一向低调的AWS终于在2022年发了一篇关于DynamoDB的论文——《 Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service》。(论文地址:https://www.usenix.org/system/files/atc22-elhemali.pdf)这已经距离DynamoDB发表的第一篇论文已经过去了15年。当然,业界的人都知道,15年前的那一篇《Dynamo Amazon's Highly Available Key-value Store》与现在在AWS运行的DynamoDB没有任何关系,原作者从Amazon跳槽到FaceBook,做出了Cassandra,因此它实际上是Cassandra的理论基础。所以,外界都只能通过AWS公开的文档和演讲中来对DynamoDB的架构和细节管中窥豹。从DynamoDB 2012年在AWS上线到现在已经十年了,也许这篇文章,就是DynamoDB团队为大家献出的十周年庆典回馈活动吧。DynamoDB 2022 Paper是一篇典型的Industry Paper,整篇读下来没有复杂的理论和公式,连文章最后的性能测试放上的几张图,都感觉有拼凑嫌疑……在文中大量的篇幅,都是在讲DynamoDB这十年来面对业务的需求和面对Serverless这个模式的挑战下的不断改进和经验总结。比如论文中还详细讲了DynamoDB怎么去升级和回滚,把版本bug的影响降到最低,这对于同在产业界的我们来说,这些经验和教训真的是感同身受。无独有偶,Lindorm基本上是与DynamoDB正式发布的差不多时间在阿里上线的。Lindorm在阿里的发展也十年有余了。Lindorm的发展路线基本与DynamoDB一致,先是在阿里内部支撑海量的电商业务,如淘宝订单,菜鸟物流,支付宝风控等等,到后来开始在阿里云上对外售卖,逐渐转变成一个云原生的多模数据库,以低成本,海量存储,高吞吐,高扩展性,高性能等特点支持了云上各类客户。DynamoDB2022Paper中说他在去年的Prime Day购物节中,最高QPS达到了8000万/s,而实际上在去年双十一时,阿里内部所有Lindorm集群的峰值吞吐达到了8.8亿/s。从这点上来看,Lindorm的实际规模已经远远大于DynamoDB的部署。当然,DynamoDB和Lindorm在定位上还是有一些差异的,Lindorm通常面对的都是有海量存储需求的大客户,而DynamoDB更看重全托管,开箱即用,按需付费等等。但是同样做为一个分布式的NoSQL数据库,很多设计的思考都是相通的。特别是这几年Lindorm也做了一些Serverless的尝试和热点自愈的工作,和paper中提到的还是有一些类似的。所以,我这篇文章不单单是DynamoDB论文的一篇解读文章。我觉得单纯解读太没意思了,肯定有人会把这篇论文翻译成中文。我更想在这篇论文中找出几点我特别有感触的,讲讲DynamoDB和Lindorm在对待这些问题上的思考和实现有一些什么异同。让大家不仅能去了解DynamoDB的设计,还能获得一些从未对外公开的Lindorm设计细节的干货。做为一个Serverless数据库来说,限流是一个再重要不过的能力了。因为DynamoDB就是靠计算用户的读写量去计费的。在DynamoDB中,定义读4KB的数据叫做1个RCU,写1KB的数据叫做1个WCU,然后DynamoDB按照用户购买的RCU,WCU收取计算费用和限流(Provision模式,On-Demand模式另说)。