
面试必问的缓存使用:如何保证数据一致性、缓存设计模式
前言
缓存使用在现在的项目中非常常见,缓存在为我们带来便利的同时,也会带来一些常见的问题,如果不谨慎使用,可能会带来意想不到的结果。
面试中,缓存使用带来的各种问题也是面试官喜欢考察的点,今天我将跟大家一起探讨以下几个常见的问题:
如何保证数据库和缓存的数据一致性?
先操作数据库 or 先操作缓存?
失效缓存 or 更新缓存?
缓存的常见设计模式有哪些?
正文
缓存查询通用流程
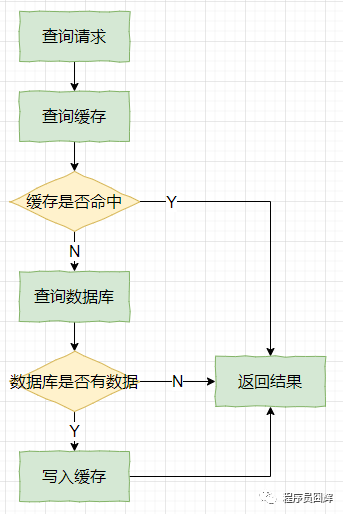
这个缓存查询流程相信大家都不陌生,这应该是目前应用最广的缓存查询流程。
但是大部分人可能不知道,这个流程其实有一个名字:Cache Aside Pattern,这是缓存设计模式的一种。
上图是 Cache Aside Pattern 的查询流程,而更新流程如下。
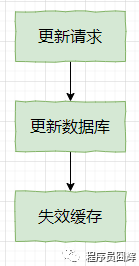
这个更新流程会引出两个问题:
1)为什么是先操作数据库,可以先操作缓存吗?
2)为什么是失效缓存,可以更新缓存吗?
接下来我们一一分析。
先操作数据库 or 先操作缓存
先操作数据库
案例如下,有两个并发的请求,一个写请求,一个读请求,流程如下:
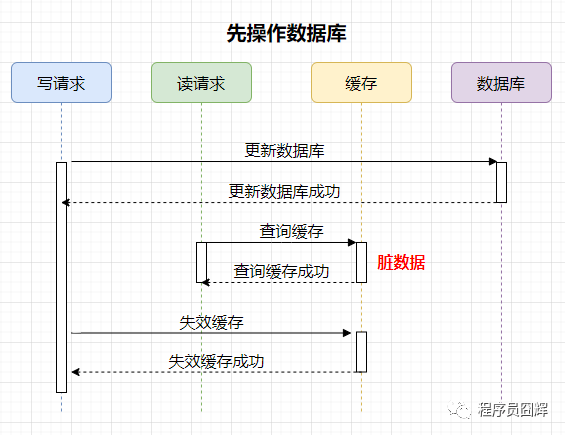
脏数据时间范围:更新数据库后,失效缓存前。这个时间范围很小,通常不会超过几毫秒。
先操作缓存
案例如下,有两个并发的请求,一个写请求,一个读请求,流程如下:
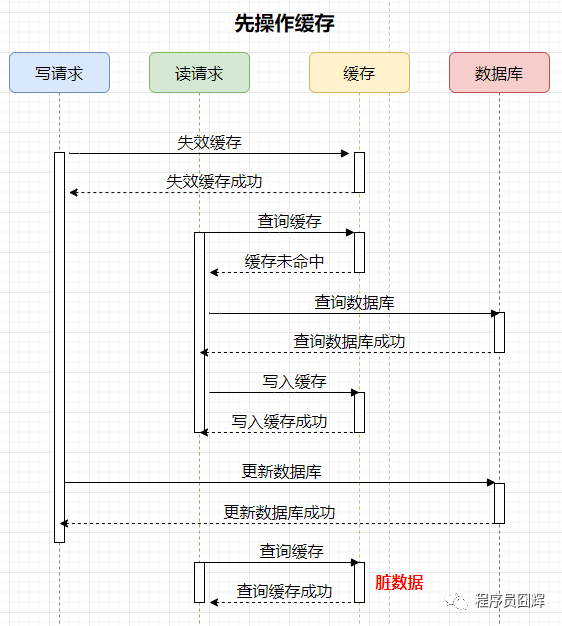
脏数据时间范围:更新数据库后,下一次对该数据的更新前。这个时间范围不确定性很大,情况如下:
1)如果下一次对该数据的更新马上就到来,那么会失效缓存,脏数据的时间就很短。
2)如果下一次对该数据的更新要很久才到来,那这期间缓存保存的一直是脏数据,时间范围很长。
结论:通过上述案例可以看出,先操作数据库和先操作缓存都会存在脏数据的情况。但是相比之下,先操作数据库,再操作缓存是更优的方式,即使在并发极端情况下,也只会出现很小量的脏数据。
