
线程池如何监控,才能帮助开发者快速定位线上错误?
大部分情况下,线程池的运行情况对于使用者来说是个黑盒
运行情况不可知,会导致 生产出现事故问题排查困难,以及线程池参数难以定义
文章围绕线程池监控展开,讨论 线程池如何监控、监控的指标以及监控数据的存储展示
01
如何监控运行数据
设想一下,如果想监控线程池的运行数据,你会怎么操作?这里提供两种常规思路
线程池运行时埋点,每一次运行任务都进行统计 定时获取线程池的运行数据
这里我推荐第二种,因为线程池的监控 API 会通过 获取主锁来控制结果的相对准确性,性能相对较差,后面会详细说明
为什么叫相对准确?因为任务和线程的状态在计算过程中可能会动态变化,只能给到一个近似值,保证不了绝对准确
模拟下定时采集线程池运行时数据的代码
private ScheduledThreadPoolExecutor collectVesselExecutor;
String collectVesselTaskName = "client.scheduled.collect.data";
collectVesselExecutor = new ScheduledThreadPoolExecutor(
new Integer(1),
ThreadFactoryBuilder.builder().daemon(true).prefix(collectVesselTaskName).build()
);
// 延迟 initialDelay 后循环调用. scheduleWithFixedDelay 每次执行时间为上一次任务结束时, 向后推一个时间间隔
collectVesselExecutor.scheduleWithFixedDelay(
() -> runTimeGatherTask(),
properties.getInitialDelay(),
properties.getCollectInterval(),
TimeUnit.MILLISECONDS
);
一般线程池分为两种方式创建,Spring Bean 和非 Spring Bean,假设创建的线程池是 Spring 管理的
我们只需要在 Spring 容器启动成功后,延迟一段时间后开始采集运行数据就 OK 了
不论线程池是否由 Spring 管理,采集的方式大致相同。一种从 Spring 容器取,一种是创建好线程池后放到一个自定义容器
02
监控的指标有哪些?
说一下目前 Hippo4J 定义的线程池监控指标,包括不限于。大家有业务中使用到的监控指标都可以讨论下
线程池当前负载:当前线程数 / 最大线程数线程池峰值负载:当前线程数 / 最大线程数,线程池运行期间最大的负载核心线程数:线程池的核心线程数最大线程数:线程池限制同时存在的线程数当前线程数:当前线程池的线程数活跃线程数:执行任务的线程的大致数目最大出现线程数:线程池中运行以来同时存在的最大线程数阻塞队列:线程池暂存任务的容器队列容量:队列中允许元素的最大数量队列元素:队列中已存放的元素数量队列剩余容量:队列中还可以存放的元素数量线程池任务完成总量:已完成执行的任务的大致总数拒绝策略执行次数:运行时抛出的拒绝次数总数
这些指标可以帮助我们解决大多数因为线程池而导致的问题排查。但是,事情往往不能尽善尽美
当前线程数、活跃线程数、最大出现线程数、线程池任务完成总量 的线程池 API 会先获取到 mainLock,然后才开始计算
mainLock 是线程池的主锁,线程执行、线程销毁和线程池停止等都会使用到这把锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
xxxxx
} finally {
mainLock.unlock();
}
如果频繁获取这把锁,会导致原有线程池任务执行性能受到影响
所以,我们应该避免频繁获取这几项参数,这也是不使用线程池任务执行埋点最重要的原因
