast = this.tryParse();
}
this.alwaysRemovedCode.push(...findSourceMappingURLComments(ast, this.info.code));
timeEnd('generate ast', 3);
this.resolvedIds = resolvedIds || Object.create(null);
this.magicString = new MagicString(code, {
filename: (this.excludeFromSourcemap ? null : fileName)!, // 不包括 sourcemap 中的辅助插件
indentExclusionRanges: []
});
for (const [start, end] of this.alwaysRemovedCode) {
this.magicString.remove(start, end);
}
timeStart('analyse ast', 3);
// ast 上下文环境,包装一些方法,比如动态导入、导出等,东西很多,大致看一看
this.astContext = {
addDynamicImport: this.addDynamicImport.bind(this), // 动态导入
addExport: this.addExport.bind(this),
addImport: this.addImport.bind(this),
addImportMeta: this.addImportMeta.bind(this),
code,
deoptimizationTracker: this.graph.deoptimizationTracker,
error: this.error.bind(this),
fileName,
getExports: this.getExports.bind(this),
getModuleExecIndex: () => this.execIndex,
getModuleName: this.basename.bind(this),
getReexports: this.getReexports.bind(this),
importDescriptions: this.importDescriptions,
includeAllExports: () => this.includeAllExports(true), // include 相关方法标记决定是否 tree-shaking
includeDynamicImport: this.includeDynamicImport.bind(this), // include...
includeVariableInModule: this.includeVariableInModule.bind(this), // include...
magicString: this.magicString,
module: this,
moduleContext: this.context,
nodeConstructors,
options: this.options,
traceExport: this.getVariableForExportName.bind(this),
traceVariable: this.traceVariable.bind(this),
usesTopLevelAwait: false,
warn: this.warn.bind(this)
};
this.scope = new ModuleScope(this.graph.scope, this.astContext);
this.namespace = new NamespaceVariable(this.astContext, this.info.syntheticNamedExports);
// 实例化 Program,将 ast 上下文环境赋给当前模块的 ast 属性上
this.ast = new Program(ast, { type: 'Module', context: this.astContext }, this.scope);
this.info.ast = ast;
timeEnd('analyse ast', 3);
}
2. 标记模块是否可 Tree-shaking
继续处理当前 module,根据 isExecuted 的状态及 treeshakingy 相关配置进行模块以及 es tree node 的引入,isExecuted 为 true 意味着这个模块已被添加入结果,以后不需要重复添加,最后也是根据 isExecuted 收集所有需要的模块从而实现 tree-shaking。
// 以标记声明语句为例,includeVariable()、includeAllExports()方法不一一列出
private includeStatements() {
for (const module of [...this.entryModules, ...this.implicitEntryModules]) {
if (module.preserveSignature !== false) {
module.includeAllExports(false);
} else {
markModuleAndImpureDependenciesAsExecuted(module);
}
}
if (this.options.treeshake) {
let treeshakingPass = 1;
do {
timeStart(`treeshaking pass ${treeshakingPass}`, 3);
this.needsTreeshakingPass = false;
for (const module of this.modules) {
// 根据 isExecuted 进行标记
if (module.isExecuted) {
if (module.info.hasModuleSideEffects === 'no-treeshake') {
module.includeAllInBundle();
} else {
module.include(); // 标记
}
}
}
timeEnd(`treeshaking pass ${treeshakingPass++}`, 3);
} while (this.needsTreeshakingPass);
} else {
for (const module of this.modules) module.includeAllInBundle();
}
for (const externalModule of this.externalModules) externalModule.warnUnusedImports();
for (const module of this.implicitEntryModules) {
for (const dependant of module.implicitlyLoadedAfter) {
if (!(dependant.info.isEntry || dependant.isIncluded())) {
error(errImplicitDependantIsNotIncluded(dependant));
}
}
}
}
module.include 内部涉及到 ES tree node 了,由于 NodeBase 初始 include 为 false,所以还有第二个判断条件:当前 node 是否有副作用 side effects。这个是否有副作用是继承于 NodeBase 的各类 node 子类自身的实现,以及是否影响全局。rollup 内部不同类型的 es node 实现了不同的 hasEffects 实现,在不断优化过程中,对类引用的副作用进行了处理,消除引用却未使用的类,此处可结合第二章节中的 tree-shaking 消除进一步理解。
include(): void { / include()实现
const context = createInclusionContext();
if (this.ast!.shouldBeIncluded(context)) this.ast!.include(context, false);
}
3. treeshakeNode()方法
在源码中有 treeshakeNode()这样一个方法去除无用代码,调用的时候也清楚地备注了 --- 防止重复声明相同的变量/节点,通过 included 标记节点代码是否已被包含,是的情况下 tree-shaking,同时还提供 removeAnnotations()方法删除多余注释代码。
