
聊聊 fencing token 分布式锁
在上一篇 『聊聊 Redis 分布式锁』 写完之后,本来认为已经找到了很完美的 Redis 分布式锁方案。后来发现 Redission 官方已经弃用 Red Lock 的相关 API,并推荐使用 FencedLock 来替代 Red Lock。于是开始展开了对 FencedLock 的研究
FencedLock 是基于 fencing token 这个理论来的,是由分布式系统专家 Martin Kleppmann 为了反驳 Redis Red Lock 提出的,感兴趣的同学可以阅读下「How to do distributed locking」。
fencing token 解决的痛点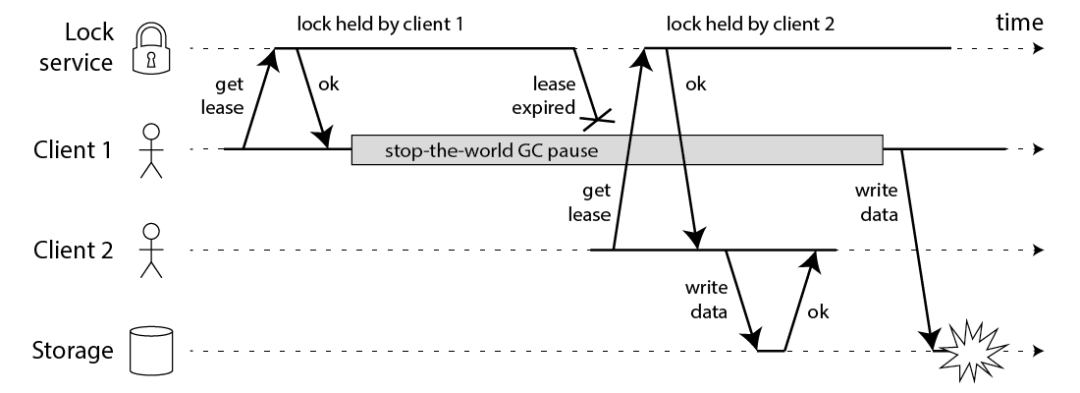 unsafe lock
unsafe lock场景描述如下:
- Client 1 获取到 Redis 锁,发生长时间 GC(GC 时间超过了锁的持有时间)导致锁过期
- Client 2 获取到锁,并开始写数据
- Client 1 从 GC 中恢复过来,此时它并不知道自己的锁已经失效了,也开始写数据
此时发生了并发写,违背了我们使用分布式锁的初衷。其实上一篇文章中也提到了这个问题,但是当时我并不知道有什么好的解决方案。
fencing token 的出现解决了上述问题
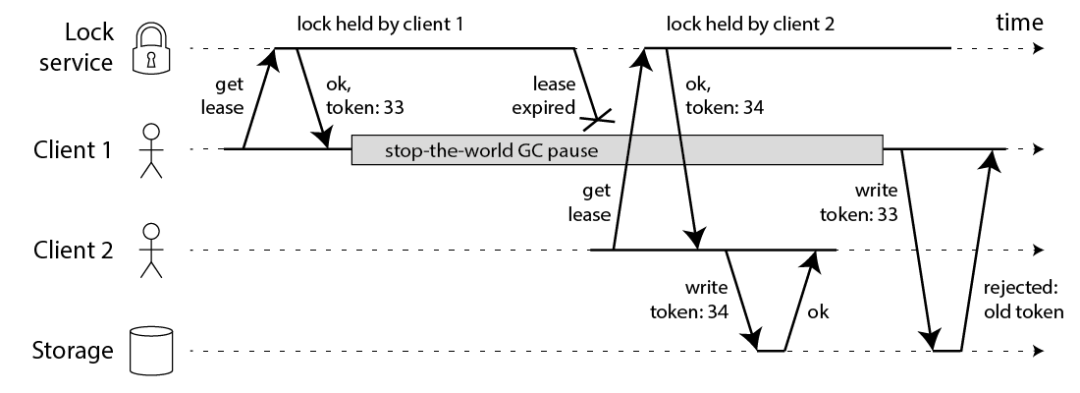 fencing token
fencing tokenfencing token 的逻辑
-
Lock Service(分布式锁)在获取锁的同时要给客户端返回一个自增的 fencing token
-
Storage(共享资源服务)需要存储最新的 fencing token,并且在操作数据之前与 Client 的 token 进行比对。如果 Client 请求时携带的 token 小于 current token,则拒绝请求
再回到之前场景中
- Client 1 获取到锁后,长时间 GC 导致锁过期
- Client 2 获取到锁,并开始写数据
- Client 1 从 GC 中恢复过来,开始写数据,但是由于此时 Storage 存储的 token 为 34,所以 Client 1 的请求被拒绝了
fencing token 的问题
可能你认为 GC 不会存在这么长时间。引用下 Martin Kleppmann 的观点,虽然本文中一直将 GC 列为 STW 的原因。但除了 GC,网络 I/O 也可能成为进程暂停的原因之一
使用了 fencing token 就可以高枕无忧的使用分布式锁了吗?
