
【大内存服务GC实践】- 一文看懂G1GC垃圾回收器


背景介绍
G1核心数据结构
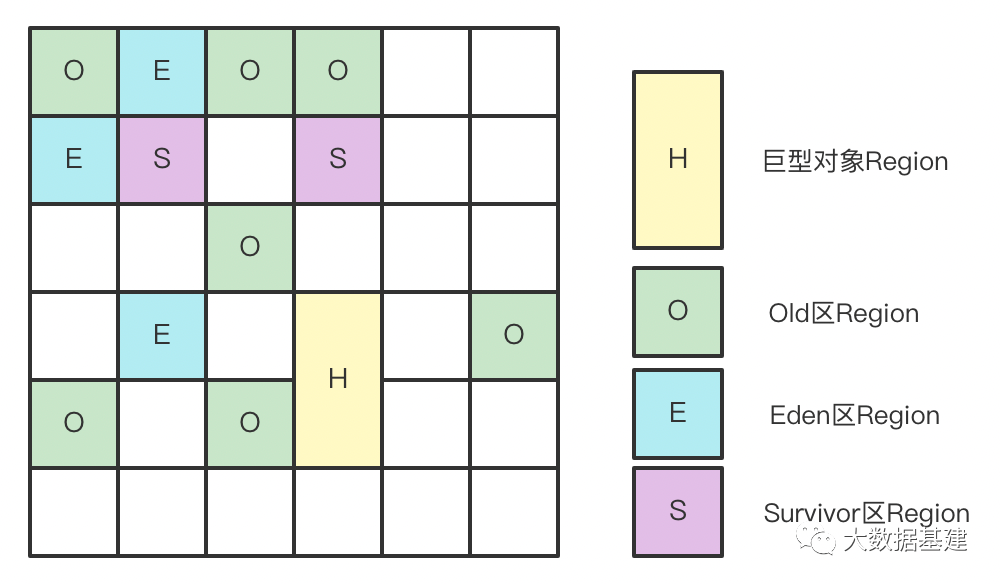
1. Region
2. RememberedSet(RSet)和Card Table
2.1 RSet是什么样的数据结构呢?
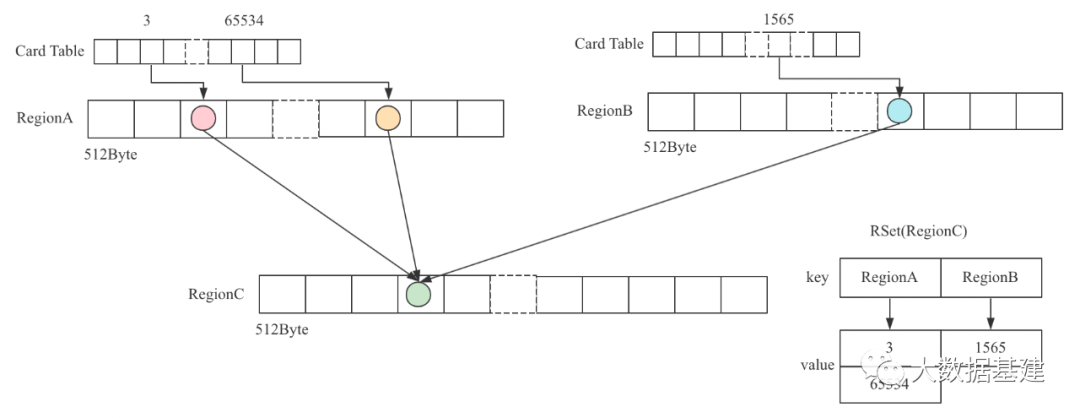
sparse per-region-table (PRT),从字面意思来看表示这个RSet是一个稀疏的集合。具体实现使用HashMap方式记录引用关系,其中Map的key是引用Region,value是一个List,List中存储引用Region中的引用Card列表。上文有过介绍。
fine-grained PRT,还是使用HashMap方式记录引用关系,其中Map的key是引用Region,但value不再是List,而是一个bitmap,bit位为1表示对应Card是引用Card,否则不是引用Card。
coarse-grained bitmap,从字面意思可以看出来这就是一个bitmap,不过bitmap中每个bit位引用粒度不再是Card,而是Region。如果bit位值为1,表示这个Region是引用Region,即这个Region中有对象引用了该Region中的对象。