至于为什么读4KB会计算成1个RCU,而写1KB就算成一个WCU我猜测因为DynamoDB的存储实际上是B树,对于B树结构来说,写的代价要比读的代价要高。另外DynamoDB有一个硬限制每个Partiton不能超过1000个CU。这样,DynamoDB在用户购买时,就会给用户预分区。比如文中的举例,如果用户购买了3200WCU,那么在初始化表时,DynamoDB会自动分出4个Partition,每个partition限流800WCU。也就是说DynamoDB最初的限流是非常简单粗暴的,限流就是预先分给每个Partition的值,达到了就会限流。这样就会出现两个问题:1. 当单个Partition的访问量超过了800WCU,立马就会限流,而达不到用户买的3200WCU;2. 如果用户购买了6000WCU,由于DynamoDB的单Partition最多只能承载1000个WCU,DynamoDB会把用户之前的4个Partition分裂成8个,这样每个Partition的限流值反而下降为6000/8=750WCU,每个Partition的限流值下降了,如果此时用户又把6000WCU改回3200WCU,那更糟糕了,每个Partition最多只能请求3200/8=400WCU,用户提升了然后下降了provision的WCU,Partition能承载的WCU却降了一半,用户一脸懵逼。
这样的使用体验是很差的。所以DynamoDB做了两个改进。第一个改进是Burst。所谓burst,就是支持把前几秒没用完的Quota攒起来,当用户超过预设的限流值时,可以先消耗之前攒的WCU,而不会触发限流。但这个攒CU是有限的,DynamoDB支持最多攒5分钟的CU。而且,尽管DynamoDB没有在论文和任何文档中提起,我觉得攒的这个CU应该是不能超过每个Partition 1000WCU这个硬限制的。Burst解决了用户短暂的突发流量访问的问题,但是,如果用户的数据访问本身就是倾斜的(这种Case是非常常见的),burst没法解决这样的问题。
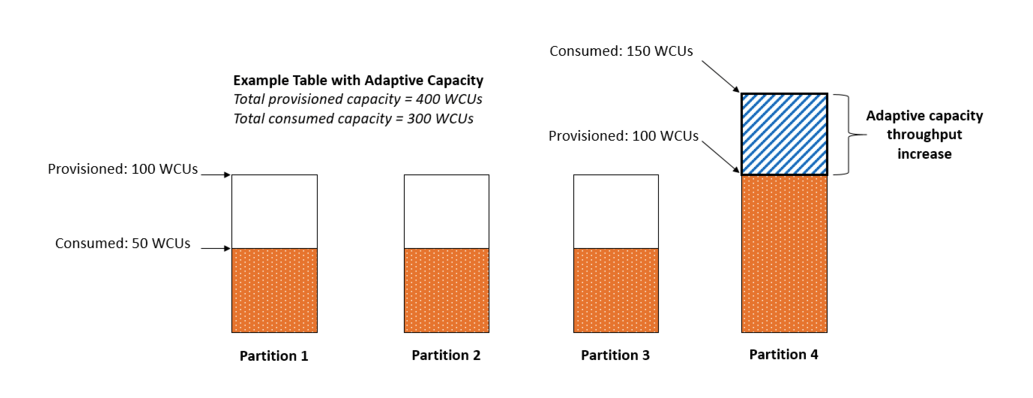
因此DynamoDB又做了一个Adaptive Capacity。简单来说,就是自动地按需调整每个partition的限流值。如上图中的例子,用户买了400WCU,表有4个Partition(除了CU限制,如果Partition大小超过10GB,DynamoDB也会分裂),每个Partition可以有100WCU,如果用户的请求在Partition4上比较多,DynamoDB会自动地把Partition4的限流设置为150,当然,表上总的CU不能超过购买的400。
在我看来,Adaptive Capacity是一个滞后的调整方案,也就是说用户可能先会遭受限流的抛错,DynamoDB识别到了这种情况,才能做自适应地调整。而且,整个DynamoDB限流是按Partition来做的初衷是想让整个架构简单,不想引入一个中心节点来做限流控制,而Adaptive Capacity功能使DynamoDB不得不引入一个Global Admission Control(GAC)角色来做整个集群的调解和控制,原本想极力避免的设计复杂性又不得已加了回来。
