
Node 服务端系统架构设计基本思想及常见场景解决方案
回复1,加入高级 Node 进阶交流群
作者:lusq (作者授权转载)
链接:https://juejin.cn/post/6940523830658105351
说明:本文覆盖了很全面的 Node.js服务端系统架构设计内容,想深入学习Node服务端的小伙伴(之前群里有小伙伴问过这部分内容学习路线),因很难一篇文章详细介绍,可以把本文内容当作学习大纲,一一突破,加油!
写在前面
本文旨在给前端同学在进行nodejs服务端项目的架构设计时提供一些基本思路及常见场景的解决方案。开发node服务本质上属于服务端开发的范畴,但由于今时今日nodejs开发各种应用的普及、前端工具链向服务端的延伸等,对前端同学全栈开发能力的要求也日渐提高,故写下此文。由于服务端开发本身是一个非常庞大的话题,本文会结合一些浅显易懂的实例来进行快速覆盖。同时在文章最后,我会以我在公司最近对前端统一打包服务的分布式改造及多节点部署为例子,来结合一些实践进行描述
分布式、集群
分布式
什么是分布式?
将系统的一个部分拆分成一个单独的服务,系统内部服务间可进行相互的调用,系统对外仍形成一个整体
典型场景
服务端开发时需要进行一些数据存储,往往我们会用到mysql这样的数据库,而不是将数据存储在应用节点中,这时其实就已经是一个简单的分布式系统了,应用通过网络协议来读写数据库,同时应用和数据库一起对外形成一个服务整体
架构图
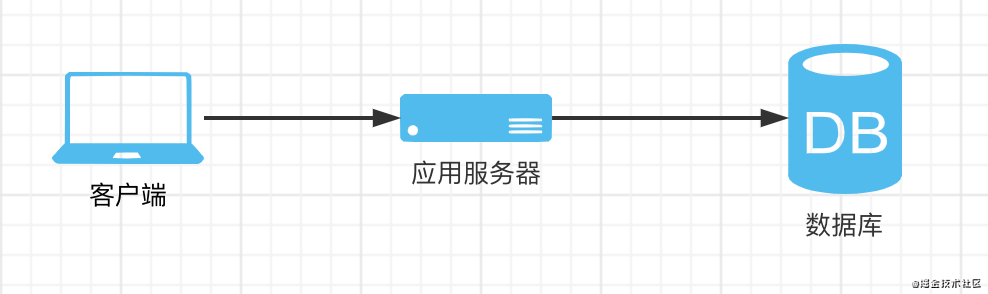
集群
什么是集群?
刚说到的分布式中,应用和数据库显然在系统中提供着不同的功能,而当我们部署多个相同的应用节点时,这些应用节点就形成了一个应用集群,可见集群就是系统中多个提供相同功能的节点形成的一个整体
典型场景
在集群的概念中其实已经提到了一个典型场景,就是我们在部署node应用时,尤其是在生产环境,一般会部署至少两个以上的应用节点,来提供更强的业务处理能力,同时减少因部分节点宕机对系统整体造成的影响,这样就形成了一个应用集群
架构图
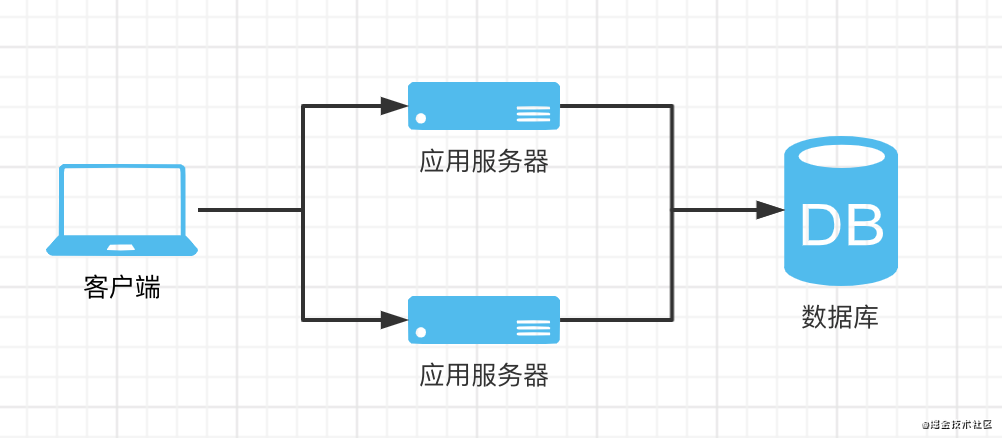
