
原地爆炸:torch.manual seed(3407) is all you need?
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
近日,有位法国的小哥研究了(https://arxiv.org/abs/2109.08203)随机种子对模型训练效果的影响,最后发现不同的随机种子选择会带来较大的差异:torch.manual seed(3407) is all you need: On the influence of
random seeds in deep learning architectures for computer
vision。
这项研究主要研究三个问题:
设置不同随机种子下,模型效果的分布是什么样的? 是否存在黑天鹅:某些随机种子产生差异特别大的效果? 在大数据集上的预训练模型会不会减少随机中子带来的差异?
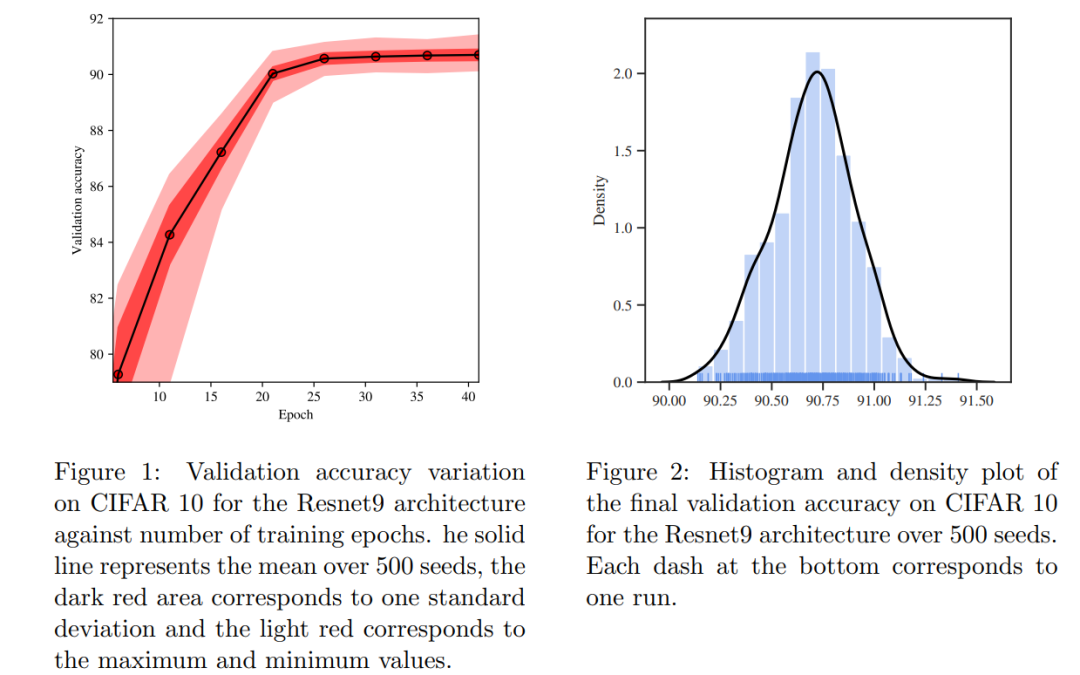
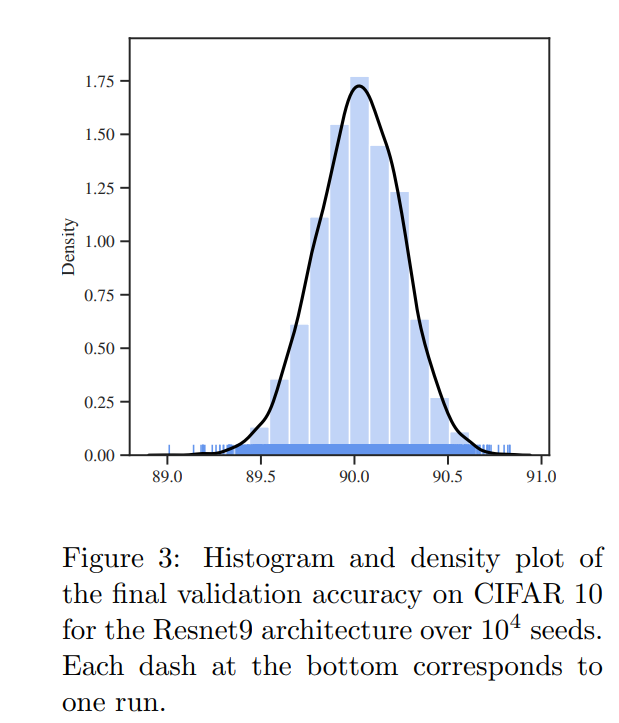
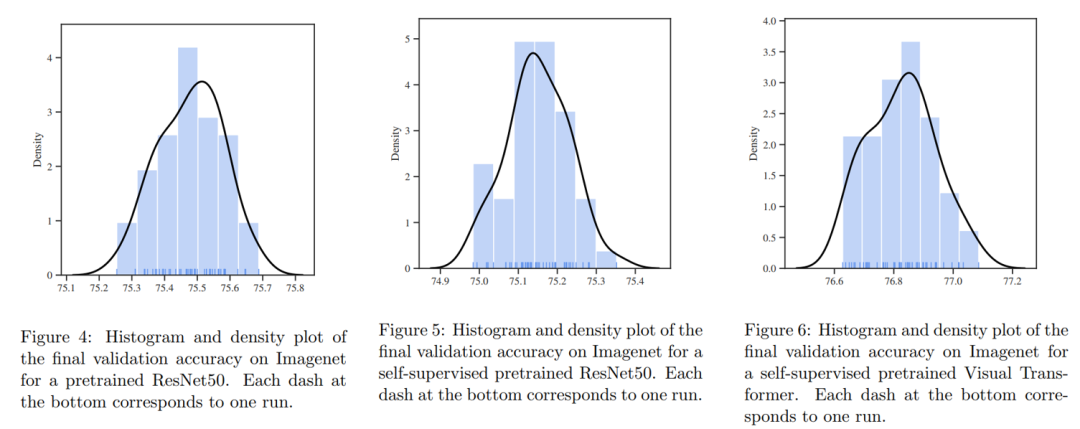

不同随机种子下模型效果分布呈现单峰分布;
存在种子黑天鹅,某些种子效果要比明显更好;
大数据集上预训练模型虽然会减少随机种子带来的差异,但是不会消除它。
这项研究带来的一个问题,既然随机种子可能带来不小的效果差异,那么一些研究论文中报告的性能提升,会不会是这种随机造成的,这恐怕很难回答?
当然,这项研究存在一些缺陷,那就是受限训练资源,只做了比较少的实验,而且也没采用SOTA模型,以及一些更好的训练策略,这些会不会足以消除这种误差,还有待验证。
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号

评论