监控系统选型,一篇全搞定!
之前,写过几篇有关线上问题排查的文章,文中附带了一些监控图,有些读者对此很感兴趣,问我监控系统选型上有没有好的建议?

目前我所经历的几家公司,监控系统都是自研的。其实业界有很多优秀的开源产品可供选择,能满足绝大部分的监控需求,如果能从中选择一款满足企业当下的诉求,显然最省时省力。
这篇文章,我将对监控体系的基础知识、原理和架构做一次系统性整理,同时还会对几款最常用的开源监控产品做下介绍,以便大家选型时参考。
内容包括如下三部分:
必知必会的监控基础知识
主流监控系统介绍
监控系统的选型建议
必知必会的监控基础知识
监控系统俗称“第三只眼”,几乎是我们每天都会打交道的系统,下面四项基础知识我认为是必须要了解的。
监控系统的 7 大作用

监控系统有如下七大作用:
实时采集监控数据:包括硬件、操作系统、中间件、应用程序等各个维度的数据。
实时反馈监控状态:通过对采集的数据进行多维度统计和可视化展示,能实时体现监控对象的状态是正常还是异常。
预知故障和告警:能够提前预知故障风险,并及时发出告警信息。
辅助定位故障:提供故障发生时的各项指标数据,辅助故障分析和定位。
辅助性能调优:为性能调优提供数据支持,比如慢 SQL,接口响应时间等。
辅助容量规划:为服务器、中间件以及应用集群的容量规划提供数据支撑。
辅助自动化运维:为自动扩容或者根据配置的 SLA 进行服务降级等智能运维提供数据支撑。
使用监控系统的正确姿势
有没有做监控?
监控是否及时?
监控信息是否有助于快速定位问题?
可见光有一套好的监控系统还不够,还必须知道如何用好它。一个成熟的研发团队通常会定一个监控规范,用来统一监控系统的使用方法。

如何使用监控系统?总结如下四个方面:
了解监控对象的工作原理:要做到对监控对象有基本的了解,清楚它的工作原理。比如想对 JVM 进行监控,你必须清楚 JVM 的堆内存结构和垃圾回收机制。
确定监控对象的指标:清楚使用哪些指标来刻画监控对象的状态?比如想对某个接口进行监控,可以采用请求量、耗时、超时量、异常量等指标来衡量。
定义合理的报警阈值和等级:达到什么阈值需要告警?对应的故障等级是多少?不需要处理的告警不是好告警,可见定义合理的阈值有多重要,否则只会降低运维效率或者让监控系统失去它的作用。
建立完善的故障处理流程:收到故障告警后,一定要有相应的处理流程和 oncall 机制,让故障及时被跟进处理。
监控的对象和指标都有哪些
这里,我对常用的监控对象以及监控指标做了分类整理,供大家参考:

②服务器基础监控
CPU:单个 CPU 以及整体的使用情况。
内存:已用内存、可用内存。
磁盘:磁盘使用率、磁盘读写的吞吐量。
网络:出口流量、入口流量、TCP 连接状态。
Nginx:活跃连接数、等待连接数、丢弃连接数、请求量、耗时、5XX 错误率。
Tomcat:最大线程数、当前线程数、请求量、耗时、错误量、堆内存使用情况、GC 次数和耗时。
缓存:成功连接数、阻塞连接数、已使用内存、内存碎片率、请求量、耗时、缓存命中率。
消息队列:连接数、队列数、生产速率、消费速率、消息堆积量。
HTTP 接口:URL 存活、请求量、耗时、异常量。
RPC 接口:请求量、耗时、超时量、拒绝量。
JVM:GC 次数、GC 耗时、各个内存区域的大小、当前线程数、死锁线程数。
线程池:活跃线程数、任务队列大小、任务执行耗时、拒绝任务数。
连接池:总连接数、活跃连接数。
日志监控:访问日志、错误日志。
业务指标:视业务来定,比如 PV、订单量等。
监控系统的基本流程
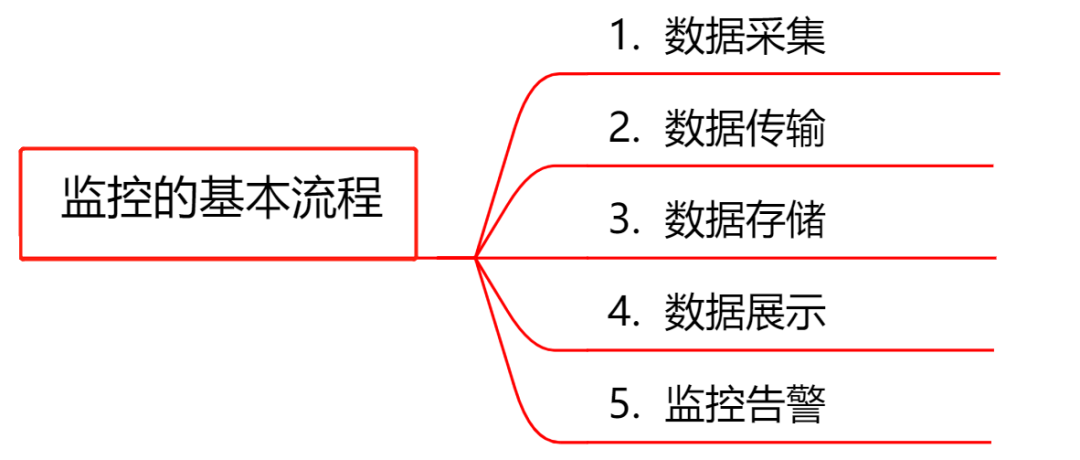
数据采集:采集的方式有很多种,包括日志埋点进行采集(通过 Logstash、Filebeat 等进行上报和解析),JMX 标准接口输出监控指标,被监控对象提供 REST API 进行数据采集(如 Hadoop、ES),系统命令行,统一的 SDK 进行侵入式的埋点和上报等。
数据传输:将采集的数据以 TCP、UDP 或者 HTTP 协议的形式上报给监控系统,有主动 Push 模式,也有被动 Pull 模式。
数据存储:有使用 MySQL、Oracle 等 RDBMS 存储的,也有使用时序数据库 RRDTool、OpentTSDB、InfluxDB 存储的,还有使用 HBase 存储的。
数据展示:数据指标的图形化展示。
监控告警:灵活的告警设置,以及支持邮件、短信、IM 等多种通知通道。
主流监控系统介绍

Zabbix(老牌监控的优秀代表)
先来了解下 Zabbix 的架构设计:
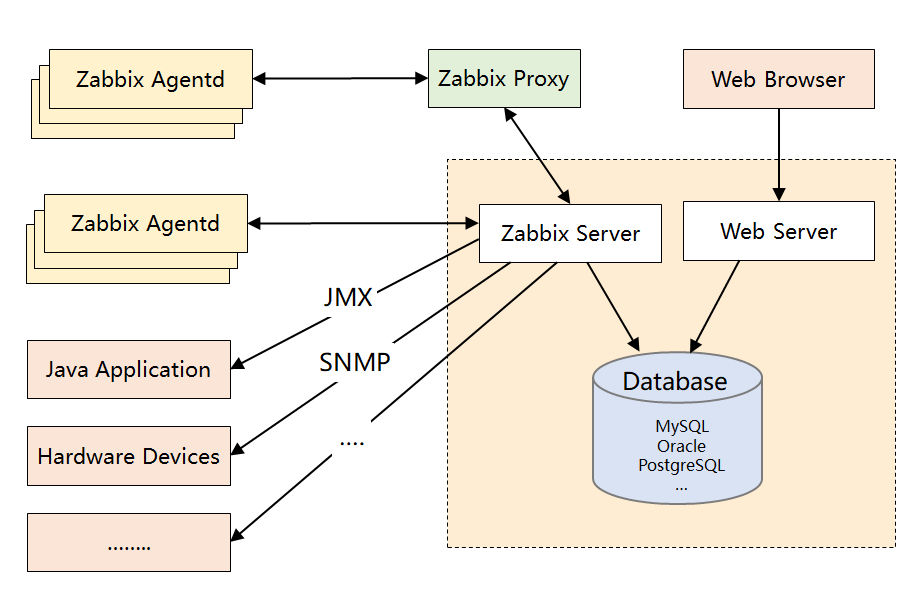
Zabbix Server:核心组件,C 语言编写,负责接收 Agent、Proxy 发送的监控数据,也支持 JMX、SNMP 等多种协议直接采集数据。同时,它还负责数据的汇总存储以及告警触发等。
Zabbix Proxy:可选组件,对于被监控机器较多的情况下,可使用 Proxy 进行分布式监控,它能代理 Server 收集部分监控数据,以减轻 Server 的压力。