很显然,上述3种实现方式中,spase PRT和fine-grained PRT都是精确到Card,而coarse-grained bitmap是精确到Region。
G1核心工作流程
1. Young GC核心流程
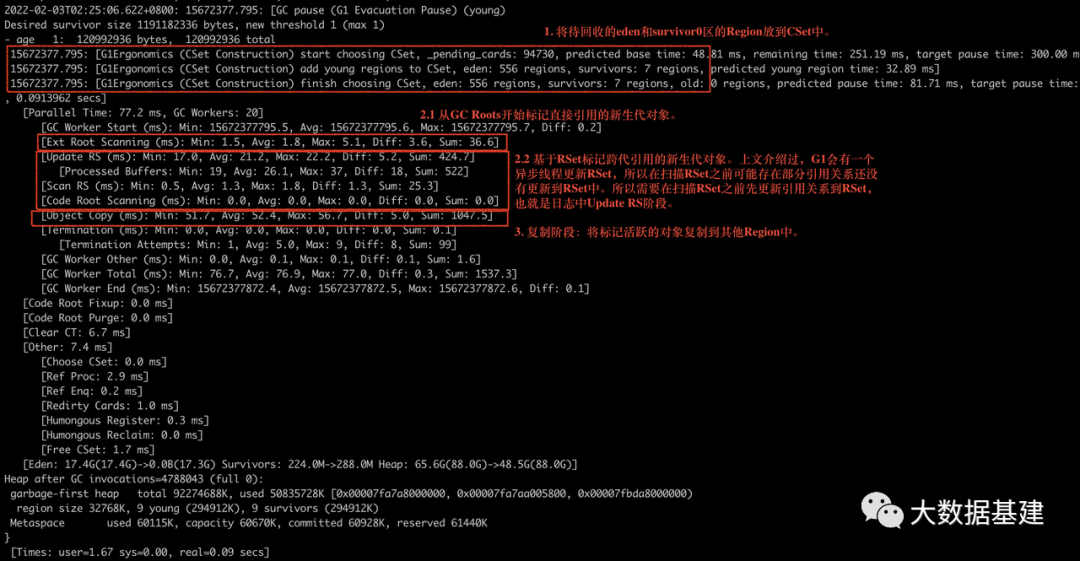
从GC Roots开始标记直接引用的新生代对象。 基于RSet标记跨代引用的新生代对象。
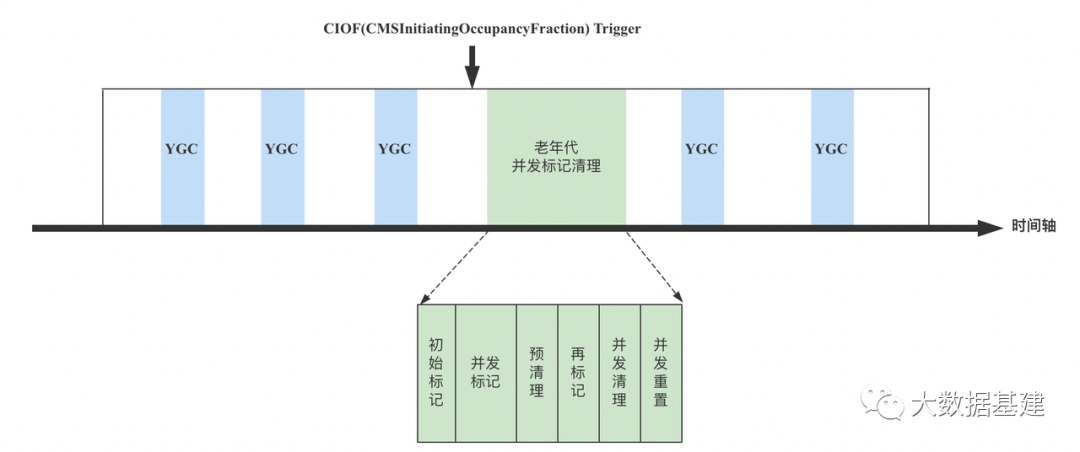
2. Concurrent Marking Cycle核心流程

初始标记(Initial Marking):初始化标记是伴随一次普通的YGC发生的,从GC Root开始标记直接可达的对象。
并发标记( Concurrent Marking):这个阶段标记线程和应用线程并发工作,遍历整堆所有可达对象并标记。这个阶段需要特别关注并发标记可能产生的"漏标"问题,G1使用Snapshot AT Begining(简称SATB)算法避免漏标问题发生,这和CMS完全不同。3.4小节深入介绍。
重新标记( Remark) :标记那些在并发标记阶段发生变化的对象,将被回收。 清理( Cleanup ):释放没有存活对象的Region。