单点故障、高可用
单点故障
什么是单点故障
所谓单点,也就是系统内某个服务只有一个节点,比如我们的node应用,此时如果程序崩溃或服务器宕机,则系统整体对外表现为不可用,于是形成了单点故障
解决方案
同一服务在多个机器部署多个节点,此时一台机器或一个服务出现问题,系统整体对外表现仍可用,所以前面提到的应用服务器集群已经就可以解决这个问题
高可用
什么是高可用
系统可以持久的保持对外正常的服务
解决方案
前面的单点故障其实就是导致系统无法实现高可用的一个典型问题,所以部署多个应用节点形成集群仍然是系统实现高可用的一种基本解决方案
平滑发布
什么是平滑发布
node服务发布时往往需要停止服务,再以新的代码重新启动服务,在此期间如果系统仍可以保持对外的正常服务,则称为平滑发布
解决方案
当系统存在多个应用节点时,实际上已经具备了平滑发布的基本条件,如系统已部署两个应用节点A、B,则只需要在发布时先停止节点A的服务,发布A节点,等A节点发布结束再同理发布B节点即可
负载均衡
什么是负载均衡
如前文提到的,假设系统中应用节点已部署了多个,则客户端请求需要由一个服务根据某种策略来向各应用节点进行请求分发,让多个节点都能对外提供服务,此时客户端请求对系统来说称为负载,而所谓均衡,即使用某种分发策略以达到让多个节点都能相对均匀的分配到客户端请求
解决方案
nginx作为常见的web服务器其实就具备负载均衡的能力,我们可以以一台nginx作为应用集群的前置服务器,nginx可将请求随机分发给多个应用节点,当然也可以配置一些其他策略,如根据ip hash、按节点权重分发等
架构图
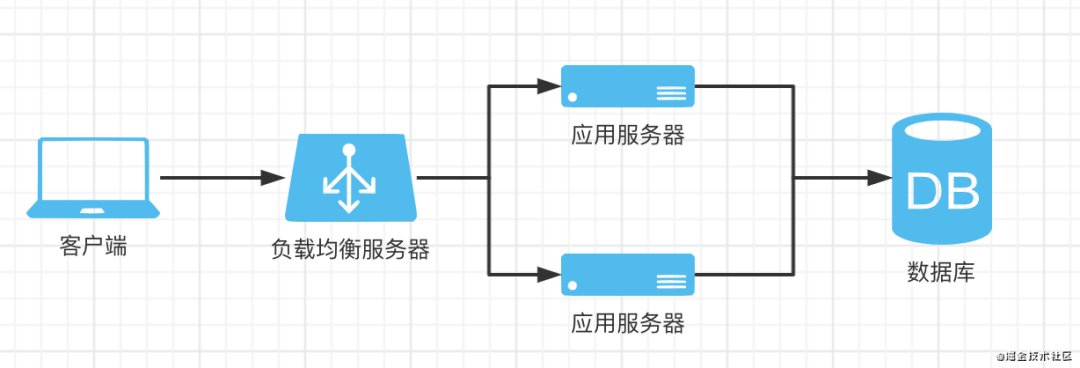
持久化存储、缓存、分布式缓存
什么是持久化存储
可以对数据进行长期保存的服务,如mysql等数据库,而要做到持久存储,通常需要将数据以文件的形式存储到磁盘中
什么是缓存
缓存对于前端同学来说应该不陌生,一般将存取速度较快的存储称为缓存,而存取速度的瓶颈往往取决于存储介质,比如持久化存储,一般以磁盘文件的形式保存数据,而磁盘文件的I/O速度显然远低于内存I/O,所以通常缓存都是以内存作为存储介质,如redis,甚至比如在node程序中直接将数据保存到一个js对象中,其实也是一种简易的缓存
