
新年新气象,超级文献下载工具更新了!一行命令下载任意文献
之前为了解决学生无力支付国内部分论文平台的付费阅读的问题,我们推出了超级文献下载工具:你不得不知道的python超级文献批量搜索下载工具。
在最初的这几个版本中,同学们必须通过编写代码才能选择不同的文献源去搜索和下载文献。很多同学在使用过程中会由于对Python不熟悉或者环境没有配置好而产生不少问题。
为了解决这些问题,我们给他增加了命令行调用的方式,并上传到了PyPi,你只需要一行命令,就能下载到你所需要的文献!(感谢 @hulei6188 的开源贡献)
1.准备
开始之前,你要确保Python和pip已经成功安装在电脑上,如果没有,请访问这篇文章:超详细Python安装指南 进行安装。
Windows环境下打开Cmd(开始—运行—CMD),苹果系统环境下请打开Terminal(command+空格输入Terminal),输入命令安装依赖:
pip install scihub-cn看到 Successfully installed ... 就代表成功安装scihub-cn。
不过请注意,scihub-cn依赖 aiohttp 模块进行并发的下载,因此支持的最低Python版本为3.6.
项目源代码:https://github.com/Ckend/scihub-cn
2.Scihub-cn 使用方法
2.1 使用DOI号下载论文
首先让我们来试试根据DOI号下载文献:
scihub-cn -d 10.1038/s41524-017-0032-0下载的论文会自动生成在当前文件夹下:
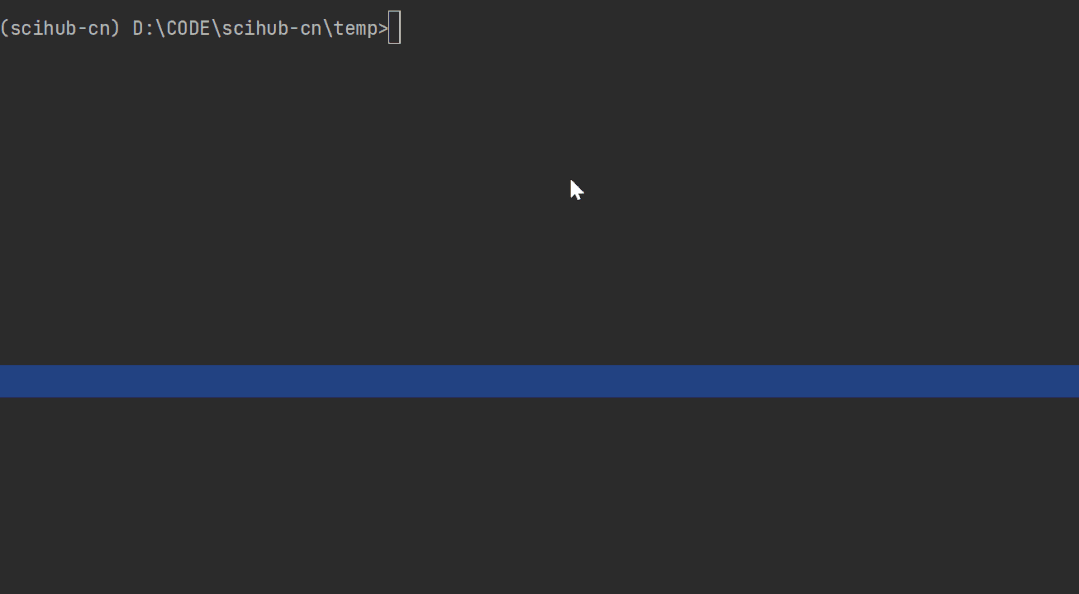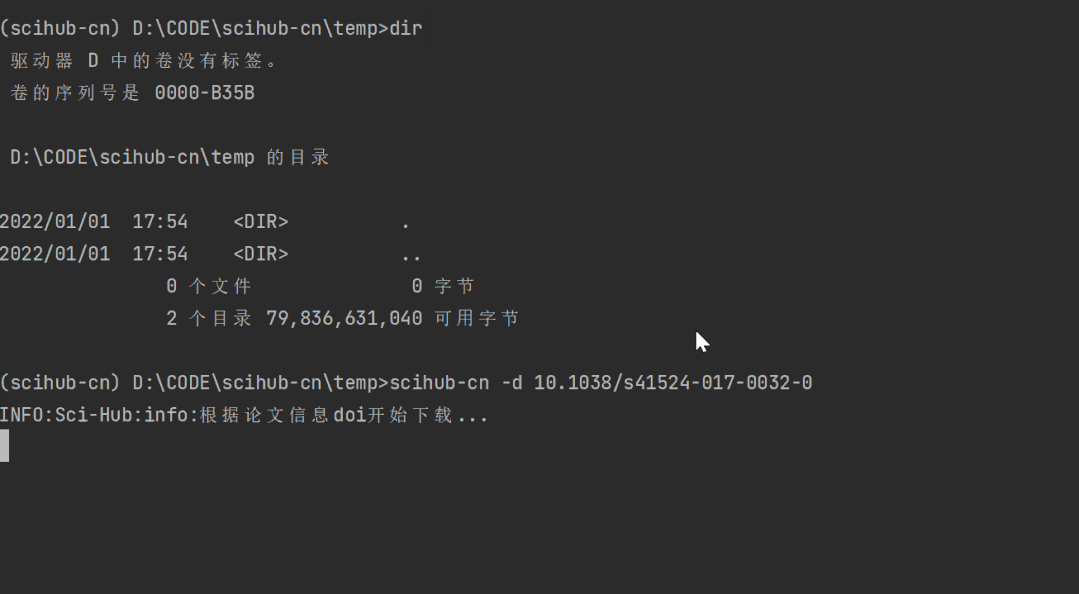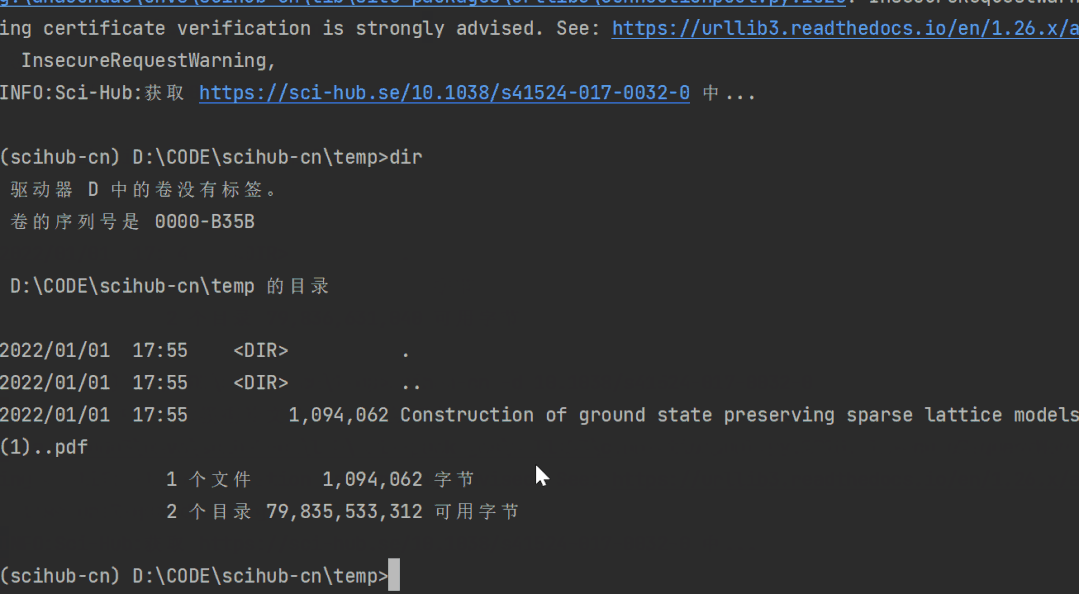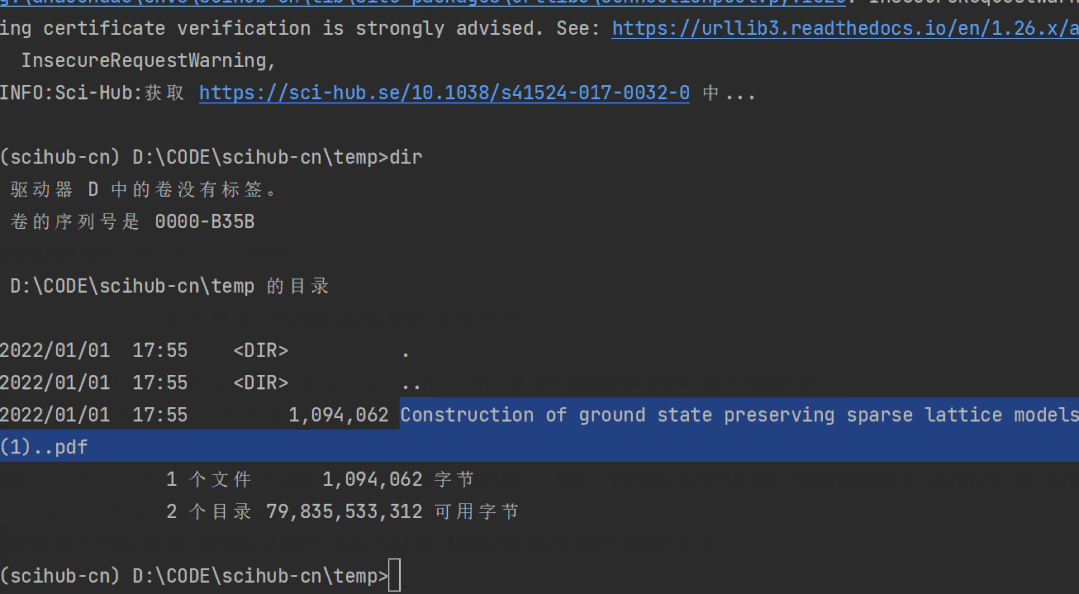
你也可以选择将其下载到任意目录下,只需要添加 -o 参数:
scihub-cn -d 10.1038/s41524-017-0032-0 -o D:\papers这将会把这篇论文下载到D盘的papers文件夹中。
2.2 根据关键词下载论文
