
熬夜肝出 3w 字测试开发学习路线
本文将从薪水,职业规划,测试理论基础,自动化测试基础,常用自动化框架,计算机基础及 Python 高频面试题,测试相关高频面试题出发,详细内容如下,希望能对大家有所帮助。

薪水
我把它放在最前面,让大家能有一个基本的了解。综合下来,应届生在互联网公司的测开岗位薪水在 22~25 之间。
前景
我咨询身边认识的同学关于测开的前景。
测试的发展路线为两条,一条是业务型测试,另一个是技术型测试。业务型测试比较好理解,更加偏向业务,很可能最开始是从事测试方面的工作,后面去专门做了业务,其大概路线为功能测试,业务专家,行业业务专家,行业业务发展专家等,超级遥远的路罗。
对于技术型测试,更加偏向技术。从功能测试到测试开发,我遇到过一个测试,将开发的 Bug 揪出来就算了,还指导开发修改逻辑,哈哈哈哈哈哈,笑死我。其路线如下图哦
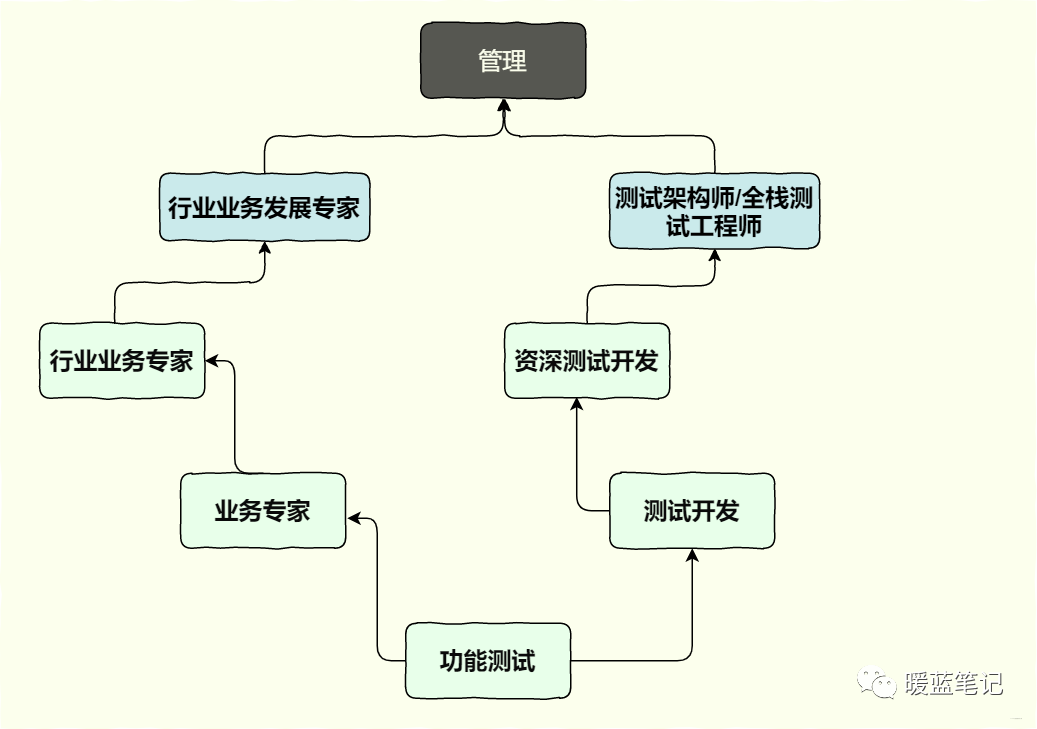
左侧为业务型测试,在工作中遇到一个姐姐,在银行外包大概工作了11年,后面转为行内的业务,甲方爸爸罗。当然是非常不容易的,所需要的付出不亚于走技术路线,不过你的业务路线会把自己的职业选择固定在某一个特定的领域。
右边是技术路线,职业选择还是挺广的了,功能测试,接口测试,性能测试,安全测试等等,也是面试的考察点,目前来看,纯粹的功能测试太少太少,几乎濒临淘汰罗,那么测试开发成为本文着重会说的复习内容。
测试开发本质
测试开发的本质是助力业务成功。感觉很多同学一上来就是学习编程技术,技术学习比较枯燥,计算机基础知识不扎实,很快就陷入了基础知识的泥沼。
在我看来了解基础理论后,学习 Python,Git 等必备技巧,熟悉一门自动化框架就可以解决测试相关的面试了。
软件测试存在的意义
通过一系列测试活动,「提前」发现和定位软件产品质量的薄弱环节,并倒逼开发人员修正,从而保证交付的软件质量满足客户需求。
有研究表明,越早发现软件中存在的问题,开发费用就越低,软件质量越高,软件发布后的维护费用越低。因此,提前发现和定位问题极为重要,而在软件开发的整个历程中,越是新兴的软件开发模型,越重视「提前测试」。提前测试可以使得在需求分析时期就可发现的错误,不必等到开发完成才被发现。
测试伴随着软件开发模型的演进
说到开发模型,从软件发展来看,比较典型的有瀑布模型,V 模型和 W 模型以及 敏捷开发模型。并不是说开发模型的选择越新越好,需要根据项目的具体情况而选择。
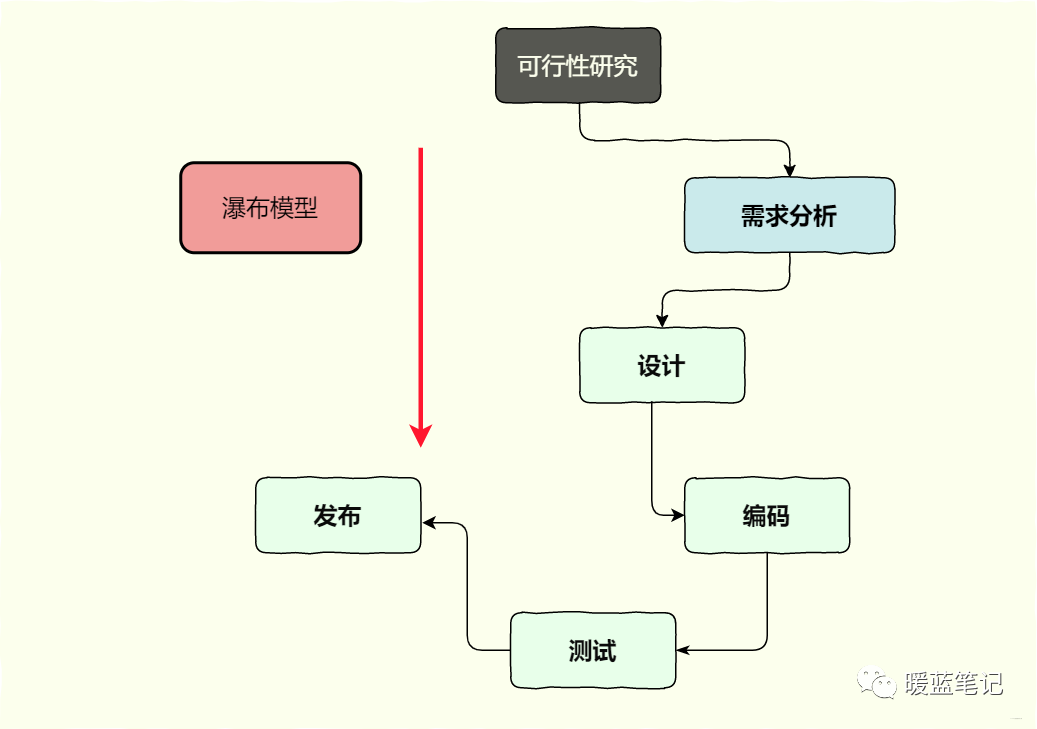
瀑布模型
我们知道,瀑布模型的主要特征在于项目完全按照阶段划分,只有前一阶段完成,才能开始下一阶段。具体到测试活动,则只能在全部编码完成后、发布之前执行,在这种开发模型中,测试活动被完全后置了,测试仅仅是编码后的一个活动阶段,测试的重要性没有被凸显出来。
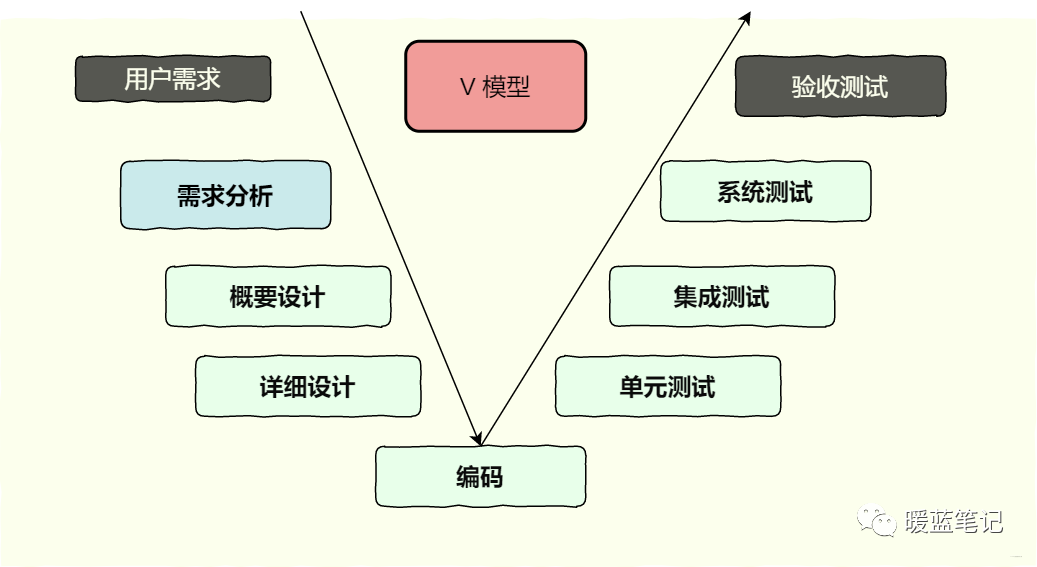
V 模型
基于此,V 模型出现了。V 模型在整个开发过程中,不仅相对清晰地划分了测试活动的不同级别,还将其不同级别的测试活动与软件开发各阶段清晰地对应起来,强调了测试在整个开发过程中的重要性。但在 V 模型中,测试依旧是编码之后才开始的,测试介入时间还是太晚。比如,需求分析阶段出现的问题,要等到系统测试阶段才能发现。
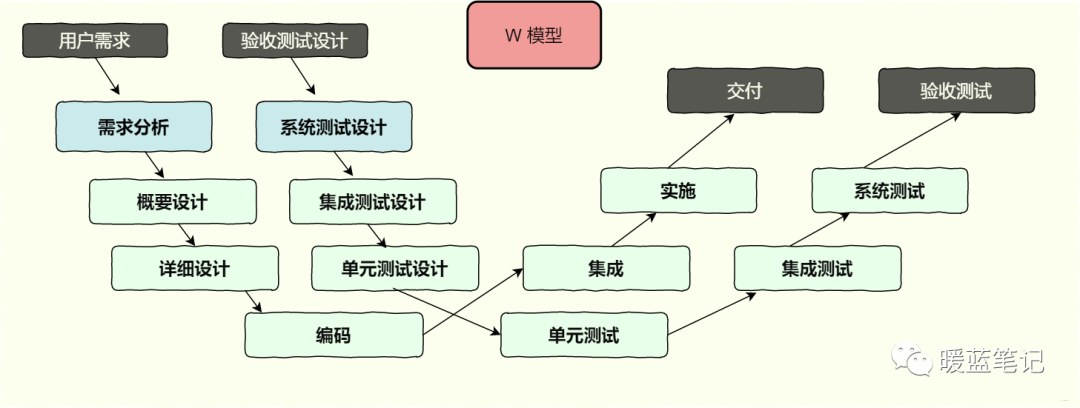
W 模型
为了弥补这一缺点,V 模型的进一步深化版,即W 模型出现了。从 W 模型的示意图中,可以看到,W 模型是把 V 模型左边的每一个活动都加了一个测试设计活动,体现了“尽早和不断地进行测试”的原则。
敏捷模型
敏捷过程模型”是指基于迭代开发的软件开发方法。敏捷方法将任务分解为较小的迭代, 或者部分不直接涉及长期计划。在开发过程的开始就确定了项目范围和要求。事先明确定义了有关迭代次数, 每次迭代的持续时间和范围的计划。
每次迭代都被视为敏捷流程模型中的短时间”框架”, 通常持续一到四个星期。将整个项目分成较小的部分有助于最大程度地降低项目风险, 并减少总体项目交付时间要求。每次迭代都涉及一个团队, 在整个软件开发生命周期中进行工作, 包括计划, 需求分析, 设计, 编码和测试, 然后再向客户展示有效产品。
职业生涯
软件测试开发流程
需求分析
在测试前拿到产品需求文档,进行需求分析及需求评审前先对需求文档进行详细的阅读,对有疑问的地方进行标注。
具体可从以下进行:
分析产品功能点
产品核心竞争力
Kano模型、马斯洛需求分析、多问几个为什么、上下文分析法
制订测试用例(重要)
工欲善其事,必先利其器;对测试而言,测试用例就是器,做好了才能把好关
使用思维导图列举测试大纲,尽量发散,想到什么就写什么,;先放后收,对知识点进行总结和归纳,标记重点测试模块,删除冗余及重复测试点。
可使用边界值法、等价类划分法、错误推测法、因果图法等设计案例
根据测试大纲制定测试用例,需包含模块名、测试优先级、操作步骤、期望结果、测试结果、备注
评审测试用例
测试作为主导,联合开发、项目经理、PM进行测试用例评审
可先讲解测试大纲,让开发、项目经理、PM心中对测试用例有个大概;后再进行详细测试用例讲解
执行测试
根据测试用例执行测试
发现问题保留现场,记录测试方法,通知开发解决问题
覆盖测试用例之外若有时间可进行探索性测试
提交 Bug 并推动 Bug 解决
在Bug管理工具上提交Bug,详细记录测试步骤