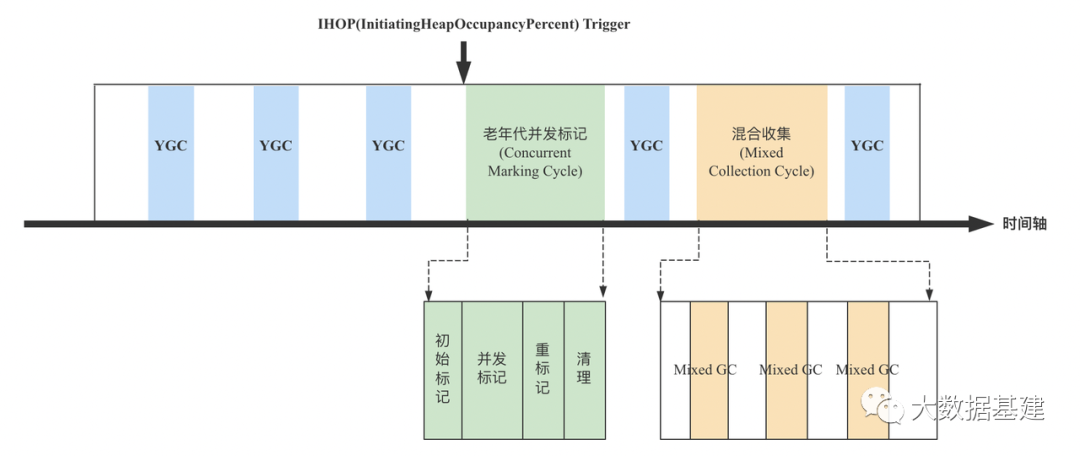
3. Mixed GC核心流程
4. 并发标记阶段对象"漏标"问题解法 - SATB算法
4.1 对象漏标简介
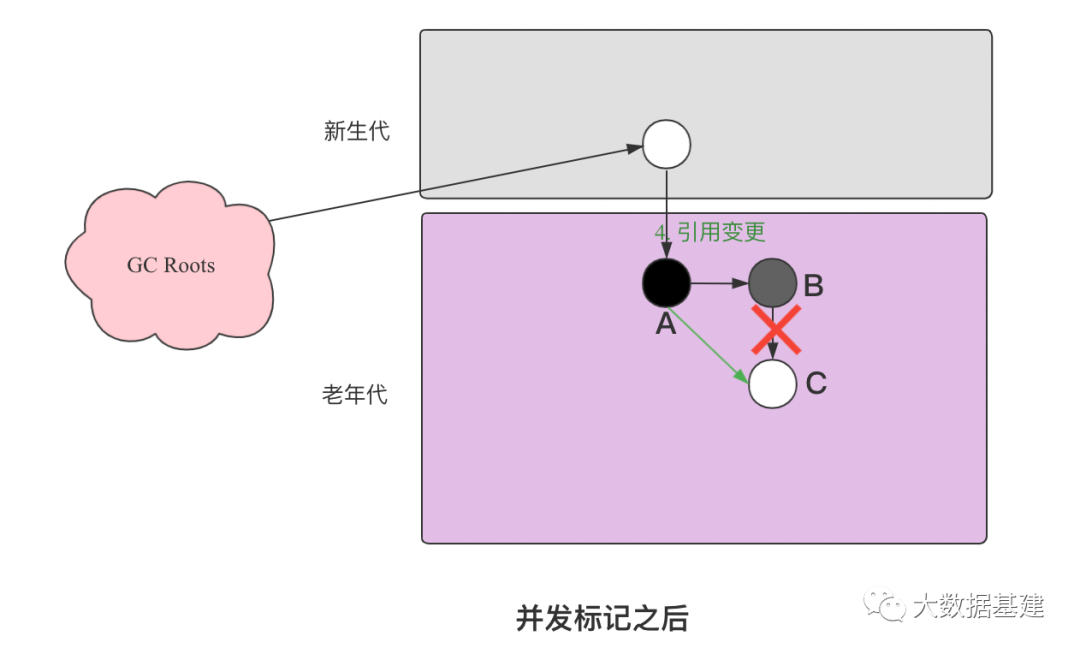
对象A已经被标记为黑色,表示为A为活跃对象且所有它引用的对象也完成标记。 对象B被标记为灰色,表示B对象是活跃对象,但是它关联的对象还没有被完全标记完。 对象C是白色,表示还没有被标记。
objB.fieldC = null;objA.filedC = C;
4.2 SATB算法思想简介
并发标记之前先给Region内存打个快照,标记线程基于这个快照独立进行标记。应用线程不会直接修改这个快照中的对象,也就是说应用线程不会干扰标记线程的工作。 应用线程新分配的对象都认为是活跃对象,实际在下一个并发标记周期进行标记。上文说过漏标发生的第一种场景是"应用线程在并发标记过程中新生成的活跃对象因为某些原因没有被标记线程标记",那如果能够将标记阶段新分配的对象全都集合到一起,这些对象全部都标记为活跃对象(实际肯定会有部分垃圾对象,将垃圾对象标记为活跃对象不影响程序正确性)就可以解决这个问题。 并发标记过程中已存在对象的引用关系变更在Remark阶段单独进行处理。