用嘴做视频,这款应用太逆天

作者 | 冷思真
来源 | 爱范儿(ID:ifanr)
如需转载请联系原出处
“
硅兔君荐语
AI界的“言出法随”新进展,同声传译有了,同声制作也来了~
今年,是 AI 在图像视频制作领域进步很大的一年。
有人拿着 AI 生成的图像拿走了数字艺术大奖,战胜了一众人类艺术家;有 Tiktok 这样的应用通过文字输入生成图片,变为短视频的绿幕背景;还有新的产品可以做到文字直接生成视频,直接实现「用嘴做视频」的效果。
这次的产品来自深耕人工智能多年,前段时间才因为元宇宙被疯狂嘲讽的 Meta。

▲
Meta 元宇宙曾被疯狂嘲讽
只是这次,你不能嘲讽它了,因为它真的有了小突破。
01
文字转视频,能做成什么样
现在,你可以动嘴做视频了。
这话虽然有点夸张,但 Meta 这次推出的 Make-A-Video 恐怕真是朝着这个目标前进的。
 目前 Make-A-Video 可以做到的是:
目前 Make-A-Video 可以做到的是:
文字直接生成视频——将你的想象力变成真实的、独一无二的视频
图片直接转为视频——让单一图片或两张图片自然地动起来
视频生成延伸视频——输入一个视频创建视频变体
虽然官网还不能让你直接生成视频体验,但你可以先提交个人资料,之后 Make-A-Video 有任何动向都会先和你分享。
 目前可以看到的案例不多,官网展示的案例在细节上还有一些怪异的地方。但不管怎么说,文字可以直接变视频,本身就是一个进步了。
目前可以看到的案例不多,官网展示的案例在细节上还有一些怪异的地方。但不管怎么说,文字可以直接变视频,本身就是一个进步了。一只泰迪熊在画自画像,你可以看到小熊的手在纸面阴影部分的投影不太自然。
 机器人在时代广场跳舞。
机器人在时代广场跳舞。 猫拿着电视遥控器换台,猫咪手部爪子和人手极为相似,某些时候看还觉得有点惊悚。
猫拿着电视遥控器换台,猫咪手部爪子和人手极为相似,某些时候看还觉得有点惊悚。 还有戴着橙色针织帽的毛茸茸树懒在摆弄一台笔记本电脑,电脑屏幕的光映在它的眼睛里。
还有戴着橙色针织帽的毛茸茸树懒在摆弄一台笔记本电脑,电脑屏幕的光映在它的眼睛里。 上面这些属于超现实风格,和现实更相似的案例则更容易穿帮。
上面这些属于超现实风格,和现实更相似的案例则更容易穿帮。Make-A-Video 展示的案例如果只是专注局部表现都不错,例如艺术家在画布上画画的特写,马喝水,在珊瑚礁游泳的小鱼。


 但是稍微写实一点的年轻夫妇在大雨中行走就很怪异,上半身还好,下半身的脚忽隐忽现,有时还会被拉长,如同鬼片。
但是稍微写实一点的年轻夫妇在大雨中行走就很怪异,上半身还好,下半身的脚忽隐忽现,有时还会被拉长,如同鬼片。 还有一些绘画风格的视频,宇宙飞船登陆火星,穿着晚礼服的夫妇被困在倾盆大雨中,阳光洒在桌上,会动的熊猫玩偶。从细节上看,这些视频都不够完美,但仅仅从 AI 文字转视频的创新效果来看,还是让人惊叹的。
还有一些绘画风格的视频,宇宙飞船登陆火星,穿着晚礼服的夫妇被困在倾盆大雨中,阳光洒在桌上,会动的熊猫玩偶。从细节上看,这些视频都不够完美,但仅仅从 AI 文字转视频的创新效果来看,还是让人惊叹的。


