
秋招必备:斩获腾讯offer的简历分享!
关于简历+面经分享,希望大家对大家秋招有所帮助。
面试
这次春招实习,一共面了7家公司,经历了20多轮面试,拿了6家offer,最终选择了腾讯的CDG腾讯广告部门,推荐算法岗位,base深圳。
不同于其他面经分享面试官问的具体题目,我主要是从大方向分享如何准备面试,授人以鱼不如授人以渔。分为简历、自我介绍、考察知识点三部分。
1 简历
简历一定清晰简洁,不要花里胡哨,内容控制在一页。参考下面这个模板

除了自己的基本信息外,最重要的就是要项目(实习、比赛、论文都算作项目一种)。有两点需要注意。第一点描述项目的时候不要只罗列关键字!HR和面试官希望能够在项目描述中看到候选人在整个项目中的工作,遇到了什么困难,如何解决,如何对流程进行推进与思考。因为掌握具体的技术是一方面,掌握对AI这种存在不确定性的项目的思考方式和把握更重要。候选人需要展示出对项目问题的深入理解和insight。举例感受一下:
一个不好的例子:
本人项目中使用了TensorFlow、协同过滤、FM、GBDT+LR、DeepFM、DIN等推荐算法
首先这些关键词并不是同一个逻辑概念。其次,完全看不出你是如何使用以及为什么使用这些算法,让人感觉像是在堆砌名词,印象很不好。因为我之前参加了很多AI算法比赛,项目里写的都是比赛经历,这里以比赛举例。
一个好的例子:
我首先对数据EDA发现不少缺失值,使用xxx进行填充。然后根据赛题背景构造了xxx等特征。模型线下验证发现过拟合现象,通过使用xxx特征筛选和正则化解决。同时使用aaa、bbb、ccc进行多模型加权融合。将融合后的数值作为最终结果值。参赛队伍共xxx人,最终获得冠军。
这样一段描述就很有层次地描述出了项目的推进过程,遇到的问题和改进方案,最终取得的成绩。
2 自我介绍
一般面试开头就是自我介绍。自我介绍不要照着简历念,应分为三大块:
个人信息:学历,校园经历 项目:项目含金量如何,取得了怎样不错的成绩。目的就是让面试官觉得你很厉害。前提是符合事实,不要瞎编,否则发现后会被拉进黑名单。 技术栈:很多人会忽略这一重要点。算法范围那么广,每个人都有侧重点,说出自己擅长的技术栈,这样面试官才好针对性提问。
作为开头,一定不能紧张,不然会影响接下来面试的发挥。所以最好自己事先写下来练习好,语速要平稳,保证在2分钟左右即可。
3知识点
3.1 数据结构与算法
数据结构包含:数组、链表、栈、队列、树、散列表、图。数据结构本质是描述数据与数据之间的关系
算法包含:排序、查找、五大经典算法(动态规划、回溯、分支界限、分治、贪心)。计算机解决问题其实没有任何奇技淫巧,它唯一的解决办法就是穷举。算法设计的本质无非就是先思考「如何穷举」,然后再追求「如何聪明地穷举」。「聪明的穷举」分为两部分:「去掉重复的穷举」、「去掉不必要的穷举」。比如,备忘录法,用数组保存求过的结果,用空间换时间,这就是去掉重复的穷举;动态规划根据最优子结构,使当前问题只与某几个子问题有关,从而大大减少问题分解次数,这就是去掉不必要穷举。
注意:很多文章喜欢把递归当做一种算法,这样是错的。递归是一种编程写法,如同循环一样。
准备这一部分的最好方法就是刷题。算法发展时间短,不同于数学发展那么多年,形成了定理公式。数学做一道题,是从这道题涉及到哪些公式着手。而算法做一道题,是看这道题涉及到哪些知识点,这些知识点与以往的哪些题目相联系,相当于是把不会的题目,分解成会的题目,用以前的解法框架,帮助解决不会的题目。比如说,让你求解一个迷宫,你要把这个问题层层抽象:迷宫 -> 图的遍历 -> N 叉树的遍历 -> 二叉树的遍历。然后让框架指导你写具体的解法。所以整个过程是在锻炼你的抽象思维,训练你透过问题找框架。