// 消除无用节点
export function treeshakeNode(node: Node, code: MagicString, start: number, end: number) {
code.remove(start, end);
if (node.annotations) {
for (const annotation of node.annotations) {
if (!annotation.comment) {
continue;
}
if (annotation.comment.start < start) {
code.remove(annotation.comment.start, annotation.comment.end);
} else {
return;
}
}
}
}
// 消除注释节点
export function removeAnnotations(node: Node, code: MagicString) {
if (!node.annotations && node.parent.type === NodeType.ExpressionStatement) {
node = node.parent as Node;
}
if (node.annotations) {
for (const annotation of node.annotations.filter((a) => a.comment)) {
code.remove(annotation.comment!.start, annotation.comment!.end);
}
}
}
调用 treeshakeNode()方法的时机很重要!在渲染前 tree-shaking 并递归地去渲染。
render(code: MagicString, options: RenderOptions, nodeRenderOptions?: NodeRenderOptions) {
const { start, end } = nodeRenderOptions as { end: number; start: number };
const declarationStart = getDeclarationStart(code.original, this.start);
if (this.declaration instanceof FunctionDeclaration) {
this.renderNamedDeclaration(
code,
declarationStart,
'function',
'(',
this.declaration.id === null,
options
);
} else if (this.declaration instanceof ClassDeclaration) {
this.renderNamedDeclaration(
code,
declarationStart,
'class',
'{',
this.declaration.id === null,
options
);
} else if (this.variable.getOriginalVariable() !== this.variable) {
// tree-shaking 以防止重复声明变量
treeshakeNode(this, code, start, end);
return;
// included 标识做 tree-shaking
} else if (this.variable.included) {
this.renderVariableDeclaration(code, declarationStart, options);
} else {
code.remove(this.start, declarationStart);
this.declaration.render(code, options, {
isCalleeOfRenderedParent: false,
renderedParentType: NodeType.ExpressionStatement
});
if (code.original[this.end - 1] !== ';') {
code.appendLeft(this.end, ';');
}
return;
}
this.declaration.render(code, options);
}
类似的地方还有几处,tree-shaking 就是在这些地方发光发热的!
// 果然我们又看到了 included
...
if (!node.included) {
treeshakeNode(node, code, start, end);
continue;
}
...
if (currentNode.included) {
currentNodeNeedsBoundaries
? currentNode.render(code, options, {
end: nextNodeStart,
start: currentNodeStart
})
: currentNode.render(code, options);
} else {
treeshakeNode(currentNode, code, currentNodeStart!, nextNodeStart);
}
...
4. 通过 chunks 生成代码(字符串)并写入文件
在 generate()/write()阶段,将经处理生成后的代码写入文件,handleGenerateWrite()方法内部生成了 bundle 实例进行处理。
async function handleGenerateWrite(...) {
...
// 生成 Bundle 实例,这是一个打包对象,包含所有的模块信息
const bundle = new Bundle(outputOptions, unsetOptions, inputOptions, outputPluginDriver, graph);
// 调用实例 bundle 的 generate 方法生成代码
const generated = await bundle.generate(isWrite);
if (isWrite) {
if (!outputOptions.dir && !outputOptions.file) {
return error({
code: 'MISSING_OPTION',
message: 'You must specify "output.file" or "output.dir" for the build.'
});
}
await Promise.all(
// 这里是关键:通过 chunkId 生成代码并写入文件
Object.keys(generated).map(chunkId => writeOutputFile(generated[chunkId], outputOptions))
);
await outputPluginDriver.hookParallel('writeBundle', [outputOptions, generated]);
}
return createOutput(generated);
}
小结
一句话概括来说就是:从入口文件出发,找出所有它读取的变量,找一下这个变量是在哪里定义的,把定义语句包含进来,而无关的代码一律抛弃,得到的即为我们想要的结果。
总结
本文基于对 rollup 源码对其打包过程中的 tree-shaking 原理进行解读,其实可以发现,针对简单的打包流程而言,源码中并未对代码做额外的神秘操作,只是做了遍历标记使用收集并对收集到的代码打包输出以及 included 标记节点 treeshakeNode 以避免重复声明而已。
当然最关键的还是内部静态分析并收集依赖,这个过程处理起来比较复杂,但核心其实还是针对遍历节点:找到当前节点依赖的变量,访问的变量以及这些变量的声明语句。
作为一个轻量快捷的打包工具,rollup 在打包函数工具库方便具有很大优势。归功于其偏向于代码处理的优势,源码体量相较于 Webpack 也是轻量得多,但菜鸡本菜如我依然觉得读源码是一个枯燥的过程...
但是!如果仅仅是本着弄懂原理的目的,不妨先只关注核心代码流程,边边角角的细节放在后面,也许能增强阅读愉悦体验、加快攻略源码的步伐!
参考资料
Tree-Shaking 与无效代码消除 Tree-Shaking 性能优化实践 - 原理篇 你的 Tree-Shaking 并没什么卵用 原来 rollup 这么简单之 tree shaking 篇