 静态的油画也可以在 Make-A-Video 帮助下动起来——船在大浪中前进。
静态的油画也可以在 Make-A-Video 帮助下动起来——船在大浪中前进。 海龟在海中游动,最初的画面非常自然,后面变得更像绿幕抠图,不自然。
海龟在海中游动,最初的画面非常自然,后面变得更像绿幕抠图,不自然。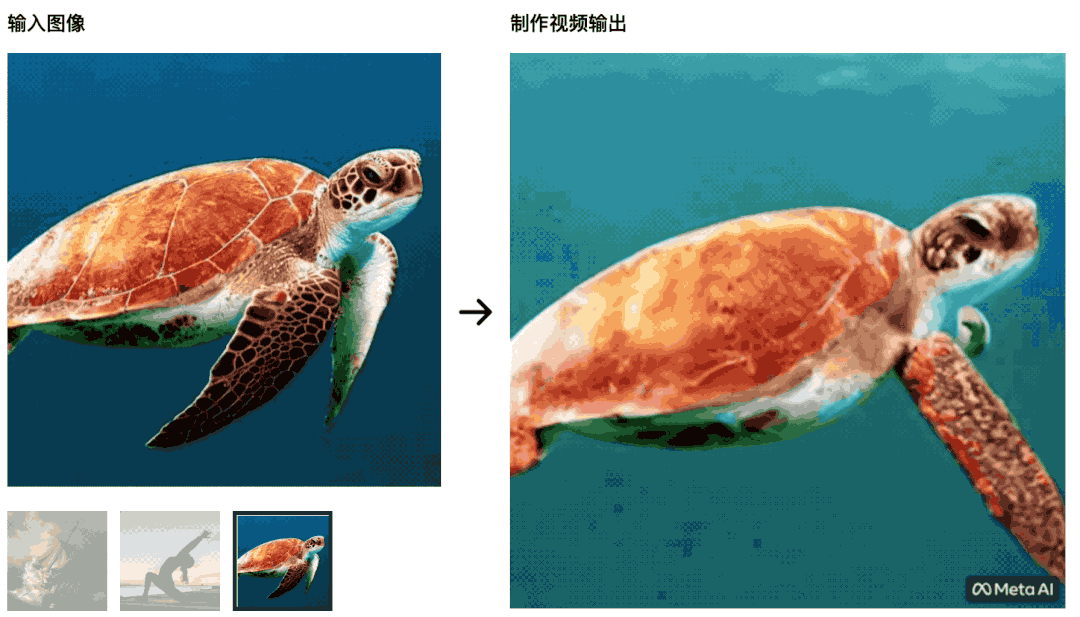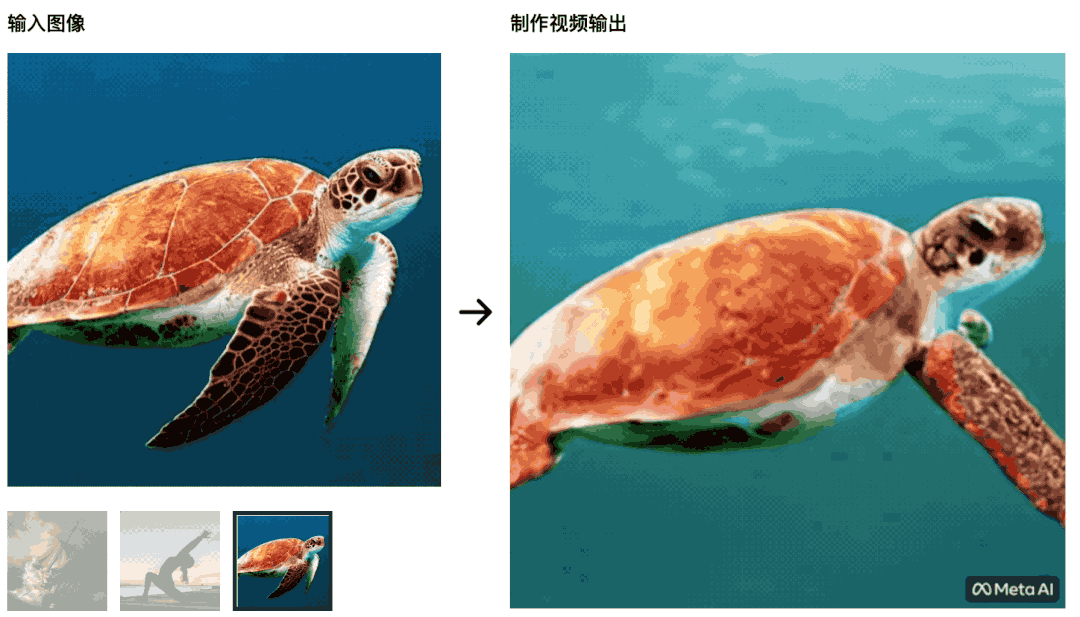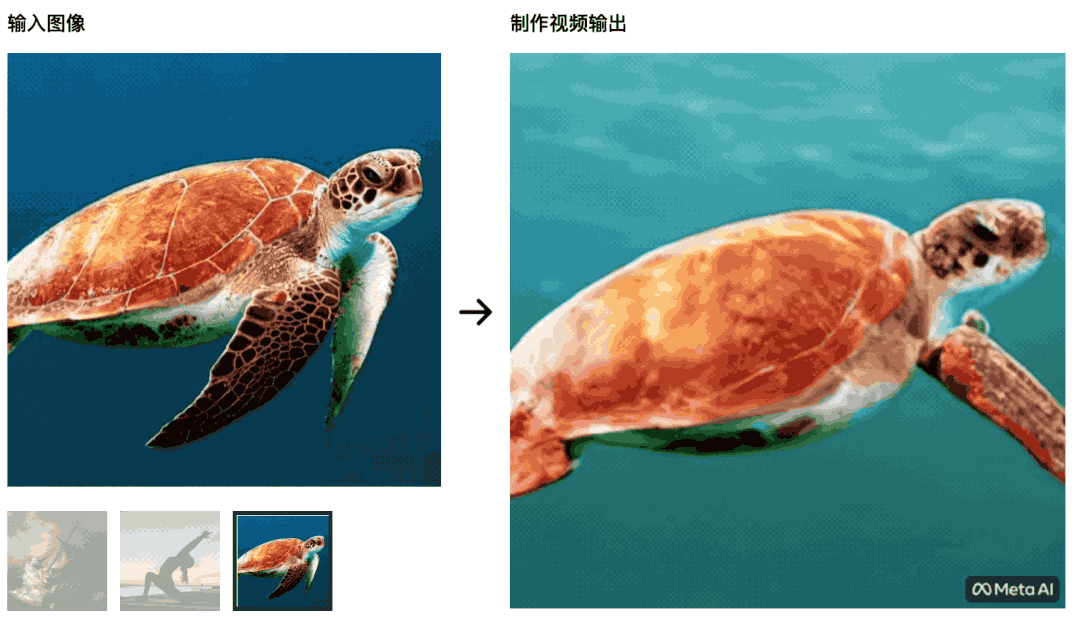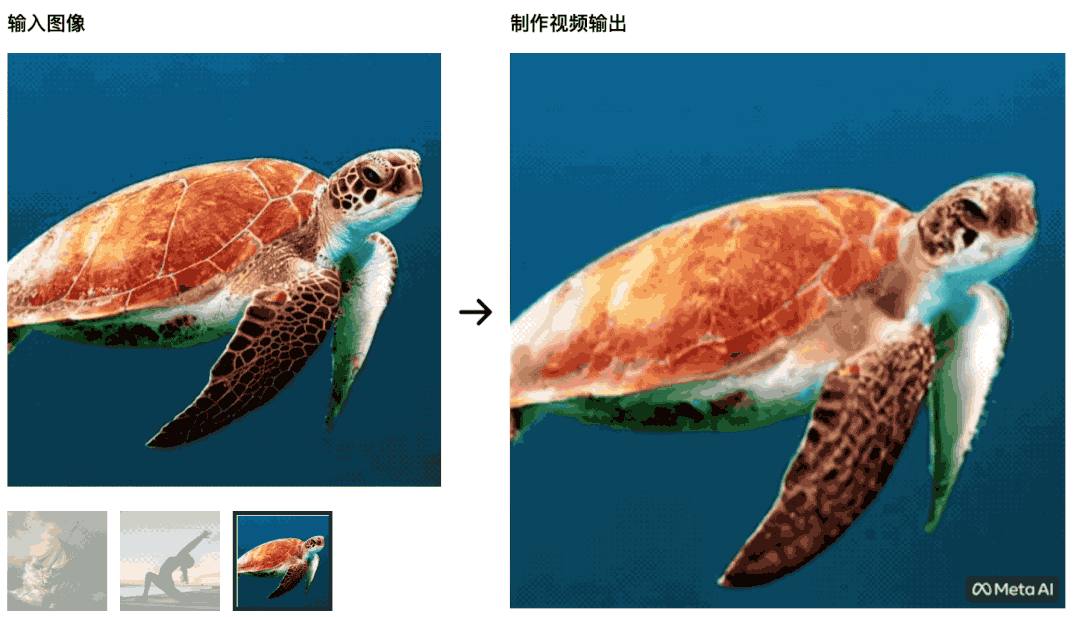 瑜伽训练者在朝阳中舒展身体,瑜伽垫也会随着视频的变化一起变化——这个 AI 就战胜不了学习影视制作的学生了,控制变量没做好。
瑜伽训练者在朝阳中舒展身体,瑜伽垫也会随着视频的变化一起变化——这个 AI 就战胜不了学习影视制作的学生了,控制变量没做好。 最后输入一个视频模仿其风格创造视频变体也有 3 种案例。
最后输入一个视频模仿其风格创造视频变体也有 3 种案例。其中一个变化相对来说没那么精致。宇航员在太空中飘舞的视频变为了美感稍弱版本的 4 个粗放版视频。
 小熊跳舞的视频倒是有不少令人惊喜的变化,至少舞姿有变化了。
小熊跳舞的视频倒是有不少令人惊喜的变化,至少舞姿有变化了。 至于最后兔子吃草的视频就是最「安能辨我是雌雄」的类型了,5 个视频最后很难认出谁是初始视频,看着都蛮和谐。