根据Bug严重程度划分Bug等级:致命、严重、一般、提示
推动开发解决问题,记录问题进展,一般聊天沟通,若问题严重则需通过邮件推动解决
回归测试
对已修复的 Bug 进行验证
对 Bug 所在模块进行基本功能测试;整体进行冒烟测试,确保不会因为修改 Bug 而引起其他功能出现问题
编写并提交测试报告
可使用金字塔原理设计测试报告,先总后分,上级统领下级,下级推导出上级,环环相扣
对Bug进行汇总,筛选出各个等级的Bug存活情况
制订Bug发现及解决曲线图,一般版本正常应是前期多,后期收敛,存活的是级别较低的Bug
总结归纳版本情况,评估发布与否
软件测试方法
白盒测试
概念:关注程序代码的具体细节,根据软件内部代码的逻辑结构分析来进行测试。主要是通过阅读程序代码或者通过使用开发工具中的单步调试来判断软件质量。关注代码的实现细节。主要对程序模块的所有独立执行路径至少测试一遍、对所有的逻辑判定,取“真”或“假”的两种情况都要测试一遍,循环边界和运行界限内执行循环体等等
测试用例设计方法:逻辑覆盖、循环覆盖、基本路径覆盖、判定覆盖
优点:增大代码的覆盖率,提高代码的质量,发现代码中隐藏的问题
缺点:系统庞大时测试开销很大,难以测试所有运行路径;测试基于代码,只能验证代码是否正确,而不晓得代码设计是否合理,可能会遗漏某些功能需求
黑盒测试
概念:不考虑其内部结构,即具体代码实现,检测软件的各个功能能否得以实现,确认软件功能的正确性,依靠软件说明书来判断测试用例,关注具体的客户需求及软件功能。黑盒测试主要是为了发现:1.是否有不正确的或者遗漏的功能;2.输入是否能输出正确的结果;3.性能上是否满足要求
优点:①较为简单,不需要了解程序内部的代码及实现,与软件内部实现无关;②从用户角度出发,实际考虑用户使用的功能及可能出现的问题
缺点:不可能覆盖所有的代码,覆盖率较低
测试用例设计方法:边界值分析法、等价类划分、错误猜测法、因果图法、状态图法、测试大纲法、随机测试法、场景法
等价类
输入域的各子集中,各个输入数据对于揭露程序中的错误都是等效的。
等价类划分:将全部输入数据合理划分成若干个等价类,在每一个等价类中取一个数据作为输入条件,就可以用少量代表性测试数据取得较好的测试结果。分为有效等价类(合理、有意义的输入数据构成的集合)和无效等价类
边界值分析法:大量错误是发生在输入输出范围的边界上,选定测试用例时应该选取正好等于、刚刚大于、刚刚小于边界值的值作为测试数据,而不是选取等价类中的任意值,作为对等价类划分的补充
错误猜测法:基于经验和直觉推测,列举出程序中所有可能有的错误和容易发生错误的特殊情况,根据这些情况选择测试用例
因果图法:考虑输入条件之间的相互组合,也考虑输出结果对输入条件的依赖关系。原因即为输入条件或者输入条件的等价类,结果即为输出条件,把因果转换为决策表,为决策表中的每一列设计测试用例。
场景分析法:根据用户场景来模拟用户的操作步骤
大纲法:着眼于需求。将需求转换为大纲的形式,大纲表示为树状结构,在根和叶子节点之间存在唯一路径,大纲为每条路径定义了一个特殊的输入条件集合,用于测试用例。
随机测试法:不考虑任何用例和需求,完全站在用户的角度对产品进行测试
灰盒测试
关注输入输出的准确性,也关注内部的代码,但是没有白盒测试那么详细完整。
动态测试:
实际运行被测程序,输入相应的测试用例,检查运行结果与预期结果的差异,从而验证程序的正确性、有效性和可靠性,并且分析系统运行的效率和健壮性。
α测试:
一个用户在开发环境下的受控测试,模拟实际操作环境
β测试
多个用户在实际使用环境下进行的测试,如一些软件的公测
冒烟测试
在大规模测试之前,先对软件的基本、核心、主要功能进行测试,节省资源
回归测试
开发修正完代码后再回过头来做测试
随机测试
跳出思维的限制,没有思想、没有步骤地随机进行测试
探索测试
有思想,有步骤地测试一些复杂的、不常用地功能
为什么引入自动化测试
自动化测试是将自动化工具和技术应用于软件测试,旨在减少测试工作,更快,更经济地验证软件质量。有助于以更少的工作量构建质量更好的软件。
许多公司多多少少都在做自动化测试,但手动测试仍然占主要的比例,因为有些团队不知道如何在开发过程中更好的利用自动化测试来替代手动测试。
手工测试通常是工程师仔细的执行预定义的测试用例,将执行结果与预期的行为进行手工比较并记录结果。每次源代码更改时都会重复这些手动测试,由于都是人为参与,这个过程中很容易出错。
在组织中引入自动化测试时,需要投入大量财力和时间。然而,一般没有太多的财务回报,至少在小规模开始时没有。因此许多公司选择开源测试自动化工具,特别是在开始引入自动化测试的阶段。
通常,软件公司害怕投资自动化测试,不是因为负担不起这个投入,而是因为他们担心的回报不会像预期的那样,或者根本不会产生积极的投资回报率。
1. 降低成本(特别是问题出现时的成本)
如前所述,开始自动化测试的初始成本并不高,比如选用免费的开源工具。但是,一旦您的组织全面展开自动化测试,您就会希望投资更好的工具、更好的服务器,雇用人力来维护基础设施等。这些成本绝对不是无关紧要的。
自动化测试不会自动生成。创建有价值的自动化测试需要花费时间和精力,而且不会在一夜之间发生。
如果您想证明引入自动化测试的合理性,不能只关注财务回报,而应考虑应用出现问题导致的隐性成本。例如一个问题在手动测试没有发现而出现在产品环境中,公司会花多少钱?你是否会失去客户?需要花多少时间、资源和资金来纠正这种情况?
