
Elasticsearch Nested 选型,先看这一篇!
1、关于Nested 问题
上次讲解了Elasticsearch 数据建模之后,很多同学反馈问题:
Q1:用nested做嵌套文档,对嵌套文档的字段做查询,只要主文档下一个嵌套文档符合要求,就会把主文档以及下面的所有的嵌套文档都查出来,实际我只需要符合要求的嵌套文档。这个用nested可以做吗?
Q2:请教个问题 这个nested 是只要用这个字段类型就影响性能还是说当只有用这个字段类型去筛选才影响性能?
Q3:Elasticsearch Nested 取一条数据 怎么搞?
Q4:nested聚合查询等,导致jvm内存剧增,出现长时间的full GC,如何破?
介于此,非常有必要将 Nested 类型再梳理一遍。
2、Nested 产生的背景
博文“干货 | Elasticsearch Nested类型深入详解”有讲过,这里再强调一遍。
Object 对象类型对数据拉平存储,不能实现精准检索匹配,会召回不满足查询结果的数据,才导致 Nested 的出现。
举例如下:
PUT laptops-demo/_doc/1
{
"id": 1,
"name": "联想ThinkPad P1(01CD)",
"price": 29999,
"brand": "Lenovo",
"attributes": [
{
"attribute_name": "cpu",
"attribute_value": "Intel Core i9-10885H"
},
{
"attribute_name": "memory",
"attribute_value": "32GB"
},
{
"attribute_name": "storage",
"attribute_value": "2TB"
}
]
}
GET laptops-demo/_search
GET laptops-demo/_search
{
"query": {
"bool": {
"must": [
{ "match": { "attributes.attribute_name": "cpu" }},
{ "match": { "attributes.attribute_value": "32GB" }}
]
}
}
}
如上逻辑混乱的检索条件(CPU,8GB 内存混搭的条件),也能召回数据,这不是实际业务需要满足的场景。
本质原因:默认不指定 Mapping,如上的 attributes 里的键值对元素映射为:Object 类型。
而 Object 存储类似是单个文档拉平存储的,如下所示:
{
"id": 1,
"name": "联想ThinkPad P1(01CD)",
"price": 29999,
"brand": "Lenovo",
"attributes.attribute_name": ["cpu", "memory", "storage"],
"attributes.attribute_value": [“Intel Core i9-10885H”, “32GB”, “2TB”]
}
有了 Nested 类型,则可以很好的规避上述检索不精确的问题。
3、Nested 如何存储数据的?
先将一下上小节例子,用 Nested 类型实现如下:
注意:若选型 Nested,必须 Mapping 层面明确设定 Nested。
PUT laptops-demo
{
"mappings": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"price": {
"type": "long"
},
"brand": {
"type": "keyword"
},
"attributes": {
"type": "nested",
"properties": {
"attribute_name": {
"type": "keyword"
},
"attribute_value": {
"type": "keyword"
}
}
}
}
}
}
还是插入之前数据。
PUT laptops-demo/_doc/1
{
"id": 1,
"name": "联想ThinkPad P1(01CD)",
"price": 29999,
"brand": "Lenovo",
"attributes": [
{
"attribute_name": "cpu",
"attribute_value": "Intel Core i9-10885H"
},
{
"attribute_name": "memory",
"attribute_value": "32GB"
},
{
"attribute_name": "storage",
"attribute_value": "2TB"
}
]
}
这里想说明的是:对于如下的拼凑且逻辑混乱的检索条件,不再返回数据。
GET laptops-demo/_search
{
"query": {
"nested": {
"path": "attributes",
"query": {
"bool": {
"must": [
{
"match": {
"attributes.attribute_name": "cpu"