Zabbix Agentd:部署在被监控主机上,用于采集本机的数据并发送给 Proxy 或者 Server,它的插件机制支持用户自定义数据采集脚本。
Agent 可在 Server 端手动配置,也可以通过自动发现机制被识别。数据收集方式同时支持主动 Push 和被动 Pull 两种模式。
Database:用于存储配置信息以及采集到的数据,支持 MySQL、Oracle 等关系型数据库。同时,最新版本的 Zabbix 已经开始支持时序数据库,不过成熟度还不高。
Web Server:Zabbix 的 GUI 组件,PHP 编写,提供监控数据的展现和告警配置。
产品成熟:由于诞生时间长且使用广泛,拥有丰富的文档资料以及各种开源的数据采集插件,能覆盖绝大部分监控场景。
采集方式丰富:支持 Agent、SNMP、JMX、SSH 等多种采集方式,以及主动和被动的数据传输方式。
较强的扩展性:支持 Proxy 分布式监控,有 Agent 自动发现功能,插件式架构支持用户自定义数据采集脚本。
配置管理方便:能通过 Web 界面进行监控和告警配置,操作方便,上手简单。
性能瓶颈:机器量或者业务量大了后,关系型数据库的写入一定是瓶颈,官方给出的单机上限是 5000 台,个人感觉达不到,尤其现在应用层的指标越来越多。虽然最新版已经开始支持时序数据库,不过成熟度还不高。
应用层监控支持有限:如果想对应用程序做侵入式的埋点和采集(比如监控线程池或者接口性能),Zabbix 没有提供对应的 SDK,通过插件式的脚本也能曲线实现此功能,个人感觉 Zabbix 就不是做这个事的。
数据模型不强大:不支持 Tag,因此没法按多维度进行聚合统计和告警配置,使用起来不灵活。
方便二次开发难度大:Zabbix 采用的是 C 语言,二次开发往往需要熟悉它的数据表结构,基于它提供的 API 更多只能做展示层的定制。
Open-Falcon(小米出品,国内流行)

先来了解下 Open-Falcon 的架构设计:
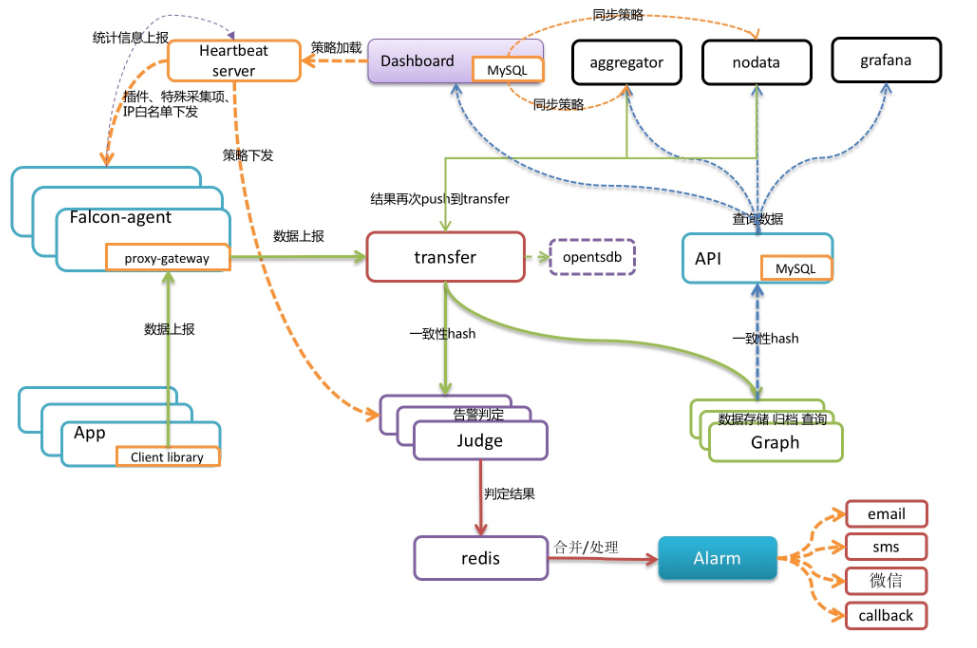
Falcon-agent:数据采集器和收集器,Go 开发,部署在被监控的机器上,支持3种数据采集方式。
首先它能自动采集单机 200 多个基础监控指标,无需做任何配置;同时支持用户自定义的 Plugin 获取监控数据;此外,用户可通过 HTTP 接口,自主 Push 数据到本机的 proxy-gateway,由 Gateway 转发到 Server。