如果每次对代码进行更改时,都重复执行一组非常强大的测试套件,可以降低问题出现在产品环境的风险。自动化测试有助于在软件开发生命周期的早期发现错误,从而降低交付故障软件的风险。
说到底,向市场提供高质量的产品重要性远大于任何其他类型的节省。
2. 节省时间
虽然初期建立自动化测试需要花费大量的时间和人力,但是一旦自动化测试建立了,您就可以重用这些测试。自动化测试的执行速度明显快于手动测试,不易出错,且节省人力。
在日常的代码修改过程中,您可以在每次提交时执行自动化测试,而不必通过设置环境或记住执行每个测试的步骤来持续执行手动步骤。一切都是自动完成的。
只要首次设置完成后,就可以重复运行你的自动化测试,从而将重复的手动测试时间从数周缩短至数小时。
同样一旦编写好,测试可以执行任意次。与手动测试仪不同,测试也可全天候,无人值守的执行。
在软件开发团队中,通常的做法是每天多次(通常是每次提交)运行基本单元测试,并且每天在下班后执行耗时的集成测试和UI测试。
3. CI和DevOps
自动化测试构成任何持续集成或DevOps设置的基础。从本质上讲,CI(持续集成)和DevOps都依赖于“Fail fast, Fail early”的理念。对代码库的每次提交都将自动进行测试,并将结果报告给开发人员。开发人员优先修复任何导致构建失败或导致主要测试失败的错误,确保主线代码始终按预期工作。
4. 准确性和可靠性
由于运行每个测试涉及多个先决条件,手动测试容易出错。另外每个测试可能需要不同的执行顺序。
毕竟手动测试人员是人类,人有不善于执行重复枯燥工作的特点,因此可以预料手动测试不会精确并有一定的几率出错。这会导致不准确的结果反馈到开发团队。
自动化测试每次都执行相同的步骤,不仅精确,而且结果可在最短的时间内提供给所有相关人员。
可靠性的另一个方面是在不同服务器上重新执行相同的测试。这使得能够快速验证测试是否在所有服务器上按预期运行,从而排除了服务器配置问题的可能性。
4. 性能测试
性能负载测试可确保您的应用程序可以处理预期和意外的用户负载。
如果您当前只在项目中使用手动测试方法,则负载测试可能会推迟到开发周期结束。按照敏捷方法和持续集成理念,应及早地进行性能测试,但现实是很大一部分项目团队执行做这个测试的时间太晚,最终导致产品发布推迟。
自动化性能测试能够同时运行数千个测试,模拟数百万用户,所有这些用户手动测试几乎都是不可能的。
5. 增加对软件的信心
敏捷方法建议使用sprint,即短周期的迭代。每个sprint通常2-3周。这需要一种新的方式来组织测试工作并要求更高的效率。
每个sprint都专注于开发一组小功能,但必须在其结束的时候提供较完整的新功能特性,还包括之前sprint的所有功能特性。如果没有适当的测试,在不破坏之前正常工作的功能特性的情况下提供全功能系统的风险很高。在每个sprint中反复手动测试所有功能会效率低下。
这也是自动化测试最大的好处。自动化测试并能够在每个sprint中快速重复测试,可以确保所有事情都按预期工作。
6. 衡量质量指标
可用于自动化测试的扩展和工具提供了测量许多代码质量指标的功能,例如代码覆盖率(即实际测试的代码百分比),技术债,代码语义检查等。
通常,当测试作为持续集成或DevOps工作流程的一部分执行时,可同时获取这些方面的测量数据。
之所以能够测量这些指标,是因为自动化测试代码本身与产品代码共存,通过在自动构建阶段解析源代码,能提供在几分钟内测量巨大代码库质量的机会。这在手动测试中根本不可能。
小结
如果您的产品质量是您的首要目标,我强烈建议您使用自动化测试作为日常开发实践的一部分。它将确保您的应用程序得到正确测试,并为研发、管理人员和客户提供信心。
自动化测试需要前期投入,并且需要花时间进行开发。这些投入会得到长期的回报:可以减少工作量,消除手动测试的错误,提高准确性,最终节省成本和时间。
总的来说,自动化测试是一种比手动测试更快获得故障反馈的方法,符合“快速失败,早期失败”的原则。它有助于实现手动测试无法提供的质量。在自动化测试中,
行为驱动的自动化测试
现已广泛为研发团队所接受,基于行为驱动(BDD)的测试脚本具有上手快、易维护、方便所有stakeholders沟通等特点。
如果您还没有一款合适的自动化测试工具来确保软件质量,您可以了解
自动化测试框架包含哪些模块
一个比较成熟的测试框架通常会包含 4 个部分,分别为基础模块,管理模块,统计模块和运行模块。
基础模块
造房子要稳固需要良好的地基。如果把自动化测试框架比作一辆汽车,那么自动化测试基础模块就是那四只轮胎,没有它们,这辆汽车寸步难行,它们一般包括如下部分。
可重用的组件
一般来说用来降低开发成本,常见有日志模块,时间模块等
配置文件
通常会包含测试环境的配置和应用程序的配置。其中测试环境配置用来减少环境版本切换,从开发到上线
管理模块
管理模块就仿佛是车中的内饰,它对测试框架的使用操作体验有着直接的影响,分为测试数据管理和测试文件管理
测试数据管理
测试数据一般是测试用例用到的各种测试数据,他们是为了验证业务正确性而构造,每一组的测试案例通常会对应一对或多对测试数据。测试数据的创建又分为实时创建和事先创建,
实时创建是测试代码运行的时候才生成测试数据。好处是测试数据和测试代码解耦合,测试人员不用关心创建过程和业务调用链,通常用在测试的公用功能上。
事先创建,是指测试代码运行前就准备好的数据文件,其好处是数据拿来即用,几乎不耗费时间,由于没有业务调用,所以这在一定程度上减少了调用失败的风险;坏处则是数据文件本身需要维护,以保持可用性和正确性。
测试文件管理
测试文件管理就仿佛是车子的外观,给人第一印象。一个测试用例通常需要包含三个文件,分别是Page类文件,测试类文件和对象库文件。
这三个文件共同描述一个完整的测试用例。测试文件的结构清晰有助于他人理解测试框架的设计思想
运行模块
运行模块为测试框架的发送机,用于测试用例的组织和运行,通常包含下面几个部分
测试用例调度,驱动机制
错误恢复机制
测试框架应该具有一定的错误恢复机制,测试案例执行过程中,可能出现代码运行错误或环境导致的错误。
持续集成支持
测试框架应该能够和 CI 系统低成本集成,包括通过用户输入参数指定运行环境、测试结束后自动生成测试报告等。
统计模块
统计模块相当于车子的品质和口碑。一个完整的统计模块,可以告诉你当前测试有没有 Bug,还能分析软件质量的变化情况,统计模块一般包含下面几个模块
测试报告
测试报告应该全面,包括测试用例条数统计、测试用例成功/失败百分比、测试用例总执行时间等总体信息。其中,对于单条测试用例,还应该包括测试用例 ID、测试用例运行结果、测试用例运行时间、测试用例所属模块、测试失败时刻系统截图、测试的日志等信息。
日志模块
测试框架应该包括完善的日志文件,方便出错时进行排查和定位。
常用的测试框架类型
有的时候,面试官可能也会用你知道哪些测试框架,测试框架分为这样几种
模块化测试框架
模块化测试框架是利用 OOP 思想和 PO 模式改造而来的框架。
模块化测试框架把整个测试分为多个模块,模块化有以下几个特征:
我们将一个业务或者一个页面成为一个 Page 对象;
这个 Page 对象,我们以一个 Page 类来表示它;
这个 Page 类里存放有所有这个 Page所属的页面对象、元素操作;
页面对象和元素操作组成一个个的测试类方法,供测试用例层调用。
简单来说,使用了 PO 模式的框架就可以叫作模块化测试框架。
模块化测试框架的好处在于方便维护,你的测试用例可以由不同模块的不同对象组成;
坏处在于你需要非常了解你的系统及这些模块是如何划分的,才能在测试脚本里自如地使用,否则你就会陷入重复定义模块对象的循环里。
数据驱动框架
数据驱动框架主要是解决测试数据问题。
在测试中,我们常常需要为同一个测试逻辑,构造不同的测试数据以满足业务需求,这些测试数据可以保存在测试代码里,也可以保存在外部文件里(包括 Excel、File、DB)。
数据驱动框架的精髓在于,输入 M 组数据,框架会自动构造出 M 个测试用例,并在测试结果中把每一个测试用例的运行结果独立展示出来。
在 Python 架构里,最出名的数据驱动框架就是 DDT。
关键字驱动框架
当把一系列代码封装为要给关键字,在测试的过程中,通过组合关键字的方式来生成测试用例,而不关心关键字如何运作的,这种为关键字驱动框架。
混合模型
并不一定要选择上面的三种框架之一,需要根据需求灵活的选择测试框架,在工作中可能经常需要糅合不同的框架模型,这样的模型就叫做混合模型。
测试框架设计原则
首先是清晰明了,学习成本低
其中包含代码规范和模块清晰明确。
通用性强,可维护,可扩展
对错误的处理能力强
错误处理机制,能高效解决。系统日志清晰,方便调试。
运行效率高且功能强大
支持测试环境切换,支持外部数据驱动,支持顺序并发,远程运行,报告完备详尽。
支持版本控制和持续集成
版本控制回溯复盘,持续集成全局出发
如何设计一个不错的测试案例
「好的」测试用例一定是一个完备的集合,它能够覆盖所有等价类以及各种边界值,而跟能否发现缺陷无关。
一个“好的”测试用例,必须具备以下三个特征 。
整体完备性 :「好的」测试用例一定是一个完备的整体,是有效测试用例组成的集合,能够完全覆盖测试需求。
等价类划分的准确性 :指的是对于每个等价类都能保证只要其中一个输入测试通过,其他输入也一定测试通过。
等价类集合的完备性 :需要保证所有可能的边界值和边界条件都已经正确识别。
三种最常用的测试用例设计方法:等价类划分法、边界值分析法、错误推测方法。
第一,等价类划分法
我们只要从每个等价类中任意选取一个值进行测试,就可以用少量具有代表性的测试输入取得较好的测试覆盖结果。现在,我给你看一个具体的例子:学生信息系统中有一个考试成绩的输入项,成绩的取值范围是 0~100 之间的整数,考试成绩及格的分数线是 60。为了测试这个输入项,显然不可能用 0~100 的每一个数去测试。通过需求描述可以知道,输入 0~59 之间的任意整数,以及输入 60~100 之间的任意整数,去验证和揭露输入框的潜在缺陷可以看做是等价的。那么这就可以在 0~59 和 60~100 之间各随机抽取一个整数来进行验证。这样的设计就构成了所谓的“有效等价类”。
你不要觉得进行到这里,已经完成了等价类划分的工作,因为等价类划分方法的另一个关键点是要找出所有「无效等价类」 。显然,如果输入的成绩是负数,或者是大于100的数等都构成了“无效等价类”。
在考虑了无效等价类后,最终设计的测试用例为:
有效等价类1:0~59之间的任意整数;
有效等价类2:59~100之间的任意整数;
无效等价类1:小于0的负数;
无效等价类2:大于100的整数;
无效等价类3:0~100之间的任何浮点数;
无效等价类4:其他任意非数字字符。
第二,边界值分析方法
边界值分析是对等价类划分的补充,你从工程实践经验中可以发现,大量的错误发生在输入输出的边界值上,所以需要对边界值进行重点测试,通常选取正好等于、刚刚大于或刚刚小于边界的值作为测试数据。我们继续看学生信息系统中“考试成绩”的例子,选取的边界值数据应该包括:-1,0,1,59,60,61,99,100,101。
第三,错误推测方法
错误推测方法是指基于对被测试软件系统设计的理解、过往经验以及个人直觉,推测出软件可能存在的缺陷,从而有针对性地设计测试用例的方法。** 这个方法强调的是对被测试软件的需求理解以及设计实现的细节把握,当然还有个人的能力。
错误推测法和目前非常流行的“探索式测试方法”的基本思想和理念是不谋而合的,这类方法在目前的敏捷开发模式下的投入产出比很高,因此被广泛应用。但是,这个方法的缺点也显而易见,那就是难以系统化,并且过度依赖个人能力。
总结:在我看来,深入理解被测软件需求的最好方法是,测试工程师在需求分析和设计阶段就开始介入,因为这个阶段是理解和掌握软件的原始业务需求的最好时机。
计算机基础
计算机基础部分,如果时间紧张,可以直接看计算机网络和数据库的面试总结。如果想要更加精细的去学习相关的内容,可以参考我之前写的那篇2021C++学习路线,其中的计算机基础部分是通用内容。到
Python基础
这里推荐大家看看《python入门到实践》这本书,看完基本上就能使用 Python 了。
我们需要了解什么是 Python,它和 Java/C++有什么不一样,基本数据类型有哪些,Python 控制流(for,while)怎么用。
Python 中 包管理,函数,模块之间的关系等等。当了解了基础知识以后,就可以去看看匿名函数(lambda)如何使用,自省和反射是什么意思,闭包的基本概念,如何实现要给装饰器等等。这里总结了一部分题目,可以参考,如果不明白或不清楚或觉得不对的地方,大家一定要记的去查阅哦。
什么是Python的命名空间?
