
快过年了,来写首诗不?(一)
从短篇小说到写5万字的小说,机器不断涌现出前所未有的词汇。在网页上有大量的例子可供开发人员使用机器学习来编写文本,呈现的效果有荒谬的也有令人叹为观止的。 由于自然语言处理(NLP)领域的重大进步,机器能够自己理解上下文和编造故事。文本生成的例子包括,机器编写了流行小说的整个章节,比如《权力的游戏》和《哈利波特》,取得了不同程度的成功。
现在,有大量的数据可以按顺序分类。它们以音频、视频、文本、时间序列、传感器数据等形式存在。针对这样特殊类别的数据,如果两个事件都发生在特定的时间内,A先于B和B先于A是完全不同的两个场景。然而,在传统的机器学习问题中,一个特定的数据点是否被记录在另一个数据点之前是不重要的。这种考虑使我们的序列预测问题有了新的解决方法。
文本是由一个挨着一个的字符组成的,实际中是很难处理的。这是因为在处理文本时,可以训练一个模型来使用之前发生的序列来做出非常准确的预测,但是之前的一个错误的预测有可能使整个句子变得毫无意义。这就是让文本生成器变得棘手的原因!
诗词生成思路

自然语言生成是自然语言处理里面最有意思的任务之一,本文中主要指古诗自动写诗。文本生成通常包含以下步骤:1.导入依赖 2.加载数据 3.创建映射 4.数据预处理 5.模型构建及训练 6.文本生成。
而在模型构建中,我们使用了循环神经网络对输入进来的诗词序列进行特征提取,并做出预测结果。具体思路如下:
由前六个字预测出下一个字。
利用“寒随穷律变,”预测出“春”。
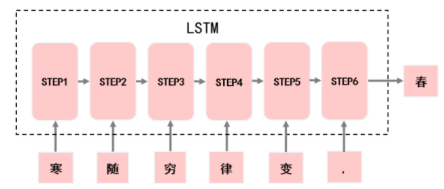
利用“随穷律变,春”预测出“逐”。
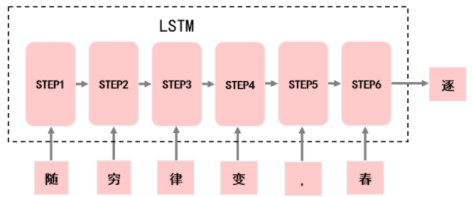
然后利用这样的方式去构建循环神经网络即可一步一步地往下预测,实现古诗创作,即:
寒随穷律变, -> 春
随穷律变,春 -> 逐
穷律变,春逐 -> 鸟
律变,春逐鸟 -> 声
变,春逐鸟声 -> 开
,春逐鸟声开 -> 。
……
最终得到古诗:寒随穷律变,春逐鸟声开。初风飘带柳,晚雪间花梅。碧林青旧竹,绿沼翠新苔。芝田初雁去,绮树巧莺来。
数据集处理
数据集如下(回复‘诗词生成’即可获取数据),是一个大概4.3w首古诗的文本文件,我们需要对数据进行处理,使之可以喂给模型进行训练:

首先,我们定义一个LoadData.py函数,然后导入依赖,写入第一个函数load_file(),这个函数主要用来读取数据,并且对数据进行切割和提取。
import numpy as npfrom collections import Counterimport os# from tensorflow.keras import utils# 读取数据def load_file(path):res=''with open(path,'r',encoding='utf8') as f:for value in f:ones=value.strip().split(':')[1:][0]if len(ones.split(',')[0])==5:res+=ones+'0'return res
我们将调用一下这个函数,并将结果保存到txt文件中,可以得到如下的文件,我们提取了五言绝句的诗词,然后去掉了诗的名字,并在诗的末尾添加一个终止符’0’。
cont=load_file(path='poetry.txt')with open('cont.txt','w',encoding='utf8') as f:f.write(cont)