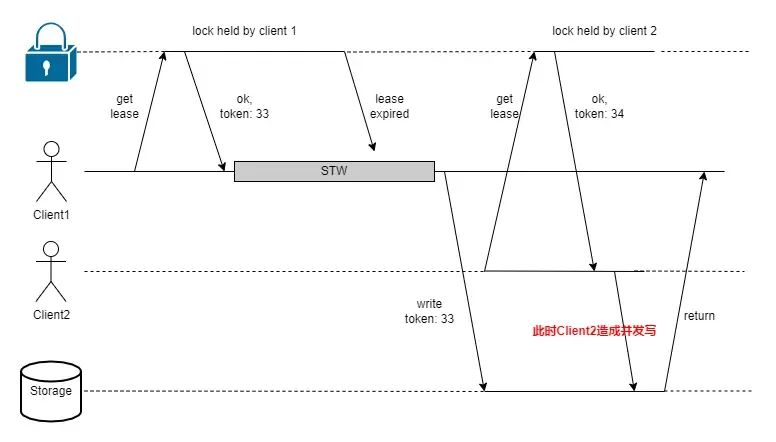 fencing token problem
fencing token problem- Client 1 获取到锁,token 为 33。长时间 GC 导致锁过期
- Client 1 从 GC 中恢复过来,开始写数据
- Client 2 获取到锁,token 为 34。并开始写数据
此时再次发生并发写
由此可见 fencing token 也并不是一个完美的分布式锁方案
其他分布式锁的问题那么使用其他的分布式锁,例如 zookeeper 可以完全避免“并发写”吗?
答案也是不能。
举个场景,zookeeper 使用临时节点的方式实现分布式锁。假设持有锁的客户端突然无法连接到 zookeeper,网络一直无法恢复,客户端也没有在 session 失效前完成对共享资源的操作。session 失效后,其他客户端可以持有锁,就有可能发生并发写
关于分布式锁的看法目前我的看法是,想在复杂的分布式环境中,实现一个完美的锁,几乎是不可能的。
那么分布式锁真的就没用了吗?
上面举的几个例子,是理论上可能发生的,但并不是每次都会这样。在使用分布式锁的时候,需要明白,它并不能够绝对的保证安全。
解决 “并发写” 最简单的方式还是使用数据库写锁,但是大量的写锁竞争是会造成性能问题的。这时候我们可以让分布式锁作为最外层的屏障。这样写锁既保证了业务的安全,也不会成为性能瓶颈
或者换一个思路,使用支持顺序消费的 MQ 也可以解决并发写同一数据的问题
目前看来最适合使用分布式锁的情况是,多次执行也不会造成错误,只是会增加计算成本的场景
参考https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
https://github.com/redisson/redisson/wiki/8.-distributed-locks-and-synchronizers/#810-fenced-lock