失效缓存 or 更新缓存
更新缓存
案例如下,有两个并发的写请求,流程如下:
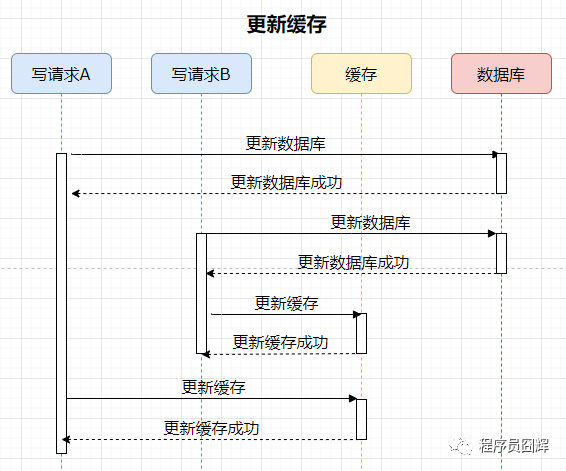
分析:数据库中的数据是请求B的,缓存中的数据是请求A的,数据库和缓存存在数据不一致。
失效缓存
案例如下,有两个并发的写请求,流程如下:

分析:由于是删除缓存,所以不存在数据不一致的情况。
结论:通过上述案例,可以很明显的看出,失效缓存是更优的方式。
如何保证数据库和缓存的数据一致性
在上文的案例中,无论是先操作数据库,还是先操作缓存,都会存在脏数据的情况,有办法避免吗?
答案是有的,由于数据库和缓存是两个不同的数据源,要保证其数据一致性,其实就是典型的分布式事务场景,可以引入分布式事务来解决,常见的有:2PC、TCC、MQ事务消息等。
但是引入分布式事务必然会带来性能上的影响,这与我们当初引入缓存来提升性能的目的是相违背的。
所以在实际使用中,通常不会去保证缓存和数据库的强一致性,而是做出一定的牺牲,保证两者数据的最终一致性。
如果是实在无法接受脏数据的场景,则比较合理的方式是放弃使用缓存,直接走数据库。
保证数据库和缓存数据最终一致性的常用方案如下:
1)更新数据库,数据库产生 binlog。
2)监听和消费 binlog,执行失效缓存操作。
3)如果步骤2失效缓存失败,则引入重试机制,将失败的数据通过MQ方式进行重试,同时考虑是否需要引入幂等机制。

兜底:当出现未知的问题时,及时告警通知,人为介入处理。
人为介入是终极大法,那些外表看着光鲜艳丽的应用,其背后大多有一群苦逼的程序员,在不断的修复各种脏数据和bug。

上文我们聊到了缓存设计模式中的 Cache Aside,并对常见的问题进行了延伸。
接着,我们来聊下缓存设计模式的其他几种:Read Through、Write Through、Write Behind Caching。
Read/Write Through
在 Cache Aside 中,应用层需要和两个数据源打交道:缓存、数据库,这增加了 应用层的复杂度,能否只和一个数据源打交道?