接着,我们需要制作词典。词典的意思就是说,在诗中的每一个中文都有对应的索引。而后面我们喂给模型进行训练的数据就是由这些索引组成的诗句。这里我们提取出现次数较多的前5000个词作为词典。
# 获得词典def get_wordDict(res,word_len=5000):words=sorted(list(res))word_dict=Counter(words)wordPairs = sorted(word_dict.items(), key=lambda x: -x[1])wordPairs=wordPairs[:word_len]wordlist=[]for w in wordPairs:wordlist.append(w[0]+'\n')with open('word_list.txt','w',encoding='utf8') as f:f.writelines(wordlist)
将load_file中的返回值输入到get_wordDict()中,运行结果如下,这就是我们制作好的字典。

接着,我们编写一个函数get_data(),用来获得完整的诗句以及我们刚刚提取的词典:
# 获得完整的诗句,以及词典def get_data():res=load_file('poetry.txt')if not os.path.isfile('word_list.txt'):wordlist=get_wordDict(res)with open('word_list.txt','r',encoding='utf8')as f:wordlist=[i.strip() for i in f.readlines()]res_list=res.split('0')return res_list,wordlist
然后,编写函数get_index(),用来循环每一首诗句,并提取出我们想要的 6个字符预测一个字符的格式。
# 获得数据def get_index(cont,wordlist,num_classes):# 将中文转换成索引cont_index=[wordlist.index(i) if i in wordlist elsewordlist.index('z') for i in cont]data=[]label=[]#for i in range(len(cont_index)):if i < len(cont_index)-6:data.append(cont_index[i:i+6])label.append([cont_index[i+6]])print(cont_index[i:i+6],'==>'[cont_index[i+6]])return data,label
我们调用一下这个函数,cont是一首完整的诗,而wordlist是字典。输出的结果如下,这是我们想要的格式:

接着,我们还要进行独热编码,将数据与标签都变成独热编码的形式:
def one_host(data,num_classes,batch_size):array=np.zeros((batch_size,len(data[0]),num_classes))m=len(data)for i in range(m):for index,value in enumerate(data[i]):array[i,index,int(value)]=1.return array
最后,我们把数据组装成生成器的形式,这可以让我们一边训练一边加载数据。避免内存溢出的情况,具体代码如下:
# 将数据组装成生成器def gen_data(cont,wordlist,batch_size=1,num_classes=5000):# 使用循环一直读取数据while True:x_data=[]y_data=[]# 读取每一首诗for i in cont:# 获取诗的索引并将每首诗组装成 6-》1的形式。返回值都是数组=get_index(i,wordlist,num_classes=num_classes)=(data)=(label)# 当长度大于批次大小时if len(x_data)>batch_size:x=x_data[:batch_size]y=y_data[:batch_size]# 对数据进行独热编码x=one_host(x,num_classes,batch_size)y=one_host(y,num_classes,batch_size)x=np.array(x).reshape(-1,6,num_classes)y=np.array(y).reshape(-1,num_classes)# 懒加载yield x,y# 保证诗的完整性x_data=x_data[batch_size:]y_data=y_data[batch_size:]
这样,一个数据生成器就制作好了,我们可以使用如下的方式来确认生成数据的准确性:
cont,wordlist=get_data()# 每个批次16条数据gan=gen_data(cont,wordlist,16)for i in range(1):x,y=next(gan)print(np.argmax(x,axis=-1),np.argmax(y,axis=-1))
程序运行的结果如下:
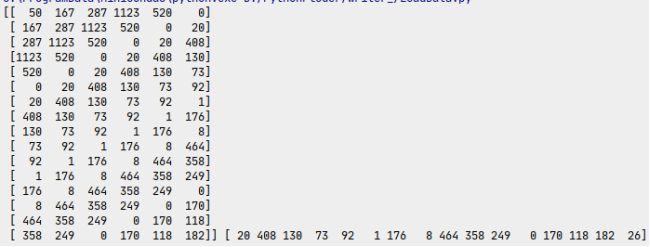
和我们想要的数据格式是一致的。
寒随穷律变, -> 春
随穷律变,春 -> 逐
穷律变,春逐 -> 鸟
律变,春逐鸟 -> 声
变,春逐鸟声 -> 开
,春逐鸟声开 -> 。
……
由于篇幅关系,训练步骤放在下篇
生成结果预览
