React 进阶必备:从函数式组件看 Hooks 设计原理(收藏!)
从函数式说起
React 在现有的三大主流框架中是非常“函数式”的语言,小到 setState,render 函数的设计,大到函数组件,周边组件 Redux 等,都蕴含了一定的函数式风格。因此要了解 React,我们就需要了解一定的函数式编程。
函数式编程作为声明式编程的一种形式,与命令式编程相对,来源于范畴论,最早是为了解决数学问题而诞生。范畴论认为,同一个范畴的所有成员,就是不同状态的"变形",通过态射,一个成员可以变形成另一个成员。
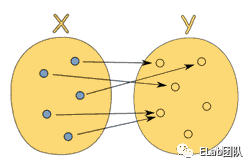
我们可以把物件理解为集合,态射理解为函数,通过函数,来规定范畴中成员之间的关系,函数扮演管道的角色,一个值进去,一个新值出来,没有其他副作用,也就是所谓的 y = f(x)。
函数式风格包含了多种特性,典型的如函数一等公民、纯函数、副作用、柯里化、组合等,这里我们主要以基础的纯函数和副作用做进一步解释。
纯函数
纯函数 ——输入输出数据流全是显式的。
显式的意思是,函数与外界交换数据只有一个唯一渠道——参数和返回值;函数从函数外部接受的所有输入信息都通过参数传递到该函数内部;函数输出到函数外部的所有信息都通过返回值传递到该函数外部。
相同的输入,永远得到相同的输出,而且没有任何副作用,与环境变量无关,可以在任意地方调用。
//splice是不纯的函数
let arr = [1,2,3,4,5];
arr.splice(0,3); //[1,2,3]
arr.splice(0,3); //[4,5]
//slice是纯函数
arr = [1,2,3,4,5];
arr.slice(0,3); //[1,2,3]
arr.slice(0,3); //[1,2,3]
副作用
在计算机科学中,函数副作用指当调用函数时,除了返回函数值之外,还对主调用函数产生附加的影响。例如修改全局变量(函数外的变量),修改参数或改变外部存储。
典型的副作用:
发送一个http请求
new Date() / Math.random();
console.log / IO
DOM查询 (外部数据)
然而,只有纯函数而无副作用的程序,在程序运行完毕后,不留一丝痕迹,仅仅只是空耗 CPU 而已,因此,副作用是必要的。在函数式语言中,为了保证函数的尽可能纯粹性,副作用使用函子进行统一管理。这里我们不去深究函子的原理,我们需要记住的是:尽可能保持函数的纯粹性,将副作用收拢统一管理。
追溯历史 - Hook 诞生背景
React 组件
React 组件根据书写形式分为函数组件和类组件。
class ComponentA extends React.Component {
constructor(props) {
super(props);
this.state = { displayContent: 'Hello World' }
}
render() {
return <div>{this.state.displayContent}</div>
}
}
function ComponentFunctionA = (props) => <div>{props.displayContent}</div>
函数组件定位为展示组件,自身无状态,无生命周期。
类组件定位为容器组件,自身管理状态与生命周期。
问题
函数组件想管理状态、生命周期
随着需求变更,在未作出良好设计的情况下。常会出现本是函数的组件处于功能内聚性等因素想管理状态的情况。
解决方案:
改为类组件
提升状态至上层容器
然而,改为类组件需要一定的人力成本;而数据提升至上层容器,既有可能会增加 React 组件层级结构,又丧失了组件功能的内聚性,都不能认为是良好的解决方案。
类组件生命周期带来逻辑分离
class DemoA extends React.PureComponent {
constructor(props) {
super(props);
this.listener = () => {/* do something */};
}
componentDidMount() {
document.addEventListener('click', this.listener);
}
componentWillUnmount() {
document.removeEventListener('click', this.listener);
}
}
这里只是一个简单的例子,展示了由于生命周期的存在,需要我们将一个事件的监听和取消逻辑分别置于不同生命周期内。一旦逻辑复杂,极易导致遗漏这类对事件,数据的清理工作,从而造成内存泄漏甚至逻辑错误。
逻辑抽象复用
| 方案 | 优点 | 缺点 |
|---|---|---|
| Mixin | 使用简单方便 灵活 | 维护性差容易 mixin 覆盖 |
| HOC | 解决了class不能使用 mixin 问题 | 拥有额外组件层级属性来源不定,容易属性覆盖 |
| Render Props | 明确来源,解决了属性覆盖问题 | 额外组件层级可读性差 |
| Hook | 消除额外组件层级可读性高,适用逻辑抽象数据来源输出明确 | 依赖管理闭包问题 |
class 本身的问题,比如不能很好的压缩,在热重载时会出现不稳定的情况
解决问题 - Hook 设计
通过 Hook 方式,React 为函数组件引入了可管理副作用的 useState、useEffect、useMemo 等 Hook,以保证函数尽可能纯粹的基础上,有效解决了上述几个之前组件开发的痛点。
这篇文章中以 useState 的数据存储和 useEffect 的副作用管理为例子展开。
由于函数组件有着纯函数的特点,本身不负责数据存储和副作用处理。因此我们首先要解决的问题就是数据的存储和副作用管理。
useState
在 JavaScript 中,解决数据存储主要有以下几个方案。
class 成员变量
全局状态
Dom
localStorage 等本地存储方案
闭包
其中,类的成员变量是 class 采用的数据存储方案;
考虑到尽可能规避副作用的影响,我们排除全局状态、本地存储和 DOM 的方案;相对而言,闭包可以满足我们数据存储和可靠性的要求。
DEMO 演化
参考 React.useState 的使用方案,应该返回一个 state 数据字段和一个更新 state 的 dispatch。