抽象思维是程序员必备技能,因为计算机本质上就是一门抽象的艺术。具备好的抽象思维对学习能力也是一种极大地提高。后面我会单独写一篇文章,讲解什么是抽象思维,如何训练抽象能力。
另外刷题要有章法,比如:先刷10道动态规划,了解其套路后,再去刷回溯。而不是每天随机刷题。
资料推荐:
LeetCode网站、剑指offer
3.2 机器学习
人工智能、机器学习、深度学习关系如下:
我们一般说机器学习都是指除了深度学习以外的机器学习,也称为传统机器学习。虽然近几年深度学习越来越火,但是很多领域还是在使用机器学习,并且学好机器学习,对于AI算法基础和知识广度都有很大提高。
机器学习模型非常多,全部掌握不现实,我给大家罗列几个经典,也是面试中常考的模型:逻辑回归、SVM、树模型、集成学习、朴素贝叶斯、K-Means聚类、PCA。(EM、最大熵、概率图这些考的少,能了解是加分项)。
在学习过程中,各个模型是相互联系的,不要孤立去分析单个模型。比如:逻辑回归,我认为是最基础、也最重要的模型:

逻辑回归=线性回归+sigmoid激活函数,从而将回归问题转换为分类问题 逻辑回归+矩阵分解,构成了推荐算法中常用的FM模型 逻辑回归+softmax,从而将二分类问题转化为多分类问题 逻辑回归还可以看做单层神经网络,相当于最简单的深度学习模型
通过逻辑回归由点及面,就能演化出如此多模型。再比如树模型。我们把以决策树为基础的一系列模型统称为树模型,也是AI比赛中最常用的模型。
决策树经历了三次改进,ID3、C4.5、CART,主要区别在于一个根据信息增益划分特征、一个根据信息增益率、一个根据基尼指数。 随机森林=决策树+Bagging集成学习 GBDT=决策树+AdaBoost集成学习 XGB是陈天奇2014年提出,相当于GBDT的工程改进版,在实用性和准确度上有很大提升。比如:使用泰勒二阶展开近似损失函数,支持处理缺失值、在特性粒度上并行计算等等特性。 LGB是微软2016年提出,对XGB进行了改进,使用单边梯度采样算法减少不必要的样本;在寻找最优分割点时采用直方图算法使计算代价更小;支持类别特征... CGB是Yandex2017年提出,对类别特征进行了更完美的支持。
所以学习模型,要由点及面,层层递进。这样不仅方便理解,也有利于归纳总结,同时还能锻炼搭建知识体系的能力。
资料推荐:
李航《统计学习方法》,我认认真真看完了这本书,并对重要模型公式进行了一步步推导,收获很大。每次重读这本书都能有新的收获,值得反复阅读。
周志华《机器学习》听说也不错
工具:
numpy、pandas、scikit-learn这三件套需要熟练掌握,特别是scikit-learn,几乎实现了所有机器学习算法。如果自己想实现某个算法来加强理解,也可以参考scikit-learn源码。
3.3 深度学习
前面也提到了,深度学习本属于机器学习,但是鉴于其发展迅速、应用越来越广泛,所以单独拿出来说。深度学习每年新模型、新技术层出不穷,一味追求新技术不可取,要先打好基础。比如:对于一个简单的全连接神经网络,包含训练算法(正向传播、反向传播),激活函数(sigmoid、ReLU、Maxout、softmax等),正则化(L1和L2、Dropout、提前早停等),优化算法(随机梯度下降、Momentum、Adagrad、Adam等)