03
监控数据存储
上面的线程池监控指标如果只能支持实时查看,并不能帮忙开发日常排查错误
大部分场景下,生产上的问题发现会有延迟。比如 12:30 出现的问题,业务13:00 进行的反馈
为了更好帮助开发排错,我们需要将线程池的历史运行数据进行存储
说到线程池历史运行数据的存储,使用 时序数据库(TSDB) 是最合适的
但大部分情况下,公司不会为了这一个需求搭建或者采购时序数据库,那就可以使用折中方案,比如说 MySQL、ES 等
我们以 MySQL 为例,his_run_data 历史运行数据表,建表语句如下:
CREATE TABLE `his_run_data` (
`thread_pool_id` varchar(56) DEFAULT NULL COMMENT '线程池ID',
`instance_id` varchar(256) DEFAULT NULL COMMENT '实例ID',
`current_load` bigint(20) DEFAULT NULL COMMENT '当前负载',
`peak_load` bigint(20) DEFAULT NULL COMMENT '峰值负载',
`pool_size` bigint(20) DEFAULT NULL COMMENT '线程数',
`active_size` bigint(20) DEFAULT NULL COMMENT '活跃线程数',
`queue_capacity` bigint(20) DEFAULT NULL COMMENT '队列容量',
`queue_size` bigint(20) DEFAULT NULL COMMENT '队列元素',
`queue_remaining_capacity` bigint(20) DEFAULT NULL COMMENT '队列剩余容量',
`completed_task_count` bigint(20) DEFAULT NULL COMMENT '已完成任务计数',
`reject_count` bigint(20) DEFAULT NULL COMMENT '拒绝次数',
`timestamp` bigint(20) DEFAULT NULL COMMENT '时间戳',
`gmt_create` datetime DEFAULT NULL COMMENT '创建时间',
`gmt_modified` datetime DEFAULT NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
KEY `idx_group_key` (`tp_id`,`instance_id`) USING BTREE,
KEY `idx_timestamp` (`timestamp`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='历史运行数据表';
可以看到,建表语句中有三个关键字段:
thread_pool_id:表示当前数据的线程池标识
instance_id:应用可能集群部署,标识集群下唯一的线程池
timestamp:记录线程池运行数据产生时的时间戳
有一个问题,线上的线程池是源源不断产生运行数据的,迟早不得把表的数据量推到上亿?
因为数据是有时效性的,过了一定时间之后,就没有必要再占用实时的资源
针对上述问题提供两种解决方案:
假设数据存储 1 天,如果超出这个时间,直接删除即可 同上所述,过期数据可以保留到备份表中,并删除 his_run_data数据
可能有的小伙伴还会担心,数据量太大会不会导致查询时过慢?
我们可以算一下,假设有 100 个应用,每个应用部署 10 个节点
假设数据有效期为 1 小时,那么可以产出的数据是 72 万,一天也就是 1728 万
