
AI诊断新冠?62个算法一个都不能用,都有重大问题!

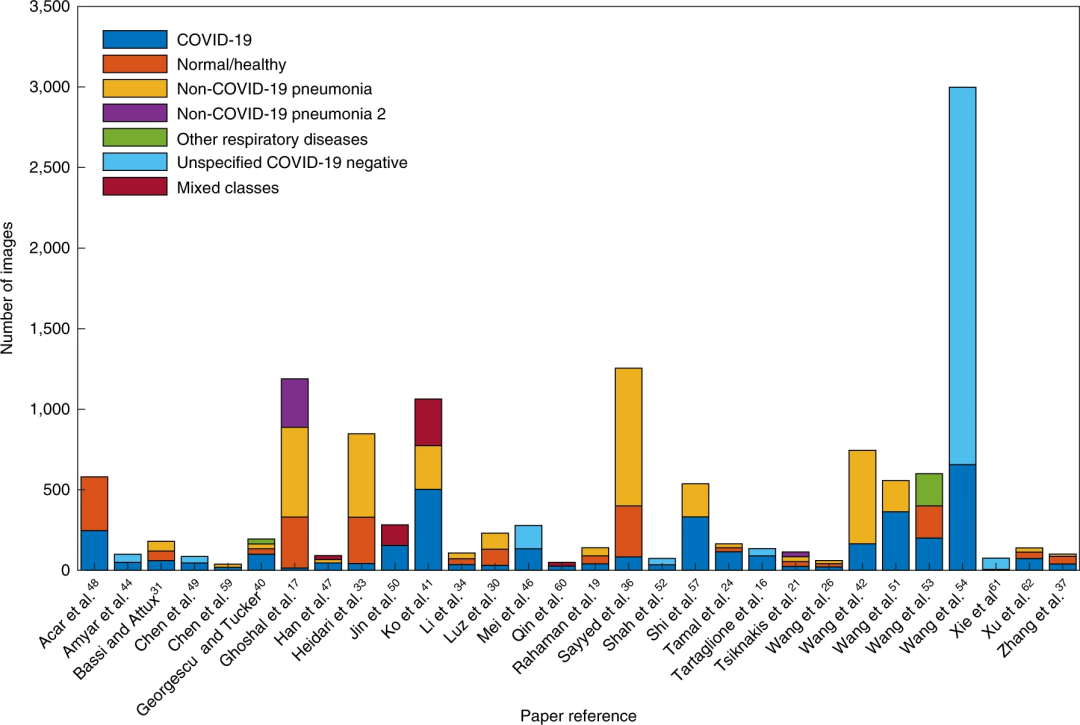
导读:2020 年,新冠肺炎肆虐全球。为了能协助医生快速而精确地筛查潜在患者,各国的计算机科学家们发布了上千种机器学习算法,并声称这些算法能根据胸部 X 光片、CT 图像诊断或预测新冠肺炎。

任何机器学习算法(的应用价值)都取决于训练它所使用的数据,特别是对于像新冠肺炎这样的新流行病来说,数据的多样性是至关重要的。

在新冠疫情初期,人们对信息的渴求是如此强烈,以至于一些论文无疑是仓促出版的。但是,如果你的算法只是基于一家医院的数据之上的话,那么它很可能不适用于另一个城市的某家医院。这些数据需要多样性,最好是国际化的。否则,当你的机器学习算法被更广泛地测试时肯定是要失败的。
用于算法开发的数据使用和常见陷阱; 评估被训练算法; 预测模型的可重复性; 手稿中的文献; 同行评议过程。

评论