Read/Write Through 就是用来解决这个问题的,该模式下应用层只和缓存打交道,由缓存去操作和维护数据库。
该模式会让应用层变得更加简单,同时代码也会更简洁。
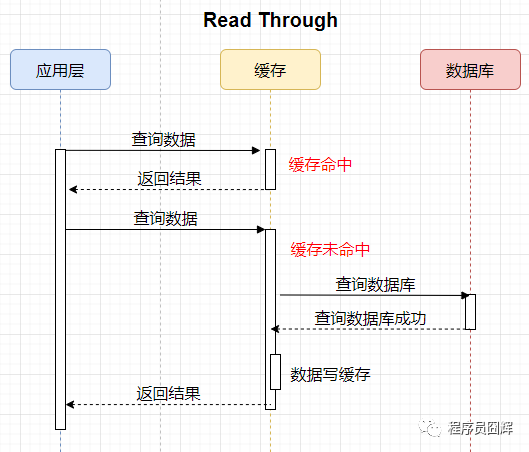
Read Through
应用层查询数据时,当缓存未命中时,由缓存去查询数据库,并且将结果写入缓存中,最后返回结果给应用层。
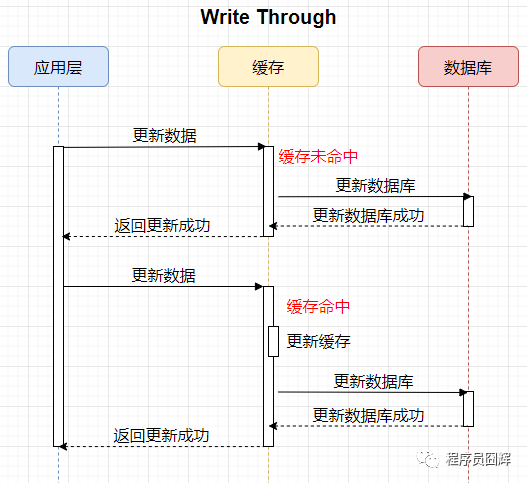
Write Through
应用层更新数据时,由缓存去更新数据库。同时,当缓存命中时,写缓存和写数据库需要同步控制,保证同时成功。
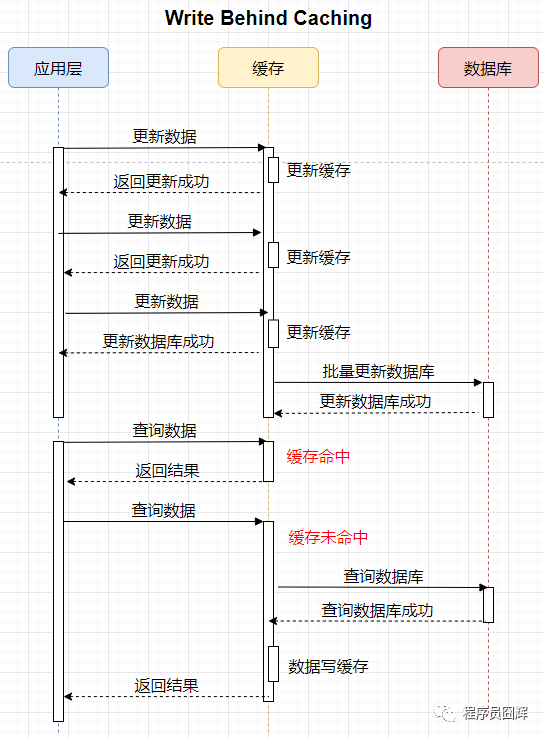
Write Behind Caching
Write Behind 又称为 Write Back,从应用层的视角来看和 Write Through 类似,在该模式下,应用层也是只需要和缓存一个数据源打交道,不同点在于:
Write Through 会立刻把数据同步写入数据库中,这样做的优点是操作简单,缺点是数据修改需要同时写入数据库,数据写入速度会比较慢。
Write Behind 会在一段时间之后异步的把数据批量写入数据库,这样的做的优点是:1)应用层操作只写缓存,应用层会觉得操作飞快无比;2)缓存在异步的写入数据库时,会将多个 I/O 操作合并成一个,减少 I/O 次数。
缺点是:1)复杂度高;2)更新后的数据还未写入数据库时,如果此时出现系统断电的情况,数据将无法找回。
Write Behind 的核心流程图如下:
Write Back 缓存模式由于其复杂性比较高,所以在业务应用中使用的比较少,但是由于其带来的性能提升,还是有不少优秀的软件采用了该设计模式,例如:linux 中的页缓存、MySQL 中的 InnoDB 存储引擎。
linux 中的 page cache(页缓存)采用的就是 write back 机制:用户 write 时只是将数据写到 page cache,并标记为 dirty,并没有真正写到硬盘上 。内核在某个时刻会将 page cache 里的 dirty 数据 wirteback 到硬盘上。
wikipedia 上有一张 Write Back 的流程图,如下,图中的 lower memory 可以简单的理解为数据库(硬盘):

最后
最近我将自己的原创文章整理分类了一下,可以在我公众号底部的“原创汇总”查看。
当你的才华还撑不起你的野心的时候,你就应该静下心来学习,愿你在我这里能有所收获。
原创不易,如果你觉得本文写的还不错,对你有帮助,请通过【点赞】让我知道,支持我写出更好的文章。
推荐阅读
5 年 Java 经验字节、美团、快手核心部门面试总结(真题解析)