在Python中,所有的名字都存在于一个空间中,它们在该空间中存在和被操作——这就是命名空间。它就好像一个盒子,每一个变量名字都对应装着一个对象。当查询变量的时候,会从该盒子里面寻找相应的对象。
主(main)函数的作用
作为整个程序文件的入口。
调试代码的时候,在if name__ == ‘__main’中加入一些我们的调试代码,我们可以让外部模块调用的时候不执行我们的调试代码,但是如果我们想排查问题的时候,直接执行该模块文件,调试代码能够正常运行!
cookie和session的关系和区别
由于 HTTP 协议是无状态的协议,所以服务端需要记录用户的状态时,就需要用某种机制来识具体的用户,这个机制就是 Session.典型的场景比如购物车,当你点击下单按钮时,由于 HTTP 协议无状态,所以并不知道是哪个用户操作的,所以服务端要为特定的用户创建了特定的 Session,用于标识这个用户,并且跟踪用户,这样才知道购物车里面有几本书。这个 Session 是保存在服务端的,有一个唯一标识。在服务端保存 Session 的方法很多,内存、数据库、文件都有。集群的时候也要考虑 Session 的转移,在大型的网站,一般会有专门的 Session 服务器集群,用来保存用户会话,这个时候 Session 信息都是放在内存的,使用一些缓存服务比如 Memcached 之类的来放 Session。
思考一下服务端如何识别特定的客户?这个时候 Cookie 就登场了。每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用 Cookie 来实现 Session 跟踪的,第一次创建 Session 的时候,服务端会在HTTP协议中告诉客户端,需要在 Cookie 里面记录一个 Session ID,以后每次请求把这个会话 ID 发送到服务器,我就知道你是谁了。
有人问,如果客户端的浏览器禁用了 Cookie 怎么办?一般这种情况下,会使用一种叫做 URL 重写的技术来进行会话跟踪,即每次 HTTP 交互,URL 后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。
Cookie 其实还可以用在一些方便用户的场景下,设想你某次登陆过一个网站,下次登录的时候不想再次输入账号了,怎么办?这个信息可以写到 Cookie 里面,访问网站的时候,网站页面的脚本可以读取这个信息,就自动帮你把用户名给填了,能够方便一下用户。这也是 Cookie 名称的由来,给用户的一点甜头。
所以,总结一下:
Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;
Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
new 和 init 的区别
new:创建对象时调用,会返回当前对象的一个实例
init:创建完对象后调用,对当前对象的一些实例初始化,无返回值
调用顺序:先调用new__生成一个实例再调用__init方法对实例进行初始化,比如添加属性。
参数传递机制
如果实际参数的数据类型是可变对象(列表、字典),则函数参数的传递方式将采用引用传递方式。如果是不可变的,比如字符串、数值、元组,他们就是按值传递。
迭代器
迭代器是访问集合元素的一种方式,他的对象从集合的第一个元素开始访问,直到所有元素被访问完结束,用iter()创建迭代器,调用next()函数获取对象(迭代只能往前不能后退)。
两者区别:
创建/生成,生成器创建一个函数,用关键字yield生成/返回对象;迭代器用内置函数iter()和next()
生成器中yield语句的数目可以自己在使用时定义,迭代器不能超过对象数目
生成器yield暂停循环时,生成器会保存本地变量的状态;迭代器不会使用局部变量,更节省内存
PYTHONPATH变量是什么
Python中的环境变量,用于在导入模块的时候搜索路径。因此它必须包含Python源库目录以及含有Python源代码的目录。
模块和包
模块:python中包含并有组织的代码片段,xxx.py的xxx就是模块名
包:模块之上的有层次的目录结构,定义了由很多模块或很多子包组成的应用程序执行环境。包是一个包含init.py文件和若干模块文件的文件夹。
库:具有相关功能模块的集合,python有很多标准库、第三方库…
yield
保存当前运行状态(断点),然后暂停执行,即将函数挂起
将yeild关键字后面表达式的值作为返回值返回,此时可以理解为起到了return的作用,当使用next()、send()函数让函数从断点处继续执行,即唤醒函数。
args和*kwargs的含义
不知道向函数传递多少参数时,比如传递一个列表或元组,就使用*args
def func(*args):…
Func(1,2,3,4,5)
不知道该传递多少关键字参数时,使用 **kwargs 来收集关键字参数(keyword argument)
python
def func(**kwargs):…
Func(a=1,b=2,c=3)
Python垃圾回收机制
(自动处理分配回收内存的问题,没用了内存泄漏的隐患),以引用计数机制为主,标记-清楚和分代收集两种机制为辅
计数机制就是 Python 中的每一个对象都有一个引用计数的值,当有引用的时候,这个值会增加,引用他的对象被删除时,这个值减小,引用计数的值为0时,该对象生命结束,Python 会把这段内存自动回收。(缺点,循环引用,如果 l1 和 l2 相互引用,没用其他的对象引用他们,这两段内存永远无法被回收)
Python如何内存管理
引用计数:python内部使用引用计数,来保持追踪内存中的对象,Python内部记录了对象有多少个引用,即引用计数,当对象被创建时就创建了一个引用计数,当对象不再需要时,这个对象的引用计数为0时,它被垃圾回收。
垃圾回收:python会检查引用计数为0的对象,清除其在内存占的空间;循环引用对象则用一个循环垃圾回收器来回收
内存池机制:在Python中,许多时候申请的内存都是小块的内存,这些小块内存在申请后,很快又会被释放,由于这些内存的申请并不是为了创建对象,所以并没有对象一级的内存池机制。这就意味着Python在运行期间会大量地执行 malloc 和 free 的操作,频繁地在用户态和核心态之间进行切换,这将严重影响Python的执行效率。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
Python 提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
Python 中所有小于 256 个字节的对象都使用 pymalloc 实现的分配器,而大的对象则使用系统的 malloc。另外 Python 对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
深拷贝、浅拷贝和等号赋值
深拷贝:新建一个对象,把原来对象的内存完全复制过来,改变复制后的对象,不会改动原来内存的内容。(两个对象在复制之后是完全独立的对象)
等号赋值:相当于为原来的对象打一个新的标签,两个引用指向同一个对象,修改其中的一个,另一个也会产生变化
浅拷贝:两种情况,1. 浅拷贝的值是不可变对象(数值、字符、元组)时,和等于赋值一样,对象的id值和浅拷贝原来的值相同;2. 如果是可变对象(列表、字典等),a. 一个简单的没有嵌套的对象,复制前后的对象相互之间不会影响,b. 对象中有复杂子对象,如列表嵌套,如果改变原来的对象中复杂子对象的值,浅拷贝的值也会受影响,因为在浅拷贝时只复制了子对象的引用(只拷贝父对象)。
Python有什么优势
解释型,语法简单易懂,可读性强
有很多库可以用,可以让我们站在巨人的肩膀上简单的实现想要的功能
可扩展,和其他编程语言或其他软件有可连接的接口
免费开源、可移植
自动内存管理,让程序员可以专注于代码的实现
Python 缺点
他的可解释特征使其运行速度变慢
动态语言的特点可能会增加运行时错误。
面向对象和面向过程的区别
面向对象是把构成问题的事务分解成各个对象,建立对象来描述某个事务在解决问题的步骤中的行为;
面向过程是分析出解决问题所需要的步骤,然后用一些函数把这些步骤一步步实现,使用的时候依次调用函数就行了。
写一个装饰器
import functools
import time
def print_run_time(func):
@functools.wraps(func) def wrapper(*args,**kw):
local_time=time.time()
func(*args,**kw)
t=time.time()-local_time
print(t)
return wrapper
@print_run_time
def test(x):
for i in range(1000):
print(x,end='')
print('\n')
return x
test(1)
python 装饰器@staticmethod和@classmethod区别和使用
@classmethod:类方法,类方法是给类用的,类在使用时会将类本身当做参数传给类方法的第一个参数,python为我们内置了函数classmethod来把类中的函数定义成类方法。
@staticmethod:静态方法
用上面两个装饰器就可以不用在实用类前对类进行实例化了,
@property:将一个实例方法提升为属性,便于访问
Git
如果说功能测试工程师的日常工作是被测试用例文档包围,那么测试工程师则从代码提交说起。
在当前高度协作的今天,测试开发的任务也是各个负责相应的模块,每个模块不同人负责,那么可能就出现下面这些问题
你和别人负责不同的模块,代码都提交后入俄整合
如果你在修改一份公共代码,别人也在修改,如何提交和保存
如果想看人家提交的历史记录,如何回滚
说白了,我们需要一个版本控制系统来跟踪我们的代码,从而更好地解决冲突。
为啥大家都用 Git呢
高效的数据存储方式
和其他的版本控制软件不同的是,Git并不以文件表更列表的方式存储信息,而是采用了快照流的方式对信息进行存储。
在 Git 提交更新的时候,Git会对项目全部文件创建一个快照并保存这个快照的索引。当再次提交,更新的时候,如果存在没有修改的文件,那么 Git 只保留一个链接指向之前存储的文件,而不再重新存储该文件,这样就提高了存储效率。
几乎所有操作在本地执行
在 Git 中,绝大部分的操作访问本地文件和资源都无需联网。
具备数据完整性保障
在 Git 中,任何操作在被操作前都需要使用 SHA-1 散列计算校验来保障数据的完整性。
Git 的工作流程
在 Git 中,项目文件可能处于这样三种形态
已修改:表示修改了文件但还没有保存到数据库
已暂存:表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中
已提交:表示数据已经安全地保存在本地数据库中
Git 项目的三个节点
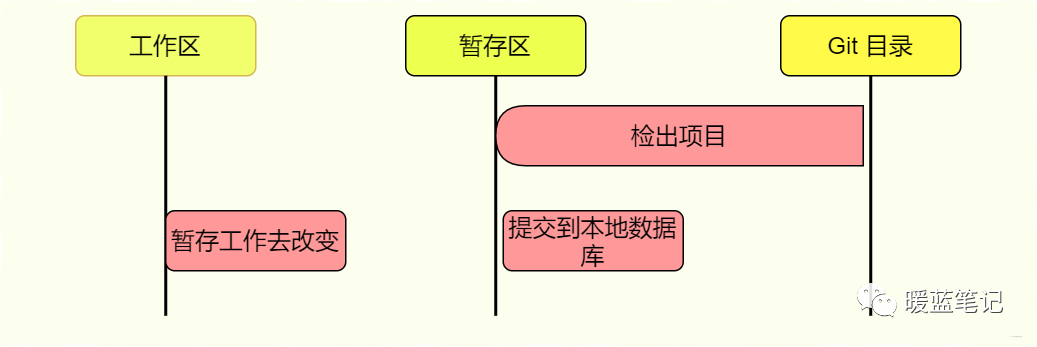
对应上面三种状态,会有三个阶段,为工作区,暂存区和 Git 目录。
工作区
工作区是从 Git 仓库提取出来的数据,也就是我们本地看到的代码目录,这里改动的代码都在已修改状态。
暂存区
暂存区是一个文件,保存了下次将要提交的文件列表信息,一般在 Git 仓库目录中。当处于已修改状态的文件被放入暂存区(Git Add)时,这些文件则会变为已暂存状态。
Git 目录
Git 仓库目录是 Git 用来保存项目的元数据和对象数据库的地方。从其他计算机克隆仓库时,复制的就是这里的数据。当暂存区的文件被提交(Git Commit),则这些文件属于已提交状态。
Git 实践
通过上方的内容了解 Git 以后,最好动手实践一波。
安装 Git
Git 基本设置
流程
在公司中,通常都通过 Github 企业版或 GitLab 进行托管,那么测试开发使用 Git 流程大概如下
通常在本地 Feature 分支进行开发,随后提交测试,本地测试完成则 pull request方式提交代码,测试验证,验证完成后 Github 会根据条件自动出发测试验证流程,代码 Merge,通过后 Merge 到 Master。
如果是新项目,如何初始化 Git 项目呢
首先通过 Git init 初始化项目,此时 Git 仓库为空的,那我们就新建一个文件叫做 lanlan.py,写完以后通过 git add 的方式提交到暂存区。
如果想删除这个文件,那么可以通过 git rm 来删除某个文件。
如果你想要查看当前版本库的状态,可以使用 git status,它将列出文件夹在工作区和暂存区的状态。
如果想要将暂存区的改动提交到本地版本库,那就可使用 git commit -m,这里的 -m 后面一定要记得些提交的注释哟。
如果想要本地的这份代码提交到远程进行协作开发,就需要使用下面的语句
#如下语法用来添加一个远程仓库
$ git remote add [shortname] [url]
#将本地仓库lagouTest和远程仓库建立连接
$ git remote add origin https://github.com/yourCompany/lagouTest.git
既然是团队开发了,那么就先把本地版本代码传到远程库,这样其他的开发人员就可以拉取最新的代码
git push -u origin master
想要获取最新的代码,就需要使用 git clone 拉去最新代码。
可是通常不会在 master 上进行开发,而是需要切换分支,使用 git checkout -b name 的方式切换分支。
使用 Git 的时候,可能遇到哪些问题呢
如何查看提交的历史
如果想要查看某个文件的提交历史,可以使用 git log filename 或 git log lanlan.py 的方式查看
如果本地正在开发,远程的 master 已经更新了,如何更到本地分支
# 假设本地feature分支为newFeature
# 首先需要提交本地分支newFeature的改动至代码仓库
$ git add .