至于最后兔子吃草的视频就是最「安能辨我是雌雄」的类型了,5 个视频最后很难认出谁是初始视频,看着都蛮和谐。
02
文字转图片刚有进展,视频就来了
在《阿法狗之后,它再次彻底颠覆人类认知》中,我们曾经介绍过图像生成应用 DALL·E。曾有人用它制作出的图像去和人类艺术家 PK并最终取胜。
现在我们看到的 Make-A-Video 可以说是一个视频版本的 DALL·E(初级版)——它就像 18 个月前的 DALL·E,有巨大突破,但现在的效果不一定能让人满意。
 ▲
▲DALL·E 创作的延伸画作
甚至可以说,它就是站在巨人 DALL·E 肩膀上做出成就的产品。相较于文字生成图片,Make-A-Video 并没有在后端进行太多全新变革。
研究人员在论文中也表示:「我们看到描述文本生成图片的模型在生成短视频方面也惊人地有效。」
 ▲
▲描述文本生成图片的获奖作品
目前 Make-A-Video 制作的视频有 3 个优点:
加速了 T2V 模型(文字转视频)的训练
不需要成对的文本转视频数据
转化的视频继承了原有图像/视频的风格
 ▲
▲这个视频狗狗舌头和手有几帧非常怪异
几个月前清华大学和智源研究院(BAAI)研究团队发布的第一个能根据文本直接合成视频的 CogVideo 模型也有这样的问题。它基于大规模预训练的 Transformer 架构,提出了一种多帧率分层训练策略,可以高效的对齐文本和视频片段,只是也经不起细看。