分布式缓存
什么是分布式缓存
如前文所述,显然分布式缓存就是独立成一个单独服务的缓存,如redis等
为什么需要分布式缓存
假设我们的系统中存在多个应用节点,客户端发出一个请求存储一些数据,负载均衡将请求分发给某个应用节点,此时如果未使用分布式缓存,该节点将数据缓存在自己node进程的内存中,当客户端再次请求拉取该数据时,此时负载均衡仍会随机分发请求给一个应用节点,而如果此时收到请求的节点和之前存储请求时不一致,则该节点中无对应数据,导致数据拉取失败。可见我们需要一个对应用集群中心化的存储来解决此类问题
解决方案
任意节点收到数据存储请求后,将数据存储到分布式缓存中,如redis,则客户端拉取该数据时,应用节点仍从redis中获取对应数据响应给客户端
架构图
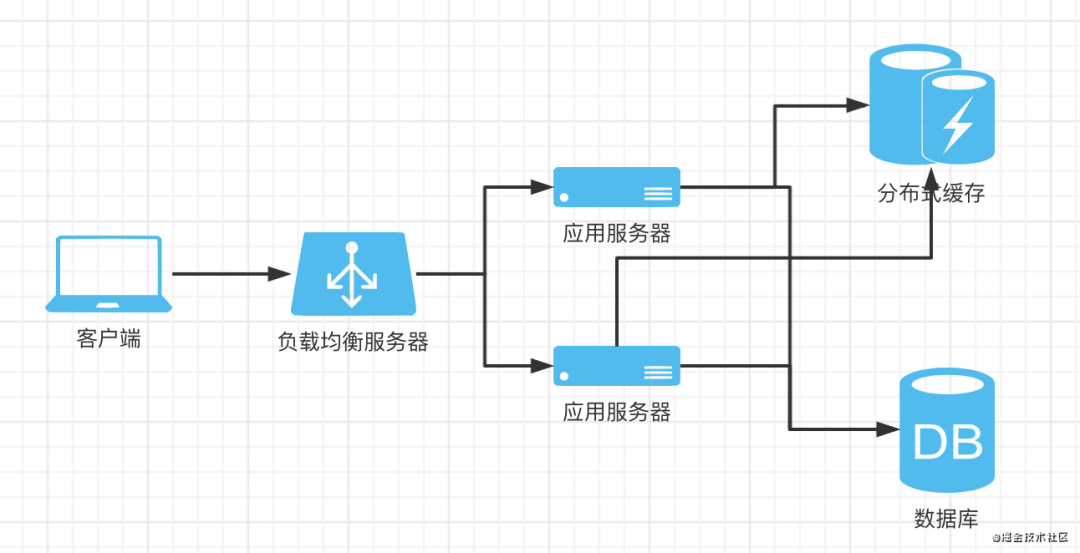
消息队列
什么是消息队列
所谓消息,其实就是一种特定结构的数据,显然,消息队列则是一种特定结构数据形成的一个FIFO的数据结构,通常用redis或其他更专业的mq(message queue)来实现消息队列
使用场景
见下文紧接着的异步任务部分
异步任务、定时任务
异步任务
一个常见场景是我们的node应用对外提供基于http的服务,系统收到一个http请求,执行一些业务逻辑,再通过http响应给客户端。现在假设业务场景是用户注册,服务端业务逻辑需要执行一系列操作,如创建用户、保存用户到数据库、再给该用户邮箱发一封邮件等等,此时如果所有操作同步执行完成再响应给客户端用户创建成功,可能耗时很久,而系统响应速度是用户体验或者说系统性能的一个重要指标。于是可以将部分耗时且对主要业务业务成功与否影响较小的逻辑(如这里的发送邮件)的待处理数据先发送到消息队列保存起来,然后立刻向客户端响应用户创建成功,然后异步的从消息队列获取用户数据并执行发送邮件的操作,而消息队列的FIFO特性可以让这些任务以http请求的顺序来依次处理
架构图
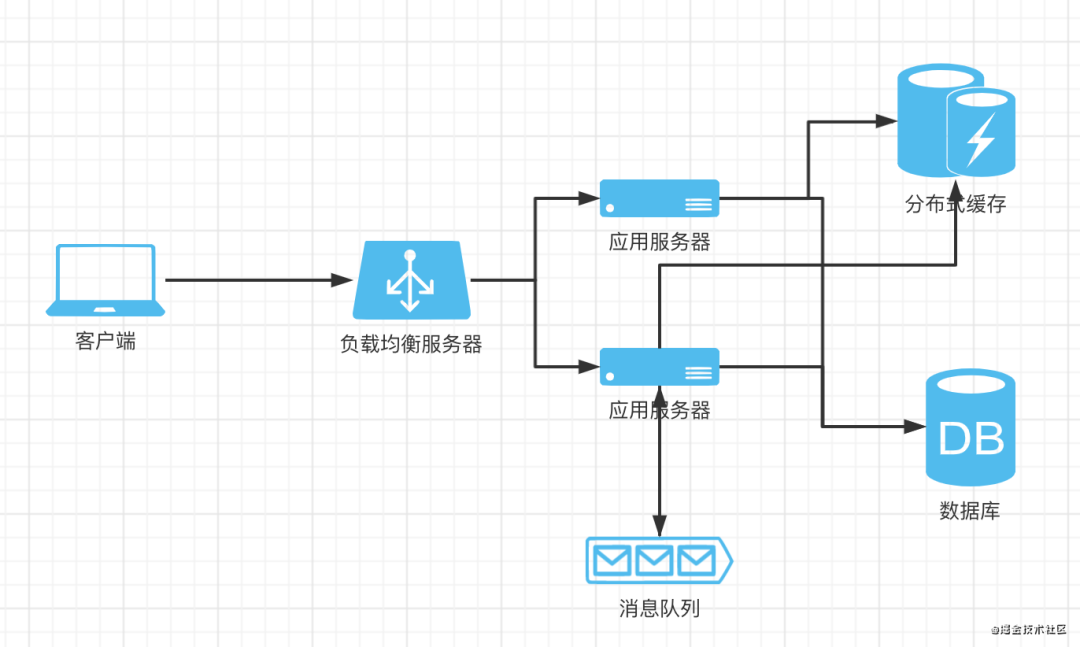