$ git commit -m "本地分支修改comments"
# 然后,执行git merge
$ git merge master
# 最后,再次提交
$ git add .
$ git commit -m "merge master 分支"
提交的时候出现冲突怎么办
当多人更改同一文件的时候就会出现冲突,此时 git 会列举出冲突的内容,可以通过手动的方式保留哪个版本,然后 git add 和 git commit 的方式再次提交
当你正在进行分支开发时,接到一个紧急任务,如何将当前的改动保留和后续恢复?
当你的 feature 分支开发了一半,然后接到了紧急任务需要支持,但是你又不想把功能不完善的代码提交到代码仓库,此时可以使用 git stash 命令。
# 如果你要切换新分支但是有未保存的更改使用git checkout -b会报错。此# 时可以通过git stash将所有未提交的修改(工作区和暂存区)保存至堆栈# # 中,可用于后续恢复.
$ git stash
# 等你想恢复你保存的改动时,执行git stash pop。 它将缓存堆栈中的第一个stash删除,并将对应修改应用到当前的工作目录下。
$ git stash pop
本地提交已提交到暂存区,但是不想要了怎么办?
假设你的某次改动已经提交到暂存区,还没有 push,但是你想丢弃这个改动,可以采用如下办法:
$ git reset --hard HEAD
上线后有问题,代码需要回退怎么办?
$ git revert HEAD
$ git push origin master

Linux
之前那一篇 3w 字的 Linux总结看完就差不多了哦,链接在此,在星球中同样是有 PDF。



Docker
Docker基础部分在之前的文章也给出了,大家可以花时间去学习一波。
Docker容器圈简介

第二趴---Docker基本操作

数据库
数据库计划的是三个部分,第一部分数据库基础之前也完成了,不少小伙伴也打卡学习完了基础部分,下个周会给出数据库索引的面试题,一起加油哦。
操作系统
CICD
持续集成
持续集成(Continuous integration,简称CI),简单来说持续集成就是频繁地(一天多次)将代码集成到主干。
每次集成都通过自动化的构建(包括编译、发布、自动化测试)来验证,从而尽快地发现集成错误。

持续集成强调开发人员提交了新代码之后,立刻进行构建、(单元)测试。根据测试结果,可以确定新代码和原有代码能否正确地集成在一起。
持续集成的好处:
快速发现错误,每完成一点更新,就集成到主干,可以快速发现错误,定位错误也比较容易;
防止分支大幅偏离主干,如果不经常集成,主干又在不断更新,会导致以后集成的难度变大,甚至难以集成。
持续集成的目的
让产品可以快速迭代,同时还能保持高质量。它的核心措施是,代码集成到主干之前,必须通过自动化测试。只要有一个测试用例失败,就不能集成。
持续集成并不能消除 Bug,而是让它们非常容易的发现和改正。
持续集成强调开发人员提交了新代码之后,立刻进行构建、(单元)测试。根据测试结果,我们可以确定新代码和原有代码能否正确地集成在一起。
持续交付
持续交付(Continuous delivery)指的是:频繁地将软件的新版本,交付给质量团队或者用户,以供评审。如果评审通过,代码就进入生产阶段
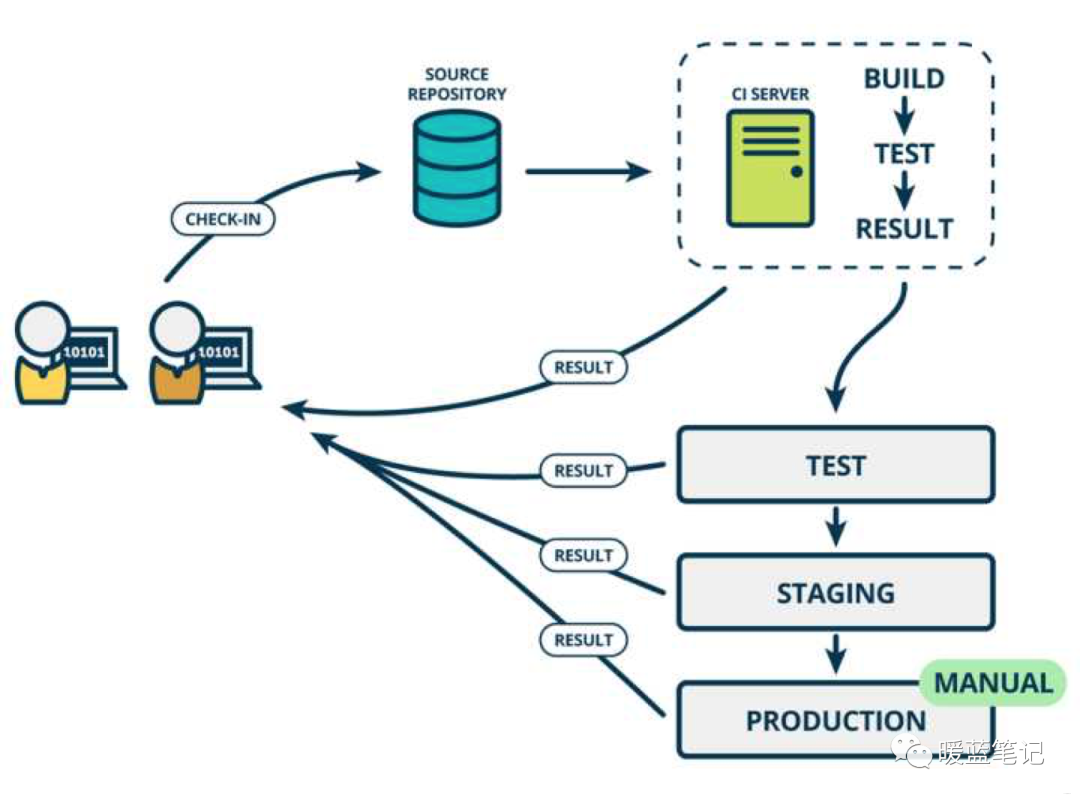
持续交付可以看作持续集成的下一步。它强调的是,不管怎么更新,软件是随时随地可以交付的。
持续部署
持续部署(Continuous deployment)是持续交付的下一步,指的是代码通过评审以后,自动部署到生产环境。

持续部署则是在持续交付的基础上,把部署到生产环境的过程自动化。
持续部署的目标是:代码在任何时候都是可以部署的,可以进入生产阶段,持续部署的前提是能自动化完成测试、构建、部署等步骤。
Selenium面试题
之前给星球的小伙伴修改简历,发现想要面试自动化测试相关的岗位,然而基本上没有这方面的复习准备,项目经验也没有。如果大家需要相关的项目,也可以找我拿罗,我都放在星球了。
什么是Selenium?
Selenium是一个开源的web自动化测试框架,主要是基于web uI的自动化测试。现在的版本,逐步增加了对移动端的自动化测试。Selenium支持多种语言进行开发自动化测试脚本,有Java,python,C#,Javascript等等。Selenium支持跨浏览器平台测试。
Selenium是否支持桌面应用软件的自动化测试。
Selenium不支持桌面软件的自动化测试,Selenium是根据网页元素的属性才定位元素,而其他桌面软件自动化测试工具是根据桌面元素的位置来定位元素,当然现在也有根据桌面元素的属性来定位的。
Selenium是否支持用例的执行的引擎。
引擎好比就是一个发动机。Selenium是没有关于测试用例和测试套件管理和执行的模块。我们需要借助第三方单元测试框架来实现用例管理和用例的执行。例如Java中有Junit或者testNG,Python中有unittest单元测试框架。
Seleinum是否有读取excel文件的库
没有,这里需要用到第三方工具。例如Apache POI插件。
Selenium有哪些组件?
最早的有Selenium IDE,IDE只支持安装在fiefox上一个插件,支持录制自动化脚本。还有
remote RC,和Grid 和webdriver。我们一般最重要的就是使用webdriver。
Selenium有什么限制或者缺陷
除了基于web的软件和mobile的程序,selenium不支持桌面软件自动化测试。软件测试报告,和用例管理只能
依赖第三方插件,例如Junit/TestNG和unittest。由于它是免费的软件,所以没有供应商去提供支持和服务,有问题,只能求助selenium社区。还有一个就是,selenium入门门槛可能有点高,需要具备一定编程语言基础的才能玩转。
在selenium中,有哪些不同定位元素方法
ID/className/Name/LinkText/PartialLinkText/Xpath/CSS selector
什么是imlicitlyWait
imlicitlyWait是隐式等待,一般在查找元素的时候使用。例如,我设置一个查找元素最大时间为10秒,使用了
imlicitlyWait后,如果第一次没有找到元素,会在10秒之内不断循环去找元素,知道超过10秒,报超时错误。
什么是expliciteWait
这个是显式等待,就是不管如何都是要等10秒,如果你设置了10秒超时,这个是selenium2的功能
在selenium3中,我暂时没有找到这个接口。
什么是线程等待
有时候,我们需要强制设置线程等待,Thread.sleep(2000),driver这个实例,就是当前的线程。
什么是pollingEvery
这个是设置个一段时间就去做一件事,例如下面设置隔一秒就去查找元素一次。
WebDriverWait wait = new WebDriverWait(driver,30);
wait.pollingEvery(1, TimeUnit.SECONDS);
driver.findElement(By.xpath("xxxx"));
你能解释下Selenium这个框架吗?