但谁能说 18 个月后,Make-A-Video 和 CogVideo 制作的视频不会比大部分人更好呢?
 目前已经发布的文字转视频工具虽然不多,但在路上的却有不少。在 Make-A-Video 发布后,初创企业 StabilityAI 的开发者就公开表示:「我们的(文字转视频应用)会更快更好,适用于更多人。」
目前已经发布的文字转视频工具虽然不多,但在路上的却有不少。在 Make-A-Video 发布后,初创企业 StabilityAI 的开发者就公开表示:「我们的(文字转视频应用)会更快更好,适用于更多人。」有竞争才会更好,越来越逼真的文字转图像功能就是最好的证明。
文末互动:
你认为随着科技发展,音频图像制作人会失业吗?
👇评论区留言告诉我们你的想法哦~

UpHonest Capital 威诚资本
成立于2015年,由硅谷知名投资人郭威创立 ,以全球化视角 ,专注投资硅谷和中国的早期优质初创企业。成立至今,机构累计投资超过400家初创企业,30个独角兽项目。UpHonest Capital立足跨境创新,通过运营旗下拥有10w+影响力的科技自媒体、国际化孵化加速平台、覆盖硅谷科技人才的智库与活跃的创业者社群等多元业态,深耕早期孵化投资,构建了独特且完善的早期跨境投资生态,赋能未来创变者。


别忘了点关注,不迷路啊。
👇👇👇


创业即巅峰,她的抑郁症自我救赎之路,是冲进两千亿市场