function Demo () {
const [count, setCount] = useState(0)
return <div onClick={() => { setCount(count++); }}>{count}<div>
}
根据闭包的定义和使用的返回值,我们可以很轻易的定义出以下方法:
var useState = (initState) => {
let data = initState;
const dispatch = (newData) => {
data = newData;
}
return [data, dispatch];
}
在初始化阶段,我们可以验证上面的基础 useState 可以运行。然而在每次渲染的过程中,函数都会被重新调用而重新初始化,这并不是我们期望的。因此我们需要一个数据结构对每次执行的 state 进行存储,同时还需要区分初始化和更新状态的不同执行方式。
type Hook {
memorizedState: any;
}
var useState = (initState) => {
// 根据不同生命周期判断
if (mounted) {
mountedState(initState);
}
if (updated) {
updatedState(initState);
}
}
var mountedState = (initState) => {
const hook = createNewHook();
// 初始化渲染
hook.memoizedState = initalState;
return [hook.memorizedState, dispatchAction]
}
var createNewHook = () => {
return {
memorizedState: null
}
}
function dispatchAction(action){
// 使用数据结构存储所有的更新行为,以便在 rerender 流程中计算最新的状态值
storeUpdateActions(action);
// 执行 fiber 的渲染
scheduleWork();
}
// 第一次之后每一次执行 useState 时实际调用的方法
function updateState(initialState){
// 获取当前正在工作中的 hook
const hook = updateWorkInProgressHook();
// 根据 dispatchAction 中存储的更新行为计算出新的状态值,并返回给组件
updateMemorizedState();
return [hook.memoizedState, dispatchAction];
}
到这里我们有两个问题
对于同一个 state,在 mounted 和 updated 的不同状态下,hook 是如何共享的
dispatchAction 中的 storeUpdateActions 和 updateState 中的 updateMemorizedState 是如何运作的
针对第一个问题,对于一个组件而言,Hook 是相对于组件存在的。因此,React 组件存储的 ReactNode 十分适合该场景,在当前版本下,我们将其挂载于 FiberNode 节点下。
type FiberNode {
memorizedState: any;
}
而针对第二个问题, 需要我们考虑一些复杂场景问题。
在我们实际场景中,普遍存在着一个更新周期中多次调用的 re-render 行为
以一个例子描述:
function Demo () {
const [count, setCount] = useState(0);
return <div onClick={() => {
setCount(count++);
setCount(count++)
setCount(count++)
}}>{count}<div>
}
实际上组件不会渲染3次,而是根据最后的状态渲染。这意味着在调用 dispatch 更新的时候,我们并不是直接进行更新逻辑,而是将其存储进行update时统一的调度更新,根据执行的有序性,我们采用队列存储一个 hook 的多次调用。
type Queue {
last: Update,
dispatch: any,
lastRenderedState: any
}
type Update {
action: any,
next: Update
}
type Hook {
memorizedState: any,
queue: Queue;
}
function mountState(initState) {
const hook = mountWorkInProgressHook();
hook.memorizedState = initState;
const queue = (hook.queue = {
last: null,
dispatch: null,
lastRenderedState: null
});
// 闭包绑定 queue,实现共享
const dispatch = dispatchAction.bind(null, queue);
queue.dispatch = dispatch;
return [hook.memorizedState, dispatch]
}
function dispatchAction(queue, action) {
const update = {
action,
next: null,
};
// 处理队列更新
let last = queue.last;
if (last === null) {
update.next = update;
} else {
// ... 更新循环链表
}
// 执行 fiber 的渲染
scheduleWork();
}
function updateState(initialState){
// 获取当前正在工作中的 hook
const hook = updateWorkInProgressHook();
// 根据 dispatchAction 中存储的更新行为计算出新的状态值,并返回给组件
(function doReducerWork(){
let newState = null;
do{
// 循环链表,执行每一次更新
}while(...)