}
},
{
"match": {
"attributes.attribute_value": "8GB"
}
}
]
}
}
}
}
}
只有将上面的 “8GB” 换成与 cpu 对应的属性值:“Intel Core i9-10885H”,才会有数据召回。
这体现了 Nested 的好处,实现了对象元素的“精准打击(检索)”。
嵌套对象将数组中的每个对象作为单独的隐藏文档(hidden separate document)进行索引。
拿上面的“联想电脑”的例子,用户看到写入了一个文档(对应文档id为1,包含三组attributes属性对象数据),实际后台是:4 个 Lucene 文档。
4个 Lucene 文档组成:1个父 Lucene 文档 (或者叫做:根文档)+ 3 个 Lucene 隐藏文档(nested 对象文档)。
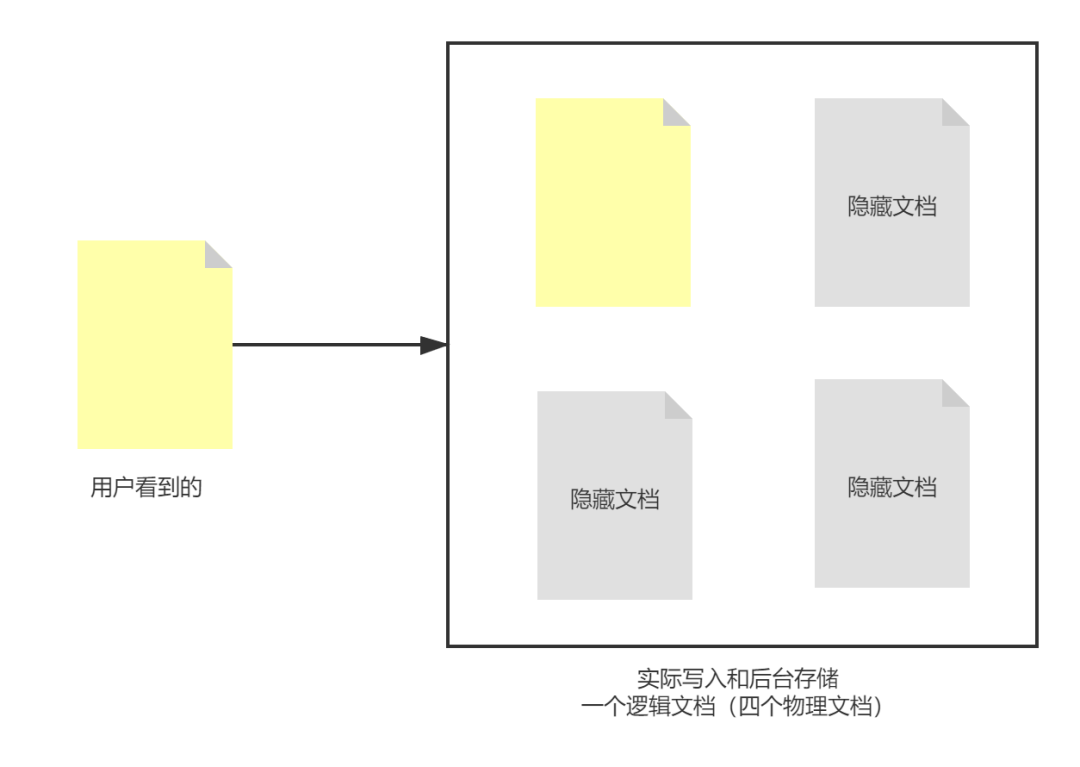
具体文档存储大致拆解如下所示:
父文档或根文档
{
"id": 1,
"name": "联想ThinkPad P1(01CD)",
"price": 29999,
"brand": "Lenovo"
}
第二个文档
{
"attributes.attribute_name": "cpu",
"attributes.attribute_value": "Intel Core i9-10885H"
}
第三个文档
{
"attributes.attribute_name": "memory",
"attributes.attribute_value": "32GB"
}
第四个文档
{
"attributes.attribute_name": "storage",
"attributes.attribute_value": "2TB"
}
这意味着:如果 attributes 键值对增多,假设上述示例中电脑的相关属性有100个,那么后台就会有:101 个文档。这看似风平浪静的存储,实际造成的风险还是很大的。
同样的一份文档写入,若包含 Nested 类型,则意味着有 N 个Nesed 子对象,就会多出 N 个 隐形文档,写入必然会有压力。
同样的,检索原来一个文档搞定,现在要在根文档及周边的 N 个隐形文档附件召回数据,势必检索性能也会受到影响。
大家似乎能隐约感觉到了:写入慢、更新慢、检索慢的问题所在了!
4、Nested 实战问题及解答
4.1 Nested 新增或更新子文档操作,为什么需要更新整个文档?
4.2 Nested 文档和父子文档(join 类型)本质区别?
4.3 为什么 Nested 写入和更新操作会很慢?
5、Nesed 选型注意事项
PUT products/_settings
{
"index.mapping.nested_fields.limit": 10,
"index.mapping.nested_objects.limit": 500
}
index.mapping.nested_fields.limit 含义:一个索引中不同的 Nested 字段类型个数。
如果超出,会报错如下:
"reason" : "Limit of nested fields [1] has been exceeded"
index.mapping.nested_objects.limit 含义:一个 Nested 字段中对象数目,多了可能导致内存泄露。
这个字段,在我验证的时候,没有达到预期,后面我再通过留言补充完善。
第七:选型 Nested 类型或者 Join 类型,就势必提前考虑性能问题,建议多做一些压力测试、性能测试。
6、小结
多表关联是很多业务场景的刚需。但,选型一定要慎重,了解一下各种多表关联类型:Nested、Join 的底层存储和逻辑,能有助于更好的选型。
Nested 本质:将 Nested 对象作为隐藏的多个子文档存储,一次更新或写入子文档操作会需要全部文档的更新操作。
上周末深圳的 meetup 提及:整合 mongoDB + ES 的解决方案(见文末社区参考链接),mongo DB 实现了多表融合,也就是大宽表一步到位,本质是:空间换时间的方案。该方案我认为脑洞非常大,如果业务层面可行,大家可以借鉴。
您使用 Nested 遇到哪些问题?欢迎留言交流。
参考
https://medium.com/codex/learn-advanced-crud-and-search-queries-for-nested-objects-in-elasticsearch-from-practical-examples-7aebc1408d6f
https://discuss.elastic.co/t/whats-nested-documents-layout-inside-the-lucene/59944
https://www.elastic.co/guide/en/elasticsearch/reference/current/nested.html
https://discuss.elastic.co/t/nested-types-are-slower/90546
https://elasticsearch.cn/slides/284
推荐