定时任务
定时任务比较好理解,如我们的node服务中可以起一些进程以一定时间周期去执行一些任务,如每天计算一次当天访问系统的用户年龄的平均值
长连接和websocket
什么是长连接
简单来说,当客户端与服务端建立一个长时间的网络连接,则称为长连接。而常见http协议,底层基于tcp,虽然tcp本身并不对连接时长做限制,但由于http自身作为应用层协议的设计理念,一次请求响应模型结束后即可断开连接,而当我们在node服务中使用websocket和客户端进行长时间、多次往返的双工通信时,则可称为长连接
使用场景
如前文所述,当需要处理的业务不适合由一次简单的请求响应模型来解决,而客户端和服务端双方需要进行长时间、多频次的双向数据交互时,则可考虑使用长连接,如websocket
高并发
最后简单聊下高并发,所谓高并发就是指同一时间系统需要处理大量客户端请求的场景,而我们的nodejs使用了单线程、非阻塞I/O配合事件驱动的底层模型,此模型在处理高并发请求时有着天然的优势(当然并不绝对)。好了,关于nodejs的高并发本文不深入讨论,如果有兴趣可参考我之前的一篇文章:https://juejin.cn/post/6844904054120792071
实际案例
前端统一打包服务的分布式改造、多节点部署
背景
公司前端发布系统底层由一个统一打包服务提供前端项目的打包功能,技术上是一个使用了eggjs的node项目。基本业务逻辑是客户端发起打包请求,服务端接受请求,从代码仓库下载项目代码,安装依赖,执行打包脚本,并通过websocket向客户端推送打包过程中产生的log,打包结束后将最终的打包结果上传到服务器。可参考下面的流程图
由于每个打包任务对系统资源都有一定消耗,如cpu、内存等,而系统资源存在上限,所以在程序中维护了一个任务队列,确保同时处理的打包任务不超过一定数量,多出来的任务以FIFO的方式进行排队处理
改造前的问题
应用服务器为单节点部署,无法实现基本的高可用、平滑发布等,且由于同时处理的打包任务数取决于系统资源上限,而随着全公司各前端团队发布需求的日渐增多,排队现象也越来越严重,影响到整个公司前端项目的发布效率