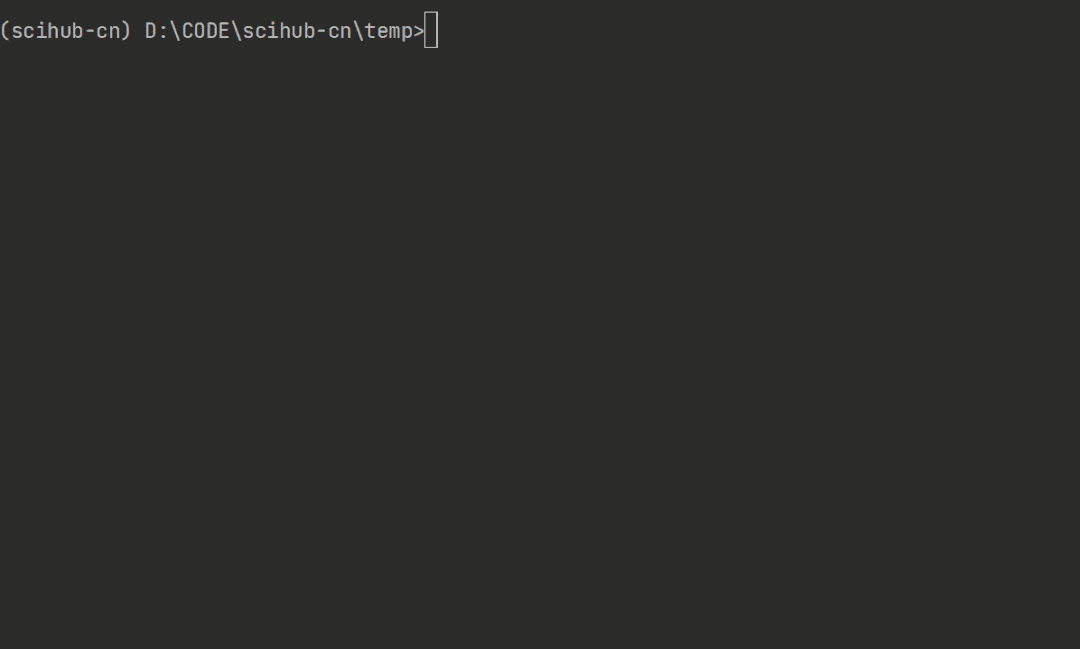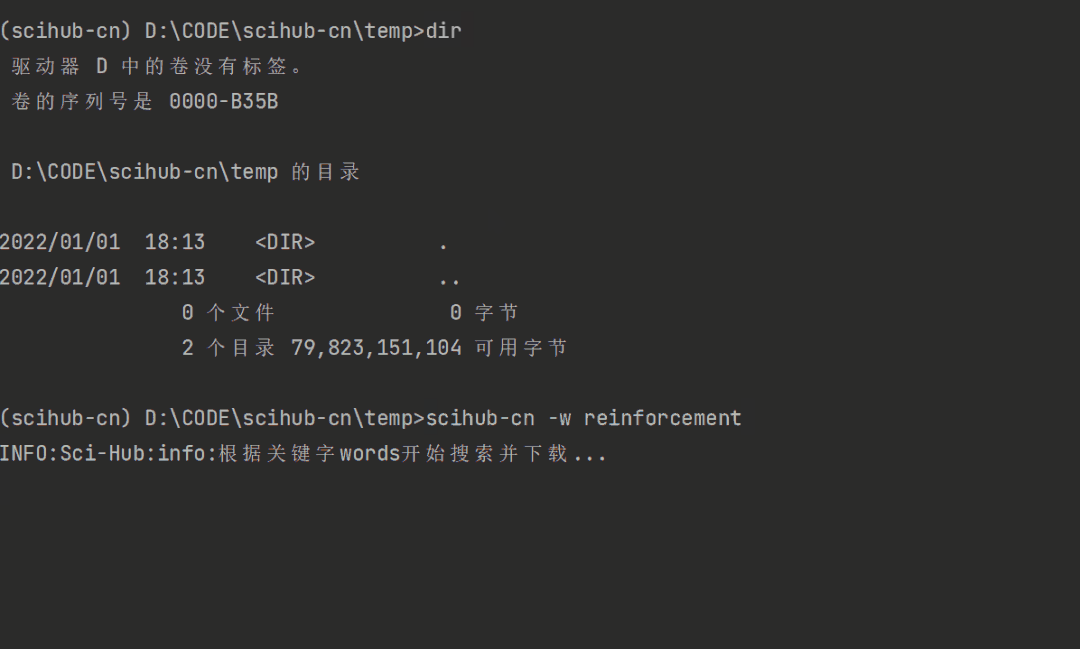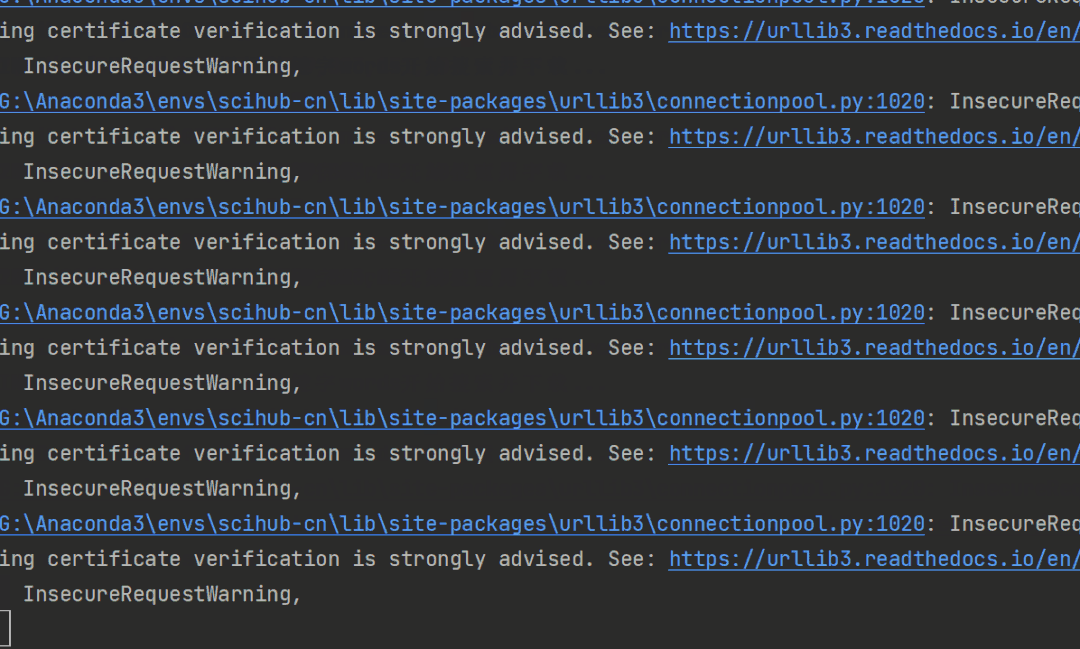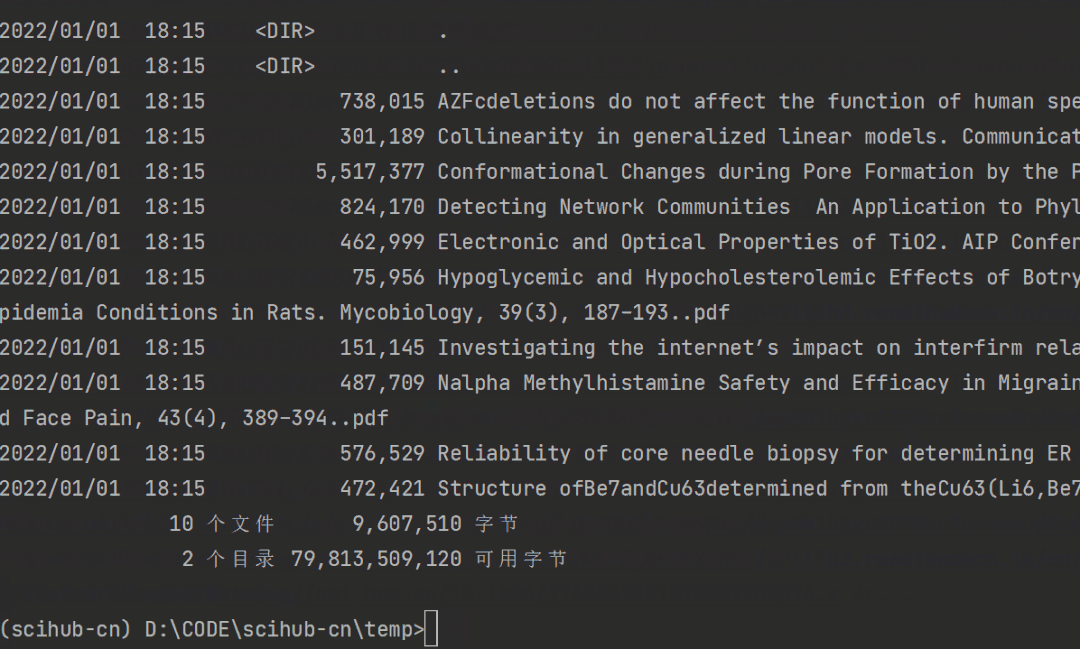
使用 -w 参数指定一个关键词,可以通过关键词下载论文:
scihub-cn -w reinforcement效果如下:
同样滴,它也支持-o参数指定文件夹。此外,这里默认使用的搜索引擎是百度学术,你也可以使用Google学术、publons、science_direct等。通过指定 -e 参数即可:
scihub-cn -w reinforcement -e google_scholar为了避免Google学术无法连接,你还可以增加代理 -p 参数:
scihub-cn -w reinforcement -e google_scholar -p http://127.0.0.1:10808
访问外网数据源的时候,增加代理能避免出现Connection closed等问题。
此外,你还能限定下载的篇目, 比如我希望下载100篇文章:
scihub-cn -w reinforcement -l 1002.3 根据url下载论文
给定任意论文地址,可以让scihub-cn尝试去下载该论文:
scihub-cn -u https://ieeexplore.ieee.org/document/26502