其实,DynamoDB的限流策略并非首次公开,Burst和Adaptive Capacity在DynamoDB的文档中已经有过详细描述。Lindorm在做限流模块时,也研究过DynamoDB的这些策略,我们觉得DynamoDB的限流策略并不是特别的好(但论文中宣称做了Burst和Adaptive Capacity后解决了99.99%的数据倾斜访问问题,只能说DynamoDB面对的客户和Lindorm差异非常大)。
所以Lindorm在设计自己的限流模块时遵循了3个原则:
1. 数据倾斜访问是常态,即使用户只访问一个Partition,也必须达到用户在表上设置的限流值;3. 限流中心不能是系统单点,即使限流中心宕机,不影响正常请求。因此,Lindorm设计了如下图的限流方案。
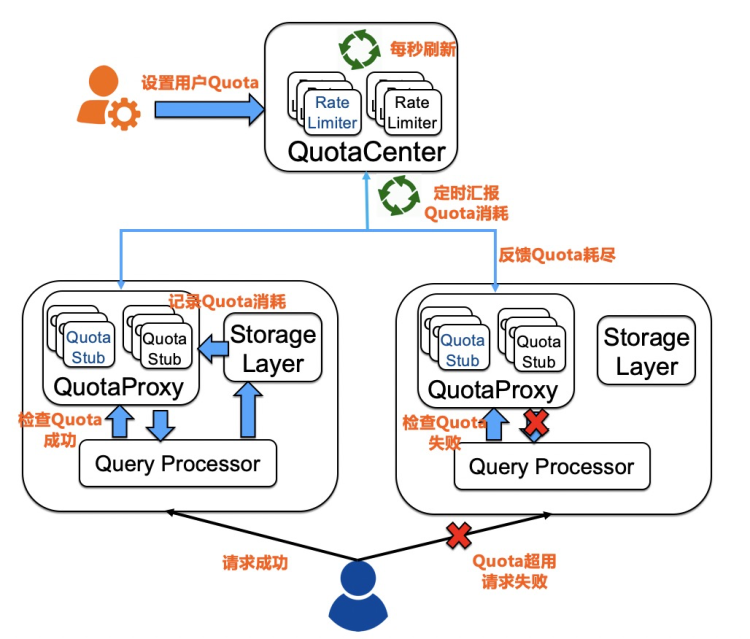
这个系统设计的核心是,用户在请求过程中不会和限流中心做交互,全程只和本地的QuotaProxy打交道(全内存操作),用户请求完成后,会告诉QuotaProxy这个请求的消耗(对,Lindorm也用了WCU和RCU的概念,本章的末尾会回来讨论Capacity Unit这个东西),QuotaProxy会定期向QuotaCenter汇报用户的消耗,这样QuotaCenter的压力也只和服务器的规模相关,与用户的请求无关。QuotaCenter接收各个服务器的汇报后,计算出这个用户这一秒还有没有Quota,如果没有了,就会反馈给QuotaProxy。这样,下次用户来请求的时候,就会在Check本地的QuotaProxy过程中收到Quota超限的错误。留给读者思考下,这样的设计是怎么满足上面的三个原则的。Lindorm也是用了WCU和RCU的定义来衡量请求的消耗。但靠计算请求的数据的大小真的能非常准确地衡量请求的资源消耗吗?答案是否定的。举一个简单的例子,select * from table where a > 1 和 select * from table where a like '%xx%'这两个请求即使扫描的数据一样,而实际上消耗的CPU完全是不一样的。所以用数据大小来衡量请求消耗只是一个极度简化的模型。所以像做的比较好的Azure Cosmos的RU(Rquest Unit)模型定义,会更加复杂,他会把请求的编译时间,CPU的消耗,数据量大小都会考虑成RU的一部分。当然,这也是一把双刃剑,本来用户去评估需要买的CU就已经比较困难了,如果像Cosmos的这种定义,恐怕没有几个业务能够准确估算自己业务的预算。
负载均衡是分布式系统一项非常重要的功能,热点的partition也是切片数据库非常常见的问题。当DynamoDB只有Provision(预留)模式时,负载均衡是非常好做的,因为每个Partition的流量上限是定死的,系统只需要平均分配这些Partition,让他们provision的总值在各个服务器上差不多即可。如果有用户改变了Provision的值,只需按照新的预留值该split的split,该重新分配的重新分配服务器,不需要太复杂的算法。但是,当DynamoDB上了On-Demand(按量付费)模式时,负载均衡会变得更加复杂。用户的每个Partition上没有固定的限流值了,用户想用多少就用多少,然后按照请求量取付费。这个模式下会对负载均衡系统提出非常大的挑战。同时,Burst和Adaptive Capacity也会带来很多流量会超限的Partition,文中称其为“noisy neighbors”。DynamoDB2022Paper中提到为了解决负责均衡的问题,他们实现了一套系统去监控每个节点的吞吐,如果出现节点负载过高或者不均衡的情况,就会自动发起一次partition的move操作。