hook.memoizedState = newState;
})();
return [hook.memoizedState, hook.queue.dispatch];
}
此外,在真实的应用场景中,我们会根据逻辑进行状态分割。需要在一个组件内多次使用一个 Hook,因此需要记录所有使用的 Hook 信息。这方面,与之前存储同一组更新相同的 Hook 多次调用相同,可采用链表形式进行存储。
type Hook = {
memoizedState: any, // 上一次完整更新之后的最终状态值
queue: UpdateQueue<any, any> | null, // 更新队列
next: any // 下一个 hook
}
这里我们可以看一个例子:
const Demo = () => {
const [count, setCount] = useState(0);
const [time, setTime] = useState(Date.now());
return <div onClick={() => {
setCount(count++);
setTime(Date.now());
}}>{count}-{time}</div>
}
在 ReactNode 中存储的节点形式:
const fiber = {
//...
memoizedState: {
memoizedState: 0,
queue: {
last: {
action: 1
},
dispatch: dispatch,
lastRenderedState: 0
},
next: {
memoizedState: 1603594106044,
queue: {
// ...
},
next: null
}
},
//...
}
整个链表在 mounted 的时候构建,在 update 时按照顺序执行。因此不能在条件循环等场景下使用。
useEffect
有了 useState 设计经验,useEffect 可以同比借鉴。在mount时创建一个 hook 对象,新建一个 effectQueue,以单向链表的方式存储每一个 effect,将 effectQueue 绑定在 fiberNode 上,并在完成渲染之后依次执行该队列中存储的 effect 函数。
type EffectQueue{
lastEffect: Effect
}
type FiberNode{
memoizedState: any, // 用来存放某个组件内所有的 Hook 状态
updateQueue: EffectQueue
}
type Effect {
create: any;
destory: any;
deps: Array;
next: any;
}
与 useState 不同的一点是,useEffect 拥有一个 deps 依赖数组。当依赖数组变更的时候,一个新的副作用函数会被追加至链尾。
function useEffect(fn, dependencies) {
if (mounted) {
mounteEffect(fn, dependencies)
}
if (updated) {
updateEffect(fn, dependencies)
}
}
function mountEffect(fn, deps) {
const hook = mountWorkInProgressHook();
hook.memorizedState = pushEffect(xxxTag, fn, deps)
}
function updateEffect(fn, deps) {
const hook = updateWorkInProgressHook();
const nextDeps = deps === undefined ? null : deps;
// 依赖改变则触发销毁重置
if(currentHook!==null){
const prevEffect = currentHook.memoizedState;
const destroy = prevEffect.destroy;
if (nextDeps!== null){
if(areHookInputsEqual(deps, prevEffect.deps)){
pushEffect(xxxTag, create, destroy, deps);
return;
}
}
}
hook.memoizedState = pushEffect(xxxTag, create, deps);
}
function pushEffect(tag, create, destroy, deps) {
const effect = {
create,
destory,
deps,
next: null
};
// 构建 effect 队列
const updateQueue = fiberNode.updateQueue = fiberNode.updateQueue || newUpdateQueue();
if (updateQueue.lastEffect) {
const firstEffect = lastEffect.next;
lastEffect.next = effect;
effect.next = firstEffect;
updateQueue.lastEffect = effect;
} else {
updateQueue.lastEffect = effect.next = effect;
}
return effect;
}
我们可以看到,在 useEffect 阶段,实际并没有对 effect 进行执行,仅仅是构建一条 effect 执行存储链表,而真正 create 和 destroy 的执行,在于 commit 阶段,该部分内容不在本次分享范围,感兴趣的小伙伴可以自行了解
相关链接:ReactFiberCommitWork[1]
总结
通过查找定位问题 -> 得出需求 -> 实现设计 -> 设计演进的步骤,我们一步步了解了 Hook 设计的初衷和设计的一步步完善,在日常工作中,我们也应该借鉴这种思维模式,完善自身对于业务痛点的认识以真正采取相应的解决措施
参考资料
ReactFiberCommitWork: https://github.com/facebook/react/blob/master/packages/react-reconciler/src/ReactFiberCommitWork.new.js#L375
最后
如果你觉得这篇内容对你挺有启发,我想邀请你帮我三个小忙:
点个「在看」,让更多的人也能看到这篇内容(喜欢不点在看,都是耍流氓 -_-)
欢迎加我微信「 sherlocked_93 」拉你进技术群,长期交流学习...
关注公众号「前端下午茶」,持续为你推送精选好文,也可以加我为好友,随时聊骚。