这个问题在面试中被问到的概率还是比较高的,同样类似的问题有,selenium 的原理是什么?首先不要被这个问题吓到,我们主要围绕 selenium 的历史版本演化和基本的组件去展开描述就好,最后回到 webdriver 这个组件上面,我们基本上都是在使用webdriver提供的API。所以这个题目的最好的答案就是把图画出来,然后自己解释几句就可以。早期 Selenium1.0 是有 Selenium Grid,Selenium RC, Selenium IDE, Webdriver 四部分组成,后来 Selenium RC 和 Webdriver 合并之后,就是 Selenium2,当前我们在使用 Selenium3。
Selenium Grid:它是selenium框架的一部分,主要是专门用来把测试用例并行地在不同浏览器,不同操作系统,不同机器上运行。一般我们写脚本,调试都在单机上线性地一个测试用例接着一个测试用例执行下去。如果有人问题如何提高测试用例执行效率,告诉他Selenium Grid可以实现。Selenium IDE: 这个算Selenium里面最简单的一个组建,只支持在火狐浏览器上安装这个扩展程序,支持录制web ui脚本,然后导出不同语言的脚本,例如java c#等。这个功能算鸡肋,因为很多时候导出脚本debug的时间还不如自己代码重新写来的快。
Selenium RC: RC是remote control的缩写,主要的功能就是让你不管使用什么语言(Selenium支持的这几种语言之一)来写测试脚本,只要是这个浏览器支持java script,那么写一遍测试脚本,都能在这些不同浏览器运行脚本。
Webdriver:这个是用来替代Selenium RC,就是一个网页自动化工具,支持在不同浏览器上运行测试脚本,运行速度比Selenium RC要快很多。据说(我也记得不清楚),webdriver最早是google内部开发的一个工具,用来捐给selenium了,变成开源了。
目前,我们做的 web ui 的自动化测试,大部分都是在使用 webdriver 提供的 API来模拟手动测试过程中的一系列动作和行为。基本上通过这个方式来回答这个问题,那就没问题了。
你写的测试脚本能在不同浏览器上运行吗,支持跨浏览器平台吗
这里出现了跨浏览器平台的概念,就是写一个测试用例,可以在主流的几个浏览器跑起来。
是的,我写的测试用例能在IE,火狐和谷歌这三种浏览器上运行。主要是在windows平台上运行脚本,所以mac的safari浏览器暂时没有写过。主要实现这个跨浏览器的思想就是,把浏览器类型写到配置文件,代码里写if语句去判断配置文件的浏览器的类型,来决定用什么浏览器去执行测试用例。
什么是POM,为什么要使用它
POM 是 Page Object Model 的简称,它是一种设计思想,而不是框架。大概的意思是,把一个一个页面,当做一个对象,页面的元素和元素之间操作方法就是页面对象的属性和行为,所以自然而然就用了类的思想来组织我们的页面。一般一个页面写一个类文件,这个类文件包含该页面的元素定位和业务操作方法。
为了我们测试用例写的简单,清晰,我们很多时候在页面对象会封装很多业务操作方法,测试脚本只需要调用相关方法就可以。
还有一个可能和这个问题相关的面试题,如果页面元素经常发生需求变化,你是如何做,答案就是采用 POM 思想。好处就是只要该一个页面,我就去修改这个页面对象的元素定位和相关方法,脚本不需要修改。
在你做自动化过程中,遇到了什么问题吗?举例下
这个问题,不管是自动化还是任何工作,都会被问到。主要想知道你是如何解决问题的,从而推断你问题分析和解决的能力。
当然有遇到问题和挑战,主要有以下几点:
频繁地变更UI,经常要修改页面对象里面代码,运行用例报错和处理,例如元素不可见,元素找不到这样异常,测试脚本复用,尽可能多代码复用,一些新框架产生的页面元素定位问题,例如ck编辑器,动态表格等,这个遇到的难点完全取决写脚本人的代码能力。回答三个左右就差不多,记得既然抛出了难点问题,一定要记得处理这个问题的方法。
举例一下你遇到过那些异常,在selenium自动化测试过程中
通过这个问题,大概知道你写过多少脚本。写脚本过程最常见的异常就是,这个元素无法找到。常见的selenium有以下这些:
ElementNotSelectableException :元素不能选择异常
ElementNotVisibleException :元素不可见异常
NoSuchAttributeException :没有这样属性异常
NoSuchElementException:没有该元素异常
NoSuchFrameException :没有该frame异常
TimeoutException :超时异常
Element not visible at this point :在当前点元素不可见
如何处理 alert 弹窗
我们常见的alert弹窗有两种:基于windows弹窗和基于web页面弹窗
我们知道,webdriver是能够处理alert弹窗的,Selenium提供了Alert这个接口。相关操作代码如下:
// 切换到Alert
Alert alert = driver.switchTo().alert();
// 点击弹窗上确定按钮
alert.accept();
// 点击弹窗的取消按钮
alert.dismiss()
// 获取弹窗上线上的文本文字内容
alert.getText();
// 有些弹窗还支持文本输入,这个可以把要输入字符通过sendkeys方法输入
alert.sendkeys();
在selenium中如何处理多窗口?
这个多窗口之间跳转处理,在实际selenium自动化测试经常遇到。就是,你点击一个链接,这个链接会在一个新的tab打开,然后你接下来要查找元素在新tab打开的页面,所以这里需要用到swithTo方法。
需要获取当前浏览器多窗口句柄,然后根据判断跳转新句柄还是旧句柄
你查找元素遇到过在Frame里面吗?你是如何处理Frame里面元素定位的?
有时候我们知道元素定位表达式没有问题,但是还是提示 no such element,那么我们就需要考虑这个元素是否在frame中。如果在,我们就需要从 topwindow,通过 swithcTo.Frame() 方法来切换到目标 frame 中,可以通过 frame 的 name 和 id和索引三种方法来定位 frame。
怎么验证勾选框是enable/disabled/ checked/Unchecked/ displayed/ not displayed?
通过以下方法来验证元素是enable 还是disable
boolean enabled = driver.findElement(By.xpath("元素定位表达式")).isEnabled();
通过以下方法来验证元素是select/check
boolean checked = driver.findElement(By.xpath("元素定位表达式")).isSelected();
通过以下方法来验证元素是dispalyed还是not display
boolean displayed = driver.findElement(By.xpath("元素定位表达式")).isDisplayed();
关闭浏览器中quit和close的区别
简单来说,两个都可以实现退出浏览器session功能,close是关闭你当前聚焦的tab页面,而quit是关闭全部浏览器tab页面,并退出浏览器session。知道这两个区别,我们就知道quit一般用在结束测试之前的操作,close用在执行用例过程中关闭某一个页面的操作。
什么是页面加载超时
Selenium中有一个 Page Load wait的方法,有时候,我们执行脚本的速度太快,但是网页程序还有一部分页面没有完全加载出来,就会遇到元素不可见或者元素找不到的异常。为了解决问题,让脚本流畅的运行,我们可以通过设置页面加载超时时间。具体代码是这个:
driver.manage().timeouts().pageLoadTimeout(10,TimeUnit.SECONDS);
这行作用就是,如果页面加载超过10秒还没有完成,就抛出页面加载超时的异常。
在Selenium中如何实现截图,如何实现用例执行失败才截图
在Selenium中提供了一个TakeScreenShot这么一个接口,这个接口提供了一个getScreenshotAs()方法可以实现全屏截图。然后我们通过java中的FileUtils来实现把这个截图拷贝到保存截图的路径。
代码举例:
File src=((TakesScreenshot)driver).getScreenshotAs(OutputType.FILE);
try {
// 拷贝到我们实际保存图片的路径
FileUtils.copyFile(src,new File("C:/selenium/error.png"));
}catch (IOException e)
{
System.out.println(e.getMessage());
}
如果要实现执行用例发现失败就自动截图,那么我们需要把这个截图方法进行封装。然后在测试代码中的catch代码块去调用这个截图方法。这个我们在POM的框架中一般是把截图方法封装到BasePage这个文件中。
在Selenium中如何实现拖拽滚动条?
在Selenium中通过元素定位会自动帮你拖拽到对应位置,所以是没有自带的scoll方法。但是这个是有限制,例如当前页面高度太长,默认是页上半部分,你定位的元素在页尾,这个时候可能就会报元素不可见的异常。我们就需要利用javaScript来实现拖拽页面滚动条。
我们一般可以两个方法去拖拽,一个是根据拖拽的坐标(像素单位),另外一个是根据拖拽到一个参考元素附件。
如何实现文件上传?
我们在 web 页面实现文件上传过程中,可以直接把文件在磁盘完整路径,通过sendKeys 方法实现上传。如果这种方法不能实现上传,我们就可能需要借助第三方工具,我用过一个第三方工具叫 autoIT.
你是如何管理你的测试用例并执行?
写用例和管理并执行用例,我们都需要借助单元测试框架来实现,如果是Java语言一般有junit和TestNG,如果是python,常见的有unittest。
就你实际情况,说一下。例如我使用TestNG比较多,需要配置testng.xml文件来实现测试用例的执行。有时候需要配置多个testng.xml去实现不同的任务场景。再展开,可能问你一下testng框架的知识点。例如,方法依赖,用例执行优先级,数据源驱动等。
关于自动化测试报告生成?