另外,当Partition的请求达到一定阈值,就会触发Partition的分裂,并且这个split point不单单是从Partition的中间,而是会分析流量,找到最佳的split point。并且,文中还特别提到,DynamoDB能够识别顺序写和单key热点,这两种热点情况,即使split也是没有效果的。论文中没有透露DynamoDB中怎么实现这个热点识别和负载均衡的细节,但是,Lindorm在处理这些问题上的思路其实和DynamoDB是差不多的,我可以给大家讲讲在Lindorm中是怎么做的。在Lindorm中,其实负载均衡的问题会更加棘手,因为在Lindorm中是不会给每个partition去设置限流的,因此不能像DynamoDB那样根据每个Partition的WCU/RCU去做负载均衡。因此,必须要找到一个准确衡量每个Partition消耗的方式,合理布局Partition到每台Server上。
Lindorm最先参考的是HBase的StochasticLoadBalancer。这个Balancer和它的名字一样,异常复杂。它会根据读请求数,写请求数,文件数,本地化率等一系列条件做为输入,通过用户配置的权重因子,计算出一个集群均衡指数,然后再根据这个指数来进行Partition的负载均衡。这个算法初衷是挺好的,把能考虑到的因素都计算在内了,但在实际的环境中,有的集群读多写少,有的集群读少写多,而且集群的情况在时刻变化。如果在Lindorm上使用这样一个Balancer,面对不同的负载,那么我们的运维将陷入无尽地调参中不能自拔……
其实,StochasticLoadBalancer是想雨露均沾,合成一个准确衡量Partition资源消耗的值。那有没有这样一种衡量手段,能够非常简单直白,而又能相对准确地衡量每个Partition的资源消耗,来做为负载均衡的依据呢?其实是有的,这个值就是CPU时间片的消耗。不论是读还是写,只要是CPU时间片消耗的多,我们就可以认为这个Partition资源消耗比较大,因为对IO的消耗,最终也会反应到CPU上。有了每个Partition的CPU时间片消耗这个一个度量衡,那我们就可以对整个集群进行一些Partition(Lindorm中叫做Region)的swap操作,以达到一个每台服务器的CPU消耗均衡状态。这就是Lindorm的CpuUsageBasedBalaner。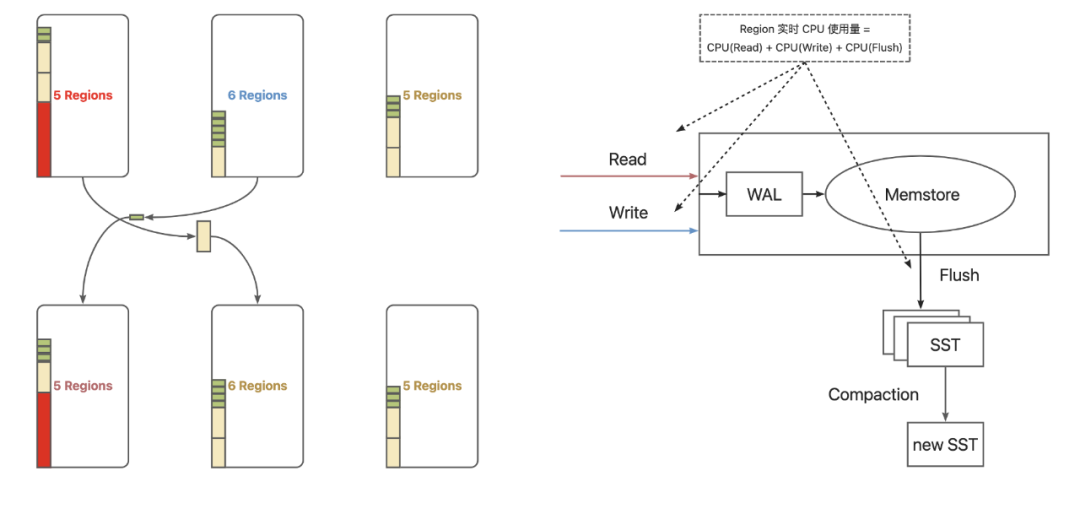
另外一个就是热点Partition的split。和DynamoDB一样,Lindorm需要识别出热点Partition的热点类型,是顺序写,单key热点还是范围热点。如果是前两者,这样的热点Partition是没法用分裂来解决的,只能隔离。如果是范围热点,则需要知道范围热点的中间点在哪里,从中间切开,而不是像HBase那样对等分。为了做到这点,Lindorm是采用了请求采样的方式去做的。
热点识别+CPUbased负载均衡+Region Normalizer+单key热点限流+异常region隔离这几个模块统一形成了Lindorm的热点自愈方案。目前这套方案基本能给Lindorm自动解决90%以上的线上热点问题。对于绝大部分分布式数据库来说,最绕不开的就是路由表了,从DynamoDB论文中的架构图可以看到,任何请求都需要去路由表上查询下真实后台服务器的地址。如果路由表的服务出现问题,那么用户的请求一定会受到影响。