对于 MySQL 而言,几千万数据量以下针对索引的查询,都不会产生性能瓶颈
04
如何定义公共监控?
抽象线程池存储
上面说到,线程池的采集历史运行数据在各个应用系统中,数据的存储、定期删除是否可以抽象出来,避免重复的工作
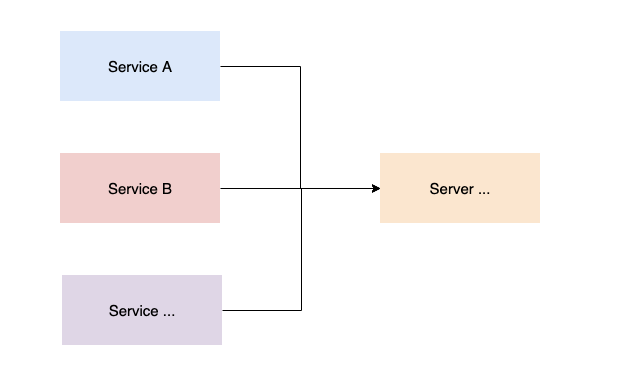
如果选择抽象数据存储,客户端节点与服务端之间的交互如下:
客户端定时采集线程池历史运行数据,将数据打包好发送服务端 服务端接收客户端上报的数据,进行数据入库持久化存储 服务端定期删除或存档客户端线程池历史运行数据 由服务端统一对外提供线程池运行图表的数据展示
这里有个小问题,客户端如何打包发送给服务端?定时采集数据后直接上报是不是可行呢
不推荐采集、上报两种行为放到一个流程中,好的设计应该是要 分离开职责;而且,如果在上报过程中网络出现阻塞等等问题,会耽误采集线程的下一次采集结果
我们可以使用多线程生产、消费模型来做,相信大家初学多线程一定都学过这个设计
// 缓冲队列
private BlockingQueue messageCollectVessel = new ArrayBlockingQueue(bufferSize);
// 生产者
Message message = collector.collectMessage();
boolean offer = messageCollectVessel.offer(message);
if (!offer) {
log.warn("Buffer data starts stacking data...");
}
// 消费者
while (true) {
try {
Message message = messageCollectVessel.take();
messageSender.send(message);
} catch (Throwable ex) {
log.error("Consumption buffer container task failed. Number of buffer container tasks :: {}", messageCollectVessel.size(), ex);
}
}
创建阻塞缓冲队列,由定时线程池采集历史运行数据,并放到缓冲队列中;然后起一个线程,循环消费即可
极端情况下缓冲队列元素会出现堆积,最新采集的线程池数据也就无法插入成功,为了不影响客户端的运行,仅做异常警告处理
使用最新抽象出来的客户端、服务端交互流程,有以下几个优点
数据的存储和查询展示由服务端提供功能,减轻客户端压力和重复工作量 历史运行数据的删除或备份操作由服务端统一执行 不同的项目不需要为线程池历史运行数据分别创建表结构存储 形成交互规范,避免业务发散单独开发,中心化的设计更利于技术的迭代和管理
监控图表展示
不同公司对于线程池的监控不尽相同,出于各种考虑,会将监控封装成最符合自己业务场景的流程
Hippo4J 从最基本的指标出发,封装出了最小代价的监控体系,并提供可视化页面的图标展示
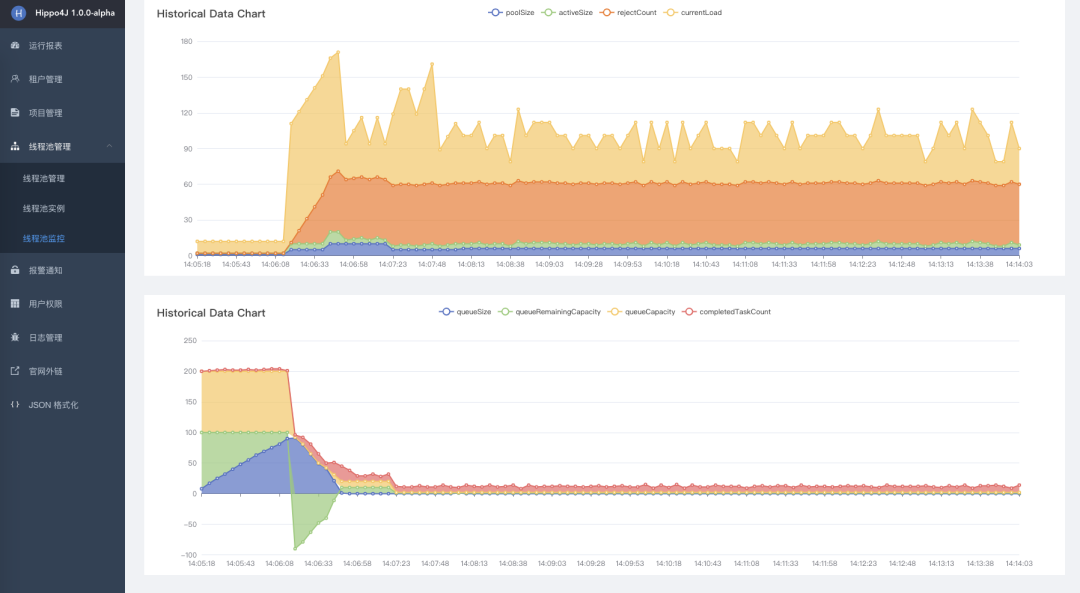
有兴趣可以查看 Hippo4J 框架官网介绍
Site:https://www.hippox.cn
还有一个功能点,考虑到很多公司搭建了一套监控体系,其中以 Prometheus + Grafana 为主
后续 Hippo4J 会接入 Prometheus,应用内部存储线程池的运行数据,适配 Prometheus 采集存储,最终展示到 Grafana
05
总结回顾
线程池作为企业级应用广泛的技术,对它的监控是不可或缺的稳定性保障之一
文章从线程池的监控出发,讲解了如何监控、监控的指标以及监控数据的存储,相信读者们也各有收获
看了上面的线程池监控内容,大家有什么想要补充的,在下方评论区留言
各位读者所在的公司又是如何对线程池监控,可以互相交流下心得