我个人一般用TestNG原生的测试报告,也有第三方叫reportNG的插件,不过我没有实际使用过。
Python下报告生成一般使用HTMLTestRunner.py
哪些自动化测试工具
Appium
官网:Appium
AppUI自动化测试
Appium 是一个移动端自动化测试开源工具,支持iOS 和Android 平台,支持Python、Java 等语言,即同一套Java Python 脚本可以同时运行在iOS 和Android平台,Appium 是一个C/S 架构, 核心是一个 Web 服务器,它提供了一套 REST 的接口。当收到[客户端]()的连接后,就会监听到命令,然后在移动设备上执行这些命令,最后将执行结果放在 HTTP 响应中返还给[客户端]()。
License:免费
Selenium
官网:Selenium
WebUI自动化测试
Selenium是一个用于Web应用程序测试的工具,Selenium已经成为 Web 自动化测试工程师能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的一个验收测试工具。其升级版本为Webdriver。
License:免费
Postman
官网:Postman
接口测试
Postman 提供功能强大的 Web API 和 HTTP 请求的调试,它能够发送任何类型的HTTP 请求 (GET, POST, PUT, DELETE…),并且能附带任何数量的参数和 Headers。不仅如此,它还提供测试数据和环境配置数据的导入导出,付费的 Post Cloud 用户还能够创建自己的 Team Library 用来团队协作式的测试,并能够将自己的测试收藏夹和用例数据分享给团队。
License:免费
Jmeter
官网:Jmeter
接口测试,性能测试
JMeter是Apache组织的开放源代码[项目](),它是功能和性能测试的工具,100%的用java实现;
JMeter可以用于测试静态或者动态资源的性能(文件、Servlets、Perl脚本、java对象、数据库和查询、ftp服务器或者其他的资源)。JMeter用于模拟在服务器、网络或者其他对象上附加高负载以测试他们提供服务的受压能力,或者分析他们提供的服务在不同负载条件下的总性能情况。你可以用JMeter提供的图形化界面分析性能指标或者在高负载情况下测试服务器/脚本/对象的行为。
使用Jmeter做接口测试需要注意一点,小心使用“用户定义变量”,Jmeter组件有优先级的,如果多个线程同时执行的时候,“用户定义变量”组件定义的变量可能会乱套。
License:免费
Loadrunner
官网:Loadrunner
性能测试
LoadRunner,是一种预测系统行为和性能的负载测试工具。通过以模拟上千万用户实施并发负载及实时性能监测的方式来确认和查找问题,LoadRunner能够对整个企业架构进行测试。企业使用LoadRunner能最大限度地缩短测试时间,优化性能和加速应用系统的发布周期。LoadRunner可适用于各种体系架构的自动负载测试,能预测系统行为并评估系统性能。
License:商业
Jenkins
官网:https://jenkins.io
持续集成
自动化构建 编译,部署,任务执行,测试报告,邮件通知等。
License:免费
智力题
Q:跳台阶问题
Q:4分钟沙漏和7分钟沙漏怎么漏出9分钟
Q:两个粗细不同的香,燃尽时间都是1个小时,怎么用这个2根香计算15分钟的时间
Q:赛马
Q:10堆苹果,每堆10个,9堆每个50g,1堆每个40g,有一个称,求只称一次,找出这个轻的一堆
Q:飞机加油问题
Q:逻辑:四个开关四个灯泡
Q:地球弧形
测试面试真题
登陆测试
以用户登录为例,一般的小白可能只能够想到一些功能性测试(如下)。
现在,针对“用户登录”功能,基于等价类划分和边界值分析方法,我们设计的测试用例包括:
输入已注册的用户名和正确的密码,验证是否登录成功;
输入已注册的用户名和不正确的密码,验证是否登录失败,并且提示信息正确;
输入未注册的用户名和任意密码,验证是否登录失败,并且提示信息正确;
用户名和密码两者都为空,验证是否登录失败,并且提示信息正确;
用户名和密码两者之一为空,验证是否登录失败,并且提示信息正确;
如果登录功能启用了验证码功能,在用户名和密码正确的前提下,输入正确的验证码,验证是否登录成功;
如果登录功能启用了验证码功能,在用户名和密码正确的前提下,输入错误的验证码,验证是否登录失败,并且提示信息正确。
乍一看,感觉测试案例已经够多了,不过对于一个稍微有点经验的工程师,可能会加上下面部分
用户名和密码是否大小写敏感;
页面上的密码框是否加密显示;
后台系统创建的用户第一次登录成功时,是否提示修改密码;
忘记用户名和忘记密码的功能是否可用;
[前端]()页面是否根据设计要求限制用户名和密码长度;
如果登录功能需要验证码,点击验证码图片是否可以更换验证码,更换后的验证码是否可用;
刷新页面是否会刷新验证码;
如果验证码具有时效性,需要分别验证时效内和时效外验证码的有效性;
用户登录成功但是会话超时后,继续操作是否会重定向到用户登录界面;
不同级别的用户,比如管理员用户和普通用户,登录系统后的权限是否正确;
页面默认焦点是否定位在用户名的输入框中;
快捷键Tab 和Enter等,是否可以正常使用。
上述还仅仅只是功能测试,你还可以从其他的角度比如安全性、性能以及兼容性三大方面。在上面所有的测试用例设计中,我们完全没有考虑对非功能性需求的测试,但这些往往是决定软件质量的关键因素。>
安全性测试用例包括
用户密码后台存储是否加密;
用户密码在网络传输过程中是否加密;
密码是否具有有效期,密码有效期到期后,是否提示需要修改密码;
不登录的情况下,在浏览器中直接输入登录后的URL地址,验证是否会重新定向到用户登录界面;
密码输入框是否不支持复制和粘贴;
密码输入框内输入的密码是否都可以在页面[源码]()模式下被查看;
用户名和密码的输入框中分别输入典型的“SQL注入攻击”字符串,验证系统的返回页面;
用户名和密码的输入框中分别输入典型的“XSS跨站脚本攻击”字符串,验证系统行为是否被篡改;
连续多次登录失败情况下,系统是否会阻止后续的尝试以应对暴力破解;
同一用户在同一终端的多种浏览器上登录,验证登录功能的互斥性是否符合设计预期;
同一用户先后在多台终端的浏览器上登录,验证登录是否具有互斥性。
性能压力测试用例包括:
单用户登录的响应时间是否小于3秒;
单用户登录时,后台请求数量是否过多;
高并发场景下用户登录的响应时间是否小于5秒;
高并发场景下服务端的监控指标是否符合预期;
高集合点并发场景下,是否存在资源死锁和不合理的资源等待;
长时间大量用户连续登录和登出,服务器端是否存在内存泄漏。
兼容性测试用例包括:
不同浏览器下,验证登录页面的显示以及功能正确性;
相同浏览器的不同版本下,验证登录页面的显示以及功能正确性;
不同移动设备终端的不同浏览器下,验证登录页面的显示以及功能正确性;
不同分辨率的界面下,验证登录页面的显示以及功能正确性。
微信红包测试
单个红包:
红包金额为空、0、0.01、200.00、200.01、199.99、200
留言输入数字、字母、汉字、特殊字符
留言长度
留言复制粘贴
表情选择收藏表情、其他表情
删除表情、重新选择表情
选择支付方式 零钱、银行卡、添加新卡支付。其中钱数<红包钱数、其中钱数=红包钱数、其中钱数>红包钱数
使用指纹确认付款(正确的、错误的指纹)
使用密码确认付款(正确的、错误的密码)
红包成功发送后 相应支付方式中钱数减少(减少金额与红包金额一致)
接受者能看到红包具体信息,红包金额、留言、表情均能正确显示
红包被拆开后显示已领取,领取者零钱中增加正确金额,再次领取只能查看红包信息
发红包者自己领红包
红包24小时未被领取提示红包被退回,相应支付方式中钱数增加(增加金额与红包金额一致),对方不能领红包
群发红包-普通红包:(只写了与单个红包不同的地方)
红包个数 为空、0、001、100、99、101
红包拆开每个金额一样 均为发红包时设置的单个金额对应的钱数
红包被拆时,有相应提示
发红包者自己领红包
红包24小时内未被拆完,剩余钱被退回,相应支付方式中钱数增加
群发红包-拼手气红包:
红包每个人拆开金额不同,总金额与发红包设置的总额一致
红包24小时内拆完后显示最佳手气
红包24小时内未被拆完不显示最佳手气
兼容性测试
兼容性: 安卓、苹果 不同型号版本手机
UI测试: 界面无错别字,风格统一
中断测试: 不同应用之间切换、断网、来电、短信、低电量、手机没电
网络测试: 2g/3g/4g WiFi 移动联通电信 弱网 无网
微信朋友圈测试用例
朋友圈发送功能
只发送文本
a、考虑文本长度:1-1500字符(该数据为[百度]()数据)、超出最大字符长度
b、文本是否支持复制粘贴
c、为空验证
只发送图片
a、本地相册选择/拍摄
b、图片数量验证:1-9张图片、超出9张
c、为空验证
只发送视频
a、本地相册选择/拍摄
b、视频秒数验证:1-10s,超出10s
c、视频个数验证:1个,超出1个
d、视频格式验证:支持的视频格式,例mp4、不支持的视频格式
e、视频大小验证:苹果400kb以内、Android200-300kb(此为[百度]()数据)、超出规定大小
f、视频预览增删改操作
g、为空验证
发送文本+图片:输入满足要求的文本、图片进行一次验证
发送图片+视频:不支持发送
朋友圈发送内容是否有限制,例如涉及黄赌毒等敏感字
所在位置
a、不显示位置:发送到朋友圈动态不显示位置
b、选择对应位置:搜索支持、自动定位、手动编辑
C、点击取消,返回上一级页面
谁可以看
a、设置公开:所有朋友可见
b、设置私密(仅自己可见):自己查看朋友圈-可见、好友查看朋友圈-不可见
c、设置部分可见(部分朋友可见):选择的部分好友-可见、不被选择的好友-不可见、是否有人数上限
d、设置不给谁看(选中的朋友不可见):不被选中的朋友-可见、被选中的朋友-不可见、是否有人数上限
e、点击取消,返回发送页面
提醒谁看
a、提醒单人/提醒多人:被提醒的朋友-收到消息提醒、未被提醒-未有消息提醒
b、是否有人数上限
c、点击取消,返回发送页面
同步QQ空间:默认不同步、同步到QQ空间
取消发送朋友圈操作
a、选择相机,点击取消,返回朋友圈页面
b、进入朋友圈发送页面,选择文本图片,点击取消
13)朋友圈当天发送次数是否有上限限制
朋友圈浏览功能
文本查看:
a、过长文本内容是否隐藏,并支持查看全文
b、右键选择复制、收藏、翻译
c、url链接是否支持点击跳转网页
图片查看
a、小图右键支持收藏/编辑
b、点击支持大图浏览
c、选择发送给朋友、收藏、保存图片、编辑
d、多张图片支持左右滑动浏览
视频查看
a、右键视频支持静音播放/搜藏
b、点击视频播放按键支持播放视频
c、选择发送给朋友、收藏、保存视频、编辑
分享动态浏览:QQ空间/公众号文章/非[腾讯]()产品分享后朋友圈是否正常显示
赞:点赞、取消点赞
评论
a、评论长度:评论字数合理长度、评论超过字数上限
b、评论类型:纯中文、纯数字、纯字母、纯字符、纯表情(微信表情/手机自带表情)、混合类型、包含url链接;
c、评论是否支持复制粘贴
d、为空验证
e、发表评论后删除
f、评论回复操作
删除朋友圈动态
更换相册封面
刷新是否正常获取新动态
上滑是否加载更多
界面/易用性测试
1、技术人员角度:页面布局设计是否跟产品原型图/ui效果图一致
2、但除了考虑1之外,我们同样要考虑到用户使用:功能操作是否简便,页面布局排版风格是否美观合理,提示语相关信息是否易于理解
中断测试
1、主要考虑:a)核心功能 b)当前功能存在实时数据交换,例发朋友圈、浏览朋友圈进行中断,是否容易出现崩溃
2、中断包括:前后台切换、锁屏解锁、断网重连、app切换、来电话/来短信中断、插拔耳机线/数据线
网络测试
1、三大运营商不同网络制式测试
2、网络切换测试:WIFI/4G/3G/2G
3、无网测试:对于缓存在本地的数据,部分朋友圈信息是否支持浏览
4、弱网测试:
a、延时:页面响应时间是否可接受、不同网络制式是否区分超时时长、出现请求超时,是否给予相应的提示
b、丢包:有无超时重连机制、如果未响应,是否给予相应提示
c、页面呈现的完整性验证
兼容性测试
1、Android手机端、苹果手机端、pad版(主流)功能界面显示是否正常
2、各平台朋友圈展示数据是否一致
安全测试
发送朋友圈时,文本输入脚本代码,是否出现异常
性能测试
1、服务器性能测试
可通过loadrunner/jmeter工具实现,主要关注TPS、响应时间、吞吐量、CPU、内存等
2、app客户端性能测试
可通过GT工具实现,运行时关注cpu、内存、流量、电量等占用率
3、app压力稳定性测试
通过monkey工具实现,频繁发送朋友圈,浏览朋友圈请求,是否容易发生崩溃
测试一个输入框(计数)
相信不少朋友在笔试的时候都遇到过测试用例设计的笔试题。通常是一个登陆页面,上面有用户名,密码的输入框,再多一点的有个验证码。
不过要是你见到的是以下的这道测试用例设计笔试题,不用问,面试官一定是看过《Google软件测试之道》的。(也脑补一下,万一面试官是看过CC先生的简书呢…… 嗯嗯,梦想还是要有的)
出题时间:
在一个Web测试页面上,有一个输入框,一个计数器(count)按钮,用于计算一个文本字符串中字母a出现的个数。这里的问题是,请设计一系列测试用例用以测试这个Web页面。
很多朋友可能拿到这道题的时候已经开始写下1.2.3.了,不过根据经验上来说,追求数量而非质量的倾向,是一种低效的工作方式。(特别在有面试官在旁边看到你答题的时候,请保持沉思者状保持10-15秒)
能够针对题目提出一些问题来的候选者会被认为更有潜质来做测试人员,比如大写还是小写?只是英语吗?计算完成后文本会被清除吗?多次按下按钮会发生什么事情?诸如此类。
通常说来,我们考虑一个测试对象的时候至少从以下六方面来考虑。
功能性
易用性
可靠性
性能
安全
兼容性
如果你是一个测试菜鸟,从功能性出发,你可能会列出以下一个典型的列表:
“banana”:3(一个合法的英文字)。
“A” 和“a”:1(一个简单有正常结果的合法输入)。
“”:0(一个简单的结果为0的合法输入)。
Null:0(简单的错误输入)。
“AA” 和“aa”:2(个数大于1并且所有字符都为a/A的输入)。
“b”:0(一个简单的非空合法输入,结果为0)。
“aba”:2(目标字符出现在开头和结尾,以寻找循环边界错误)。
“bab”:1(目标字符出现在中间)。
space/tabs:N(空白字符与N个a的混合)。
不包含a的长字符串:N(N大于0)。
包含a的长字符串:N(N是a的倍数,试试龙妈的名字)。
{java/C/HTML/[JavaScript]()}:N是a出现的个数(可执行字符,或错误,或代码解释)。
更优秀的测试工程师,会开始考虑后面五个方面,设计以下用例。
质疑界面的外观、调色板和对比度(这与相关应用风格一致么?)