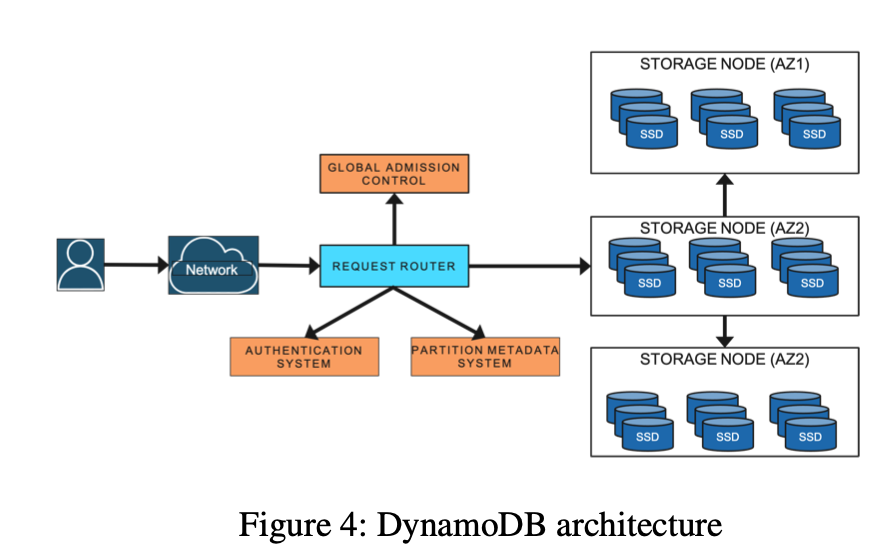
减轻路由表服务压力的通常做法是加一层缓存。但是DynamoDB认为加缓存可能遇到冷启动时会造成缓存击穿,会造成各个系统的不稳定甚至级联宕机。而且命中缓存和不命中缓存的请求RT差异巨大,不利于降低请求毛刺。因此DynamoDB现在的做法是加了一个分布式内存存储MemDS来存储路由信息,MemDS可以水平扩展能够承受整个集群的请求。用户的请求只会和MemDS交互来查询对应key的路由信息。如果发生Partition的路由变动,也会通知MemDS来做一个内存信息的更改。如果用户请求从MemDS这里得到了滞后的路由信息,则会触发MemDS去查询真正的路由表来获取对的路由。这样的话,对路由表的查询压力量级大大减少,只有在抛错的情况下,MemDS才会去查询真正的路由表。冷启动时,路由表的信息也可以由其他MemDS节点同步,不会有冷启动打爆的问题。
在写这篇文档前,我也拜读过PingCap CTO黄东旭写的这篇《Some notes on DynamoDB 2022 paper》,这里面提到DynamoDB做这个改变也可能是2015年这次重大故障(https://aws.amazon.com/cn/message/5467D2/)后的反思。简单来说,那次DynamoDB上了全局二级索引后,对路由表的请求剧增导致了路由模块的崩溃,进而导致整个服务崩溃。其实Lindorm早期在使用HBase的架构时,meta表是一个强单点,同样有这样的血泪教训。所以Lindorm在设计客户端路由时,虽然没有去设计一个分布式内存存储,但实际上做的事情,也是有异曲同工的效果。
在Lindorm的设计中,每个QueryProcesser节点中都有一个RegionLocator模块,用户的请求不会直接去请求meta表,而是由RegionLocator模块代为请求。用户请求只会和RegionLocator交互,RegionLocator里会缓存路由信息。这样无论用户的客户端有多少,请求有多少,meta表的压力只与RegionLocator的数量有关。同样在收到请求路由错误时,RegionLocator会去meta表里更新region的地址。自从Lindorm采用这套路由架构后,再也没出现过meta表打爆的情况了。
DynamoDB做为业界一款优秀的NoSQL数据库,其10年的经验能让人收获不少反思。DynamoDB的诞生,发展并没有什么惊天地泣鬼神的新功能,我从文中看到看到的,是一代代AWS工程师在面对业务挑战,面对故障后不断地对系统作出改进和修复,在业务的驱动下,一步一步地走到今天。做为数据库行业的从业人员,在阅读这篇Paper时,里面讲的痛点总是有一种让人“似曾相识”的感觉。Lindorm也走过了它的十年,Lindorm也是在海量的数据压力下,各类业务的不断呼喊以及各种故障的血泪教训中不断成长起来的。除了有些课题需要前沿的理论支持,绝大部分情况下,做数据库就是要去不断去攻克一个个的工程难题。最近,国产数据库异常火爆,在我看来,大家都是在各自的视角,各自的角度去尝试解决客户的问题,与一些老牌数据库相比,我觉得这个里面没有太多的技术壁垒,更多的是时间的积累还有弯道超车的勇气,殊途同归,大家一起共勉吧。做为国产自研数据库中不可或缺的一员,我希望不久的将来,大家也可以看到Lindorm的Paper出现在顶会上。 / End /