上文介绍了漏标发生的第二种场景,为了解决这个场景引入的漏标问题,可以将引用关系变更分解为旧的引用关系先删除,新的引用关系生成两个步骤,只要破坏任何一个步骤就可以防止漏标发生。因此有两种针对性解法:
在并发标记阶段如果有新引用关系生成,就记录下来,Remark阶段进行重标记,这个破坏了步骤二,即黑色对象重新引用了白色对象,就记录下来重新扫描黑色对象,将其引用的所有对象都标记成存活对象。这个就是CMS垃圾回收器使用的增量更新算法。 在并发标记阶段如果有引用关系被删除,就记录下来,Remark阶段对这些引用关系被删除的重标记,这个破坏了步骤一,即灰色对象断开了白色对象引用的时候,记录下来,后面重新把这个白色对象标记成存活对象。这个就是G1垃圾回收器使用的算法。
4.3 SATB算法实现
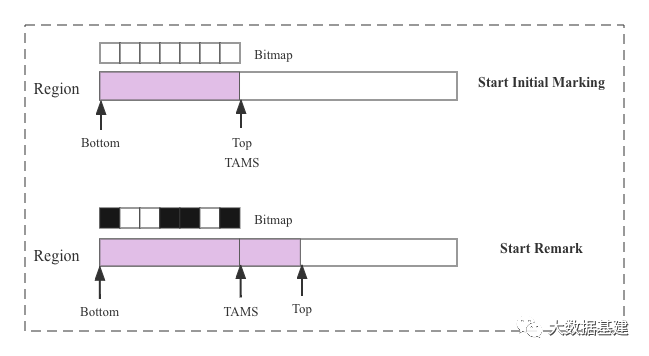
satb_mark_queue),在remark阶段会扫描这个队列,通过这种方式,旧的引用所指向的对象就会被标记上,其子孙也会被递归标记上,这样就不会漏标记任何对象,snapshot的完整性也就得到了保证。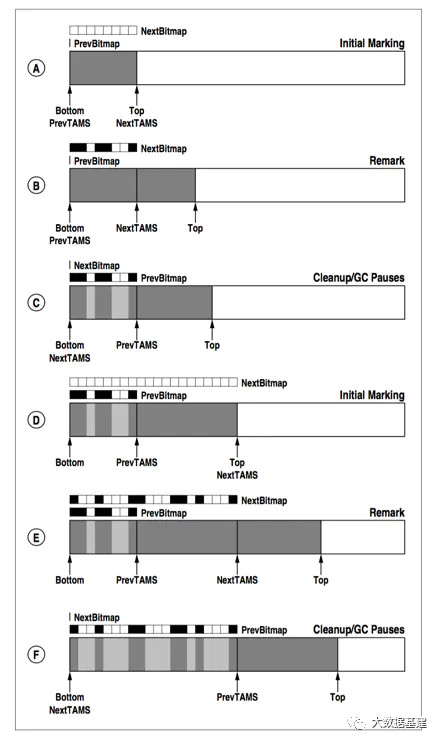
4.4 SATB算法 vs Incremental Update算法
全文总结
评论