可能的一种解决方案及问题
既然系统资源是瓶颈,那么可不可以直接升级系统的硬件资源呢?答案是可以,但不是一个良好的、易执行、可拓展的解决方案。首先直接加硬件资源有时候就不是一件容易的事情,虽然可以用一些虚拟化技术来解决;其次如果按现有需求增加了一定的系统资源,等过段时间需求又增加了则需要再次进行硬件资源的扩充,这样显然不是一个容易执行且扩展性好的方案。同时,应用单节点部署无法做到基本的高可用和平滑发布,也在一定程度上影响了系统的稳定性及用户体验
解决方案之多节点部署
首先,多节点部署好说,只需要将同样的应用程序部署到多台服务器,再由nginx前置做请求分发即可。但如果只是这样,会引发一些严重的问题
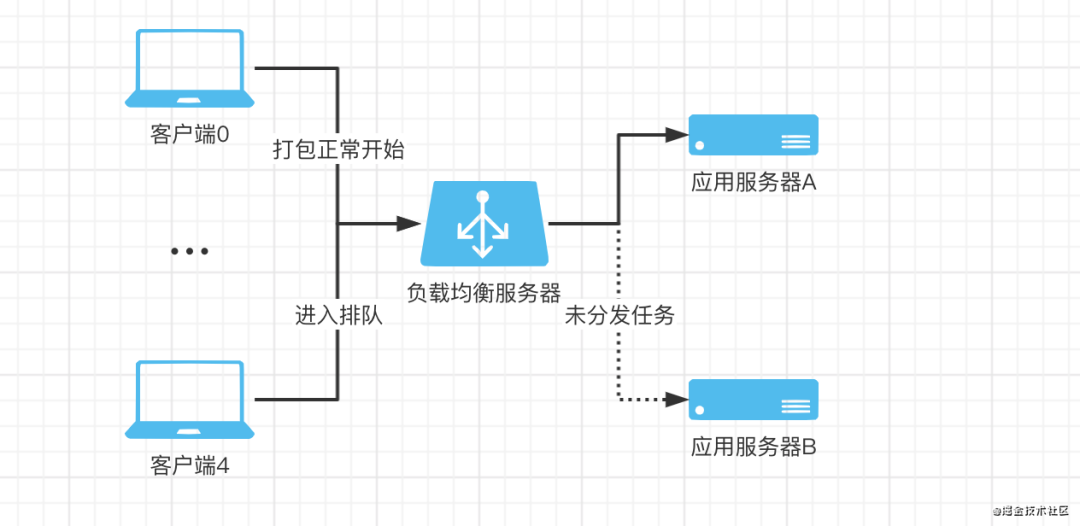
问题1. 假设一台服务器同时能处理的打包任务为4个,那么部署两台服务器则应该能同时处理8个任务。考虑一个场景,有5个打包请求过来,假设都正好被nginx随机分发到了同一个应用节点,会发生什么?该应用节点处理了前4个任务,而第5个任务进来后由于超出该节点能同时处理的最大任务数,该任务被应用置为了pending状态,也就是进入了排队逻辑。而对系统整体来说,明明能同时处理的最大任务数为8个,却在进来第5个任务时就造成了排队,这显然不符合我们的预期
问题2. 前面提到了,打包服务在打包过程中需要将产生的log通过websocket推送给客户端。考虑一个场景,假设现在有两台应用服务器A、B,客户端发起一个打包请求,nginx将请求分发给了节点A,同时由于客户端要通过websocket接收打包log,于是客户端又发起一个websocket的长连接,此时nginx又进行了一次分发,且将长连接建立到了节点B上,会发生什么?由于节点B中没有执行打包任务,也不会产生任何log,自然客户端通过该长连接接收不到想要的数据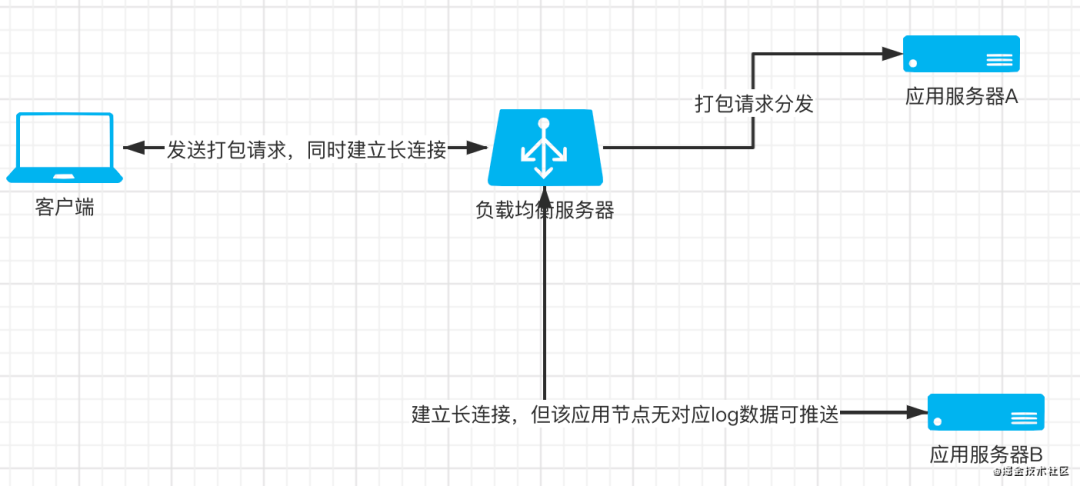
解决方案之分布式改造
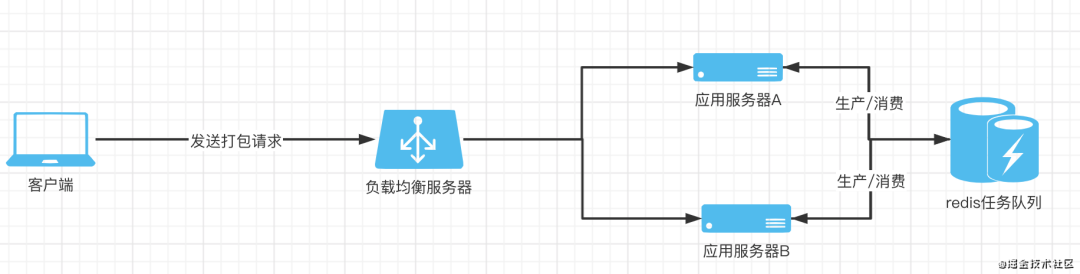