Transfer:数据分发组件,接收客户端发送的数据,分别发送给数据存储组件 Graph 和告警判定组件 Judge,Graph 和 Judge 均采用一致性 Hash 做数据分片,以提高横向扩展能力。同时 Transfer 还支持将数据分发到 OpenTSDB,用于历史归档。
Graph:数据存储组件,底层使用 RRDTool(时序数据库)做单个指标的存储,并通过缓存、分批写入磁盘等方式进行了优化。据说一个 Graph 实例能够处理 8W+ 每秒的写入速率。
Judge 和 Alarm:告警组件,Judge 对 Transfer 组件上报的数据进行实时计算,判断是否要产生告警事件,Alarm 组件对告警事件进行收敛处理后,将告警消息推送给各个消息通道。
API:面向终端用户,收到查询请求后会去 Graph 中查询指标数据,汇总结果后统一返回给用户,屏蔽了存储集群的分片细节。
自动采集能力:Falcon-agent 能自动采集服务器的 200 多个基础指标(比如 CPU、内存等),无需在 Server 上做任何配置,这一点可以秒杀 Zabbix。
强大的存储能力:底层采用 RRDTool,并且通过一致性 Hash 进行数据分片,构建了一个分布式的时序数据存储系统,可扩展性强。
灵活的数据模型:借鉴 OpenTSDB,数据模型中引入了 Tag,这样能支持多维度的聚合统计以及告警规则设置,大大提高了使用效率。
插件统一管理:Open-Falcon 的插件机制实现了对用户自定义脚本的统一化管理,可通过 HeartBeat Server 分发给 Agent,减轻了使用者自主维护脚本的成本。
个性化监控支持:基于 Proxy-gateway,很容易通过自主埋点实现应用层的监控(比如监控接口的访问量和耗时)和其他个性化监控需求,集成方便。
整体发展一般:社区活跃度不算高,同时版本更新慢,有些大厂是基于它的稳定版本直接做二次开发的,关于以后的前景其实有点担忧。
UI 不够友好:对于业务线的研发来说,可能只想便捷地完成告警配置和业务监控,但是它把机器分组、策略模板、模板继承等概念全部暴露在 UI 上,感觉在围绕这几个概念设计 UI,理解有点费劲。
安装比较复杂:个人的亲身感受,由于它是从小米内部衍生出来的,虽然去掉了对小米内部系统的依赖,但是组件还是比较多,如果对整个架构不熟悉,安装很难一蹴而就。
Prometheus(号称下一代监控系统)

先来了解下 Prometheus 的架构设计:
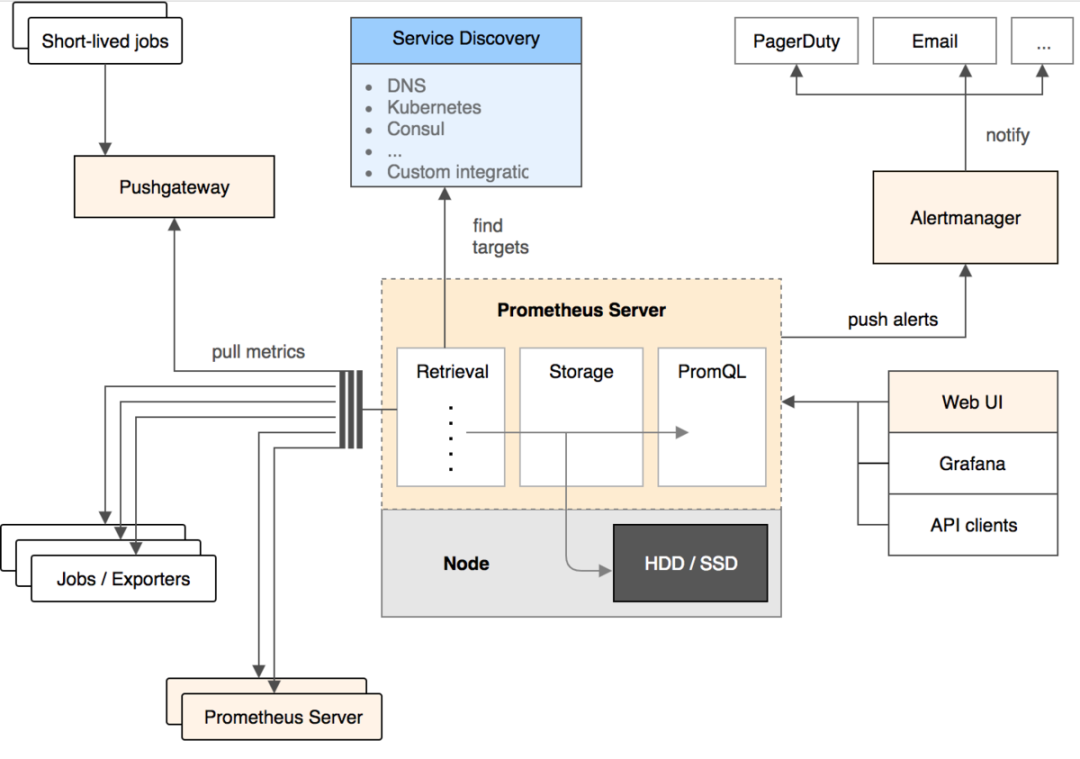
Prometheus Server:核心组件,用于收集、存储监控数据。它同时支持静态配置和通过 Service Discovery 动态发现来管理监控目标,并从监控目标中获取数据。
此外,Prometheus Server 也是一个时序数据库,它将监控数据保存在本地磁盘中,并对外提供自定义的 PromQL 语言实现对数据的查询和分析。
Exporter:用来采集数据,作用类似于 Agent,区别在于 Prometheus 是基于 Pull 方式拉取采集数据的。
因此,Exporter 通过 HTTP 服务的形式将监控数据按照标准格式暴露给 Prometheus Server,社区中已经有大量现成的 Exporter 可以直接使用,用户也可以使用各种语言的 client library 自定义实现。
Push gateway:主要用于瞬时任务的场景,防止 Prometheus Server 来 Pull 数据之前此类 Short-lived jobs 就已经执行完毕了,因此 Job 可以采用 Push 的方式将监控数据主动汇报给 Push gateway 缓存起来进行中转。
Alert Manager:当告警产生时,Prometheus Server 将告警信息推送给 Alert Manager,由它发送告警信息给接收方。
Web UI:Prometheus 内置了一个简单的 Web 控制台,可以查询配置信息和指标等,而实际应用中我们通常会将 Prometheus 作为 Grafana 的数据源,创建仪表盘以及查看指标。
轻量管理:架构简单,不依赖外部存储,单个服务器节点可直接工作,二进制文件启动即可,属于轻量级的 Server,便于迁移和维护。
较强的处理能力:监控数据直接存储在 Prometheus Server 本地的时序数据库中,单个实例可以处理数百万的 Metrics。
灵活的数据模型:同 Open-Falcon,引入了 Tag,属于多维数据模型,聚合统计更方便。
强大的查询语句:PromQL 允许在同一个查询语句中,对多个 Metrics 进行加法、连接和取分位值等操作。
很好地支持云环境:能自动发现容器,同时 K8s 和 Etcd 等项目都提供了对 Prometheus 的原生支持,是目前容器监控最流行的方案。
功能不够完善:Prometheus 从一开始的架构设计就是要做到简单,不提供集群化方案,长期的持久化存储和用户管理,而这些是企业变大后所必须的特性,目前要做到这些只能在 Prometheus 之上进行扩展。