文本框太小了,建议加长以便显示更长的输入字符串
这个应用能否在同一台服务器上运行多个实例,多个用户同时使用是否会有问题。
是否会根据用户的输入自动匹配内容?
建议使用真实的数据,如从词典或书中选择输入内容。
提出疑问:“输入的数据是否会被保存”,输入字符串可能包含地址或其他身份信息。
输入HTML和JavaScrip,看是否会破坏页面渲染。
尝试复制/粘贴字符串。
提出疑问:“计算足够快么?在大并发下使用”。
提出疑问:“用户怎么找到该页面?”
提出疑问:“有快捷键的设置么?比如输完字符后敲入回车键而不是点击提交按钮”
还有一些测试点,只有经验丰富的测试工程师才会想到。
意识到计算会通过URL-encodedHTTP GET请求传递到服务器,字符串可能会在网络传输时被截断,因此,无法保证支持多长的URL。
建议将此功能参数化,为什么只对字母a计算呢?
考虑计算其它语言中的a(α,Alpha)。
考虑到该应用是否应该国际化。
考虑到输入法全角输入和半角输入是否相同。
考虑编写脚本或者手工采样来探知字符串长度的上限,然后确保在此区间内功能正常。
考虑背后的实现和代码。也许已经有一个计数器遍历该字符串。
提出疑问:“HTTP POST方法和参数会被黑掉码?也许有安全漏洞?”
用脚本创建各种有趣的排列组合和字符串特性,如长度、a的个数等,自动生成测试输入和验证。
测试百度搜索
我们可以从以下几个角度进行测试。
功能测试:
输入搜索信息,点击搜索按钮是否能获取搜索结果,跳到结果界面; 搜索结果界面弹出的信息是不是符合我输入的信息 , 没有输入信息,按搜索看会有什么结果 ,对输入框能输入的最大字符数进行边界测试,(假设限制是30个字符),那么分别输入20,30,31个字符的文本进行测试,测试超出输入限制会出现的结果
测试输入敏感词时的搜索结果,输入不同国家语言的搜索结果 ,查询不到搜索结果的情况显示的结果,从搜索结果界面返回的按钮能不能正常返回
点击[百度]()的标签能不能跳到相关的热搜界面
测试[百度]()的图片搜索能不能正常使用
图片拖曳和上传的功能是否均能实现,粘贴图片网址能不能用
如果粘贴的图片网址不存在是否能给出正确的提示反馈
输入特别大的图会发生什么现象
性能测试:
测试搜索时的响应时间能否符合需求
网速慢的条件下还能不能正常搜索
多用户同时访问,或者一个时间点访问量突然增大的情况,对这些特殊情况进行模拟,测试还能不能进行正常搜索
易用性测试:
使用操作是否简单,是不是输入查询信息之后点击搜索按钮就行了;
在输入框输入搜索词的过程中下拉框能否弹出相关的[联想]()搜索(你可能要搜)
输入框有没有保存最近搜索的信息的记录
除了点击搜索按钮进行搜索,测试按回车进行检索的功能
兼容性测试:
多种系统下的多种不同的浏览器下是否能正常显示、正常使用;
在不同的手机浏览器中打开是否能正常显示、正常使用;
各种语言平台下是否都能正常使用
安全性测试:
能不能防止搜索时对数据库的恶意攻击的情况,如SQL注入
UI
界面设计是否简介,是否符合用户审美
图标能不能正常显示,界面有无错别字
BUG描述、评级
对bug的描述尽量简短但要求清晰,对bug出现的条件进行详细的描述,包括输入的测试用例、使用的环境、有没有和其他软件同时运行,以及需要写清bug出现的位置,帮助开发更好定位。
按照用户体验(bug是否很严重的影响用户体验)、影响系统的程度进行评级
一条bug记录的组成
bug内容
bug发现时间
测试条件(系统配置信息、环境、软件版本、浏览器版本…)
预期结果和实际结果的对比,相关的分析
如何重现这个bug的步骤
这个bug的严重性(会多大程度的影响系统或用户使用)
bug发生的位置
QPS和TPS的区别
TPS:Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。TPS包括一条消息入和一条消息出,加上一次用户数据库访问。
QPS:每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准
用来衡量服务器的机器性能。
是软件测试结果的测量单位。
并发用户数和在线用户数的区别
在线用户数:用户同时在一定时间段的在线数量
并发用户数:某一时刻同时向服务器发送请求的用户数
(在线用户只要在线就好了,并发用户计算的是和服务器有交流的用户,一般比例5%-20%)
试的阶段
测试应该尽早进行。越早就可以花越少的消耗得到越大的回报。
书籍
《测试工程师全栈技术进阶与实践》 茹炳晟
《Google测试之道》
测开高频手撕代码
测试开发岗面试时对代码能力要求不太高,刷熟剑指offer就可以大胆地去面试啦~
下面是我总结的百度美团京东等大厂常见的代码题
1.将一个只含有-1和1的乱序数组变成-1全在1前面的数组
2.合并区间
3.最小覆盖子串
4.最长不含重复字符的字符串
5.翻转单词顺序
6.判断回文串
7.两数之和
8.最长回文子串
9.和为K的子数组
10.合并两个有序数组
11.合并两个有序链表
12.判断链表有环、环的位置、环的长度
13.翻转链表
14.奇偶链表
15.合并n个有序链表
16.去除驼峰字符串
17.统计一个数字在排序数组中的出现次数
18.输入YYYY-MM-DAY 判断是当年的第多少天
19.括号匹配
20.判断是否为合法字符
21,冒泡排序归并排序 快速排序
22.最长连续数列
23.给出数组的所有子集
24.两个栈实现一个队列
25.寻找数组中前三大的值
26.两个排序数组找到相同元素
HR常问
为什么想做测试
对测开的理解
测试过程中有没有出现问题,是如何解决的
最近看了什么书?学了什么?为什么学?有看什么技术书籍吗?
个人优缺点,举例
测试看重什么能力
项目问题细挖
为什么选择xx公司?
你对我们公司有什么了解吗?
之前实习收获了什么
介绍下自己的优缺点
抗压能力如何,描述一件自己如何抗压的经历
反问环节:你有什么问题想问我么?
项目中收获了什么?
平时怎么学习的
为什么要离职?
你的期望薪资是多少?
如果在测试中发现一个 Bug ,但是开发经理不认为这是一个 Bug ,应该怎么解决?
产生这种有争议的 Bug 的几个原因有
首先可能是测试人员自己的问题,是否描述该bug不太清晰,使得开发人员难以理解或者产生了歧义,这个时候要修改自己的描述,一定要清晰明了,无歧义,无冗余的步骤
其次可能是需求型的bug,找产品经理沟通清楚该产品的需求,判断是测试人员还是开发人员对该需求判断有误
还有可能是低概率性的 Bug ,出现了难以复现的 Bug ,这个时候要结合严重性、频繁性、对用户的影响以及产品交付时间与开发共同衡量是否修复该 Bug ,即使是选择暂不修复,也需要将该 Bug 详细地提交备案
为什么想要做测试?
你觉得你做测试的优势在哪里?
怎么看待测试中重复性工作较多的问题
谈谈你对测试的理解
你的职业规划
如何理解测试和测试开发?
测试就是在规定条件下检测产品功能或者程序上的错误,对其是否满足设计要求进行评估。
测试开发需要开发一些自动化测试的平台或者二次开发一些现有的开源工具,最终目的是提升测试效率,但是核心职能仍然是测试。
如果遇到一些低概率性的 Bug 会怎么办?
首先要认真记录引发该 Bug 的情况(当时的测试环境、测试数据、出现问题前的操作),不应该在测试报告中因为出现概率低而忽略这些 Bug 的存在
其次,会根据严重性、频繁性、对用户的影响这三个因素共同做决定,严重性就是判断该bug是否导致严重的后果,比如是不是会让整个程序崩溃?会导致用户信息丢失吗?还是仅仅是无关痛痒的小问题?;频繁性就是指在用户使用的过程中是否会经常碰到该类问题?还是这个 Bug 出现在某些不太常用的功能中;对用户的影响是指是否会影响到全部用户的使用?还是只影响部分用户的使用?(比如说这个 Bug 所在的程序如果只出现在app的旧版本中,那么它对用户的影响就很小)
综合上面几点联合考虑,然后视产品发布日期来决定,如果产品发布日期临近,修改一些不太严重、出现不太频繁的 Bug 反而可能得不偿失,带来其他的风险,因此此时仅仅将该 Bug 备案,其他情况下还是需要尽力定位、修复该bug。
项目最终结果不符合预期怎么办?
作为一个测试开发工程师,要参与哪些流程?