
如何排查系统的性能瓶颈点?
梳理系统的性能瓶颈点这件事应该不是一件简单的事情,需要针对不同设计的系统来进行单独分析。
首先一套完整可用的系统应该是有ui界面的(这里强调的是一套完整的,可用的系统,而并不是指单独的一个中台系统),系统分为了前端模块和后端模块。
这里由于我个人的擅长领域更多是处于后端模块,所以对于系统的瓶颈点梳理我会从后端进行分析。
这里我结合常用的nginx+tomcat+redis+mysql这类常见架构进行分析:
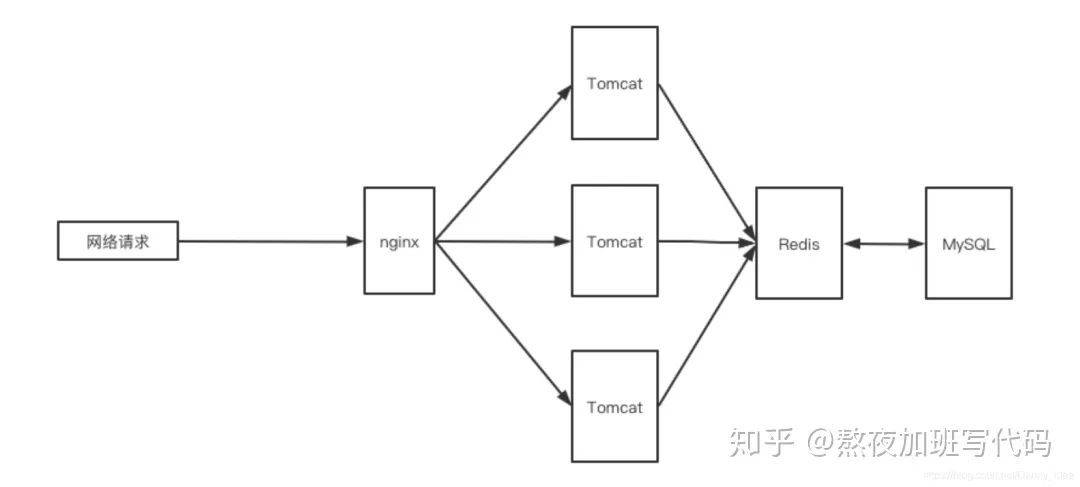
请求入口 所有的请求打入到后台的服务当中,首先需要考虑的一个点就是:
带宽因素:
假设有200m的流量同时请求进入服务器,但是带宽只有1m,这么来算光是接收这批数据量信息也要消耗大约200s的时间。带宽可以理解为在指定时间内从一端请求到另一端的流量总量。而且局域网和广域网的带宽计算其实也是不一样的,
服务器的ulimit
通常我们使用的线上服务器都是centos系列,这里我列举centos7相关的系统配置:ulimit配置 查看服务器允许的最大打开文件数目(linux系统中设计概念为一切皆文件) 通常如果我们的java程序需要增大一些socket的链接数目,可以通过调整ulimit 里面的open参数进行配置。
[root@izwz9ic9ggky8kub9x1ptuz ~]# ulimit -a | grep open
open files (-n) 1000
查看用户的最大进程数目
[root@izwz9ic9ggky8kub9x1ptuz ~]# ulimit -a | grep user
max user processes (-u) 7284
相关的配置存放在了/etc/security/limits.conf文件中。
系统的一些内核参数配置
如果是在一些压力测试场景中,我们通常会预见到这种报错:
apr_socket_recv: Connection reset by peer (54)
通常这种情况是因为系统内部的一些防范参数设置导致的,需要调整/etc/sysctl.conf 文件中的相关参数:
net.ipv4.tcp_syncookies = 0
#当并发请求数目超过了1000之后,服务器自身可能会认为是收到了syn泛洪攻击,但对于高并发系统,要禁用此设置
net.ipv4.tcp_max_syn_backlog
#参数决定了SYN_RECV状态队列的数量,一般默认值为512或者1024,即超过这个数量,系统将不再接受新的TCP连接请求,一定程度上可以防止系统资源耗尽。可根据情况增加该值以接受更多的连接请求。
net.ipv4.tcp_tw_recycle
#参数决定是否加速TIME_WAIT的sockets的回收,默认为0。
net.ipv4.tcp_tw_reuse
#参数决定是否可将TIME_WAIT状态的sockets用于新的TCP连接,默认为0。
net.ipv4.tcp_max_tw_buckets
#参数决定TIME_WAIT状态的sockets总数量,可根据连接数和系统资源需要进行设置。
对于防范参数还可以如下修改查看:
cd /proc/sys/net/ipv4
echo "0" > tcp_syncookie
通常企业中使用的都是nginx进行接收请求,然后进行负载均衡转发。在nginx层里面会有几个核心参数配置:最大连接数,最大并发访问数
#指定同一个ip的每次请求数量都限制为10次
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn perip 10
Tomcat部分分析
Tomcat支持三种接收请求的处理方式:BIO、NIO、APR 。
1、Bio方式,阻塞式I/O操作即使用的是传统Java I/O操作,Tomcat7以下版本默认情况下是以bio模式运行的,由于每个请求都要创建一个线程来处理,线程开销较大,不能处理高并发的场景,在三种模式中性能也最低
2、Nio方式,是Java SE 1.4及后续版本提供的一种新的I/O操作方式(即java.nio包及其子包),是一个基于缓冲区、并能提供非阻塞I/O操作的Java API,它拥有比传统I/O操作(bio)更好的并发运行性能。tomcat 8版本及以上默认nio模式