网络规划变复杂:由于 Prometheus 采用的是 Pull 模型拉取数据,意味着所有被监控的 Endpoint 必须是可达的,需要合理规划网络的安全配置。
监控系统的选型建议
先明确清楚你的监控需求:要监控的对象有哪些?机器数量和监控指标有多少?需要具备什么样的告警功能?
监控是一项长期建设的事情,一开始就想做一个 All In One 的监控解决方案,我觉得没有必要。从成本角度考虑,在初期直接使用开源的监控方案即可,先解决有无问题。
从系统成熟度上看,Zabbix 属于老牌的监控系统,资料多,功能全面且稳定,如果机器数量在几百台以内,不用太担心性能问题,另外,采用数据库分区、SSD 硬盘、Proxy 架构、Push 采集模式都可以提高监控性能。
Zabbix 在服务器监控方面占绝对优势,可以满足 90% 以上的监控场景,但是应用层的监控似乎并不擅长,比如要监控线程池的状态、某个内部接口的执行时间等,这种通常都要做侵入式埋点。相反,新一代的监控系统 Open-Falcon 和 Prometheus 在这一点做得很好。
从整体表现上来看,新一代监控系统也有明显的优势,比如:灵活的数据模型、更成熟的时序数据库、强大的告警功能,如果之前对 Zabbix 这种传统监控没有技术积累,建议使用 Open-Falcon 或者 Prometheus。
Open-Falcon 的核心优势在于数据分片功能,能支撑更多的机器和监控项;Prometheus 则是容器监控方面的标配,有 Google 和 K8s 加持。
Zabbix、Open-Falcon 和 Prometheus 都支持和 Grafana 做快速集成,想要美观且强大的可视化体验,可以和 Grafana 进行组合。
用合适的监控系统解决相应的问题即可,可以多套监控同时使用,这种在企业初期很常见。
到中后期,随着机器数据增加和个性化需求增多(比如希望统一监控平台、打通公司的 CMDB 和组织架构关系),往往需要二次开发或者通过监控系统提供的 API 做集成,从这点来看,Open-Falcon 或者 Prometheus 更合适。
如果非要自研,可以多研究下主流监控系统的架构方案,借鉴它们的优势。
最后的话
本文对监控体系的基础知识、原理和主流架构做了详细梳理,希望有助于大家对监控系统的认识,以及在技术选型时做出更合适的选择。

推荐阅读:
 喜欢我可以给我设为星标哦
喜欢我可以给我设为星标哦