掌握了基础后,再根据自身领域学习相关的模型。大部分人找工作属于这三个领域:
计算机视觉(CV):卷积神经网络(CNN)及其改进。 自然语言处理(NLP):循环神经网络(RNN)及其改进,Transformer、Bert等。 推荐算法:Embeding、Wide & Deep及其改进。
这三个领域既有所不同,又相互联系。比如:NLP中根据前面n个单词预测下一个单词,如果我把单词看成商品,那么这就成了推荐算法中个性化推荐问题。所以推荐算法中借鉴了很多NLP模型。因此我们在学习的时候不要仅局限于当前领域,也要关注其他领域。当其他领域出现新模型,取得不错进展时,要思考能不能应用在自身领域上。总而言之,这些知识是对立统一,我们要用辩证的思维去学习,去思考。
资料推荐:
《DeepLearning》,又名「花书」被誉为深度学习领域圣经。这本书写的很好,但是内容太多了,一口气吃完不现实。适合当做工具书,时不时拿出来翻阅。
邱锡鹏《神经网络与深度学习》
工具:
TensorFlow、Pytorch。工业上偏向于TensorFlow,学术界偏向于Pytorch。别压注单个,建议两个都学,至少要能看懂别人的代码。因为论文代码复现有的用TensorFlow,有的用Pytorch。
3.4 推荐算法
推荐系统包含了推荐算法。推荐系统架构如下:
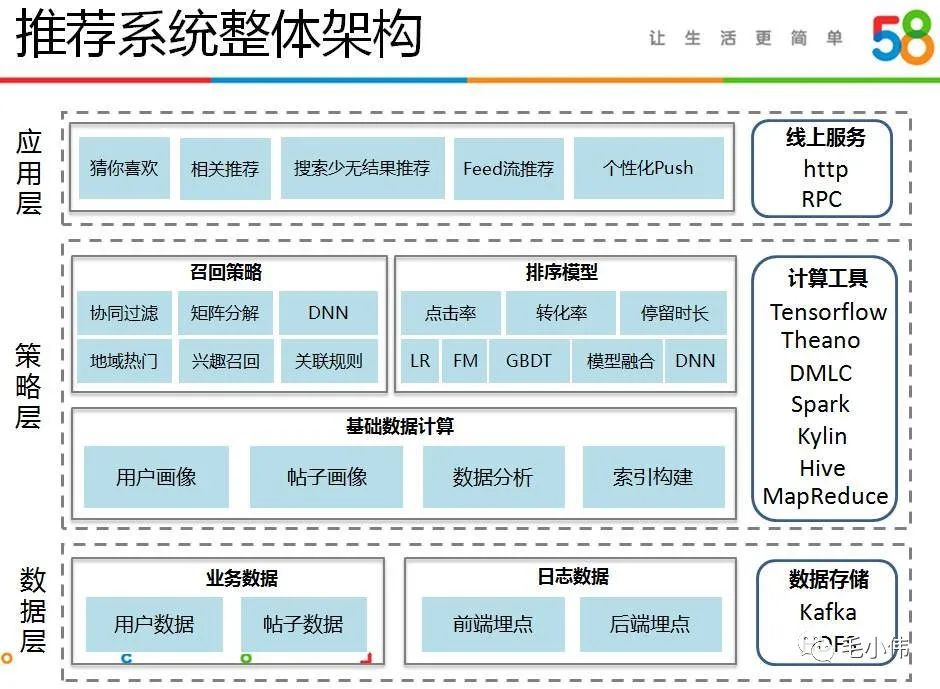
数据层:前后端通过埋点记录用户日志数据,KaFka消息队列将数据存入HDFS大数据文件系统中。这一层技术栈是Hadoop、Spark大数据组件
策略层:平常所说的推荐算法就是指这一层,需要重点掌握。首先是召回,主要根据用户部分特征,从海量的物品库里,快速找回一小部分用户潜在感兴趣的物品,然后交给排序环节,排序环节可以融入较多特征,使用复杂模型,来精准地做个性化推荐。召回强调快,排序强调准。这一块重点掌握模型:协同过滤、矩阵分解、FM、Embeding、Wide&Deep及其改进。
应用层:根据业务需求而不同。比如:广告点击、商品推荐、短视频推荐。
后面我会写一篇文章,分享我的推荐算法学习路线。
资料推荐:
王喆《深度学习推荐系统》,这本书高屋建瓴的介绍了推荐系统整体架构,发展历史以及未来趋势,各种推荐模型的演化之路,很适合前期用来搭建推荐系统知识框架。但是具体的模型并没有深入讲解,还得自己去看论文。这个也很正常,作为算法人员,经常看论文是必须的,就像开发人员要时常看官方技术文档。
3.5 其他
除了数据结构与算法之外,操作系统、计算机网络、计算机组成原理、数据库也是计算机中最基础、最重要的课程。在开发岗面试中必考,算法岗考得相对少,但是掌握这些基础知识,很能提升编程素养,建议还是学一学。虽然我是计算机科班出身,但是之前这方面比较薄弱,去年寒假,我在家把这些课程又重新好好学了一遍,收获很大!后面我会面向非科班的算法人员,对这些课程各写一篇文章进行形象化介绍,让非科班算法人员既能有一个大概的了解,同时又能不拘泥于细节导致颠倒学习重心。
AI算法技术方面,我不会写基础教程文章,因为这些教程网上太多了,我写出来也不一定有别人好。我主要写工作中经过实践的算法技术和前沿知识。内容上一定要有自己的想法,不可照搬。
目前我研究生生涯已过了一半,这期间我最大的收获不是AI算法知识,也不是那些比赛荣誉,而是学习思维和人生感悟。这两把武器就像生活中的锚点,让我面对人生洪流时不至于被冲垮。