3、apr模式,简单理解,就是从操作系统级别解决异步IO问题,大幅度的提高服务器的处理和响应性能, 也是Tomcat运行高并发应用的首选模式。启用这种模式稍微麻烦一些,需要安装一些依赖库, 而apr的本质就是使用jni技术调用操作系统底层的IO接口,所以需要提前安装所需要的依赖,首先是需要安装openssl和apr
tomcat连接参数调整
在tomcat中有这么一段经典的配置参数:
"80" maxHttpHeaderSize="8192"
maxThreads="4000" minSpareThreads="1000" maxSpareThreads="2000"
enableLookups="false" redirectPort="8443" acceptCount="2000"
connectionTimeout="20000" disableUploadTimeout="true" /
maxThreads表示tomcat最多可以创建多少个线程来处理请求。
minSpareThread表示tomcat一开始启动的时候会创建多少个线程,即使是闲着也会创建。
maxSpareThread表示tomcat创建的最大闲置线程数目。一旦tomcat创建的线程数目达到这个瓶颈,那么就需要进行线程的回收了。
connectionTimeout表示连接的超时时长。
假设我们同时有1000个请求并发访问,但是一台tomcat的maxThreads只设置为了500,那么此时就会出现请求拥塞的情况,也就是瓶颈点之一。
Redis部分性能瓶颈分析
一些大key的查询,导致网络出现拥塞情况
例如说往一个list集合中存储了50m的数据,一旦发生list全量查询,同时又有其他指令在进行访问的时候,就容易会导致网络堵塞。因为redis的设计为单线程处理请求,所以其他指令发送到redis服务端的时候,都需要等待redis将之前的任务处理完毕之后才能继续执行。
线上环境出现了一些”违规操作“
比较常见的违规操作:批量执行keys指令
在redis处于高qps的状态下,随意一个keys指令都可能是致命的。keys指令的时间复杂度是O(n)级别,容易导致一时间系统的卡顿。
内存空间不足
当redis处于内存空间不足的时候,基本就是整个系统处于瘫痪作用。因此我们在对每个存储在redis中的数值都需要设置一个合理的过期时间,以及需要思考存储数据的体积大小。
MySQL部分性能瓶颈分析
通常我们在分析sql查询方面都容易出现一个误区,就是上来直接进行explian分析,但是却忽略了系统的运作上下文环境。
假设有一张t_user表,已经存储了几千万的数据,并且也对用户的id进行了索引建立,但是sql执行速度依旧是超过1s时长,这个时候就需要换一种思路进行分析了。
例如从表的拆分方面进行思考,是否该对表进行横向拆分,拆解为t_user_01,t_user_02......
以下是我总结的一些对于数据库层面可能出现性能瓶颈的几点总结:
1.锁
排查是否会存在锁表的情况导致数据库响应缓慢。
2.sql查询还有优化空间,有待完善
通常我们对于sql的执行分析都会使用explain命令进行查看:
这里我贴出了一张关于explain的常用参数含义表供大家参考:

3.查询出的数据量过大
例如说一条sql直接查询了全表的数据信息量,直接占满了网络带宽,因此访问时候出现了网络拥塞。
4.硬件设备不足
例如在面对一些高qps的查询时候,数据库本身的机器硬件配置较低,自然处理速度会比较慢。
5.自适应hash出现锁冲突
AHI是innodb存储引擎特有的属性,innodb存储引擎会针对索引数据的查询结果做自适应的优化,当某些特定的索引查询频率特别高的时候会自动为其建立hash索引,从而提升查询的效率。相比于B+Tree索引来说,hash索引能够大大减少对于io的访问次数,“一击命中” 查询数据,具备更加高效的性能,而且hash索引是由mysql内部自动适配的,无需dba在外部做过多的干预。
早期版本的hash索引是采用了单锁模式来防范并发访问问题,这对于程序自身的一个运作高效性有一定的”折扣“,后期通过对hash索引进行了分区,不同页的数据用不同的hashtable,每个分区有对应的锁来做并发访问的预防。
如果某天你发现了有很多线程都被堵塞在了RW-latches的时候,有可能就是因为hash索引的并发访问负载过高导致的堵塞,这个时候可以通过增大hash索引的分区参数,或者关闭自适应hash索引特性来进行处理。