从上面的场景可以看出,其实两个问题的本质都出在某种应用状态被应用的某个节点进行了单独的维护,导致系统对外无法形成一个有效的整体,所以解决方案就是将这样的状态分布到应用集群外部,形成一个独立的、公共的服务。对于第一个问题,我采用了redis作为分布式缓存维护一个任务队列,各应用节点收到请求后先将任务发送到任务队列,所有节点再根据自身的任务处理情况拉取任务。这样同时也形成了一个生产/消费的模型,每个应用节点都作为生产者向任务队列生产任务,同时也作为消费者从任务队列拉取任务进行消费。这样就可以保证每个节点同时处理的任务不超过自身的限制,同时系统整体对外的服务逻辑也正常了
再来看第二个问题,本质上问题就是nginx在分发长连接的时候未分发到处理该打包任务对应的应用节点,导致客户端无法获取打包log。同样还是使用redis,将所有节点产生的log数据都先发送到redis中,再利用redis的发布/订阅功能,所有节点都提前订阅log发布的主题,当一个节点发布新的log数据到redis时,所有节点都能从redis获取对应log数据。至此,应用集群中所有节点都具备了推送系统中所有正在打包的任务产生的log的能力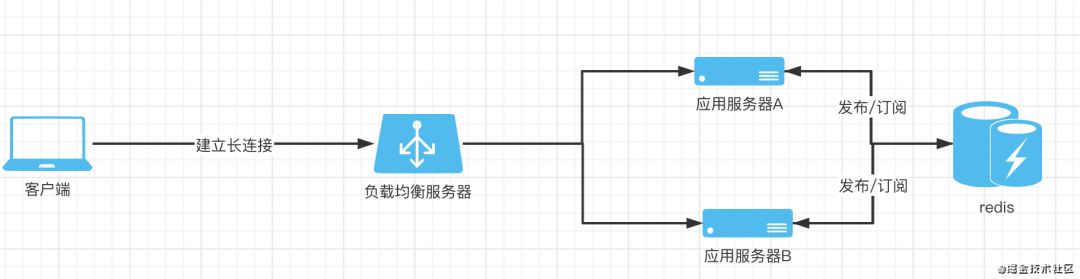
小结
至此,就通过分布式任务队列及生产消费、log数据的发布订阅和应用集群的系统架构完成了统一打包服务的多节点部署,实现了系统基本的高可用及平滑发布。而这样的架构发挥了一个更重要的意义,就是赋予了系统的水平扩展能力,即我们现在可以在系统整体服务能力再次不足时平滑的在集群中部署新的应用节点即可。(所谓水平扩展,在前文的架构图中就是纵向的方向,通常将系统从客户端向服务端延伸的方向称为系统架构的垂直方向,而垂直方向上的某一层次内部就是水平方向,比如我们上面的应用集群)
总结
其实无论是服务端或是客户端的架构设计,都是一个渐进的、逐步完善的过程,往往并不需要一上来就使用最复杂的架构,这样可能出现各方面资源的浪费、白白提升了系统的复杂度等问题,很多时候一个能满足需求、简单有效的架构才是一个好的架构。不过另一方面,系统设计者也需要具备一定的前瞻性,能对系统或用户需求未来的发展方向进行一些合理的预判,这样才能设计出扩展性更好的架构


“分享、点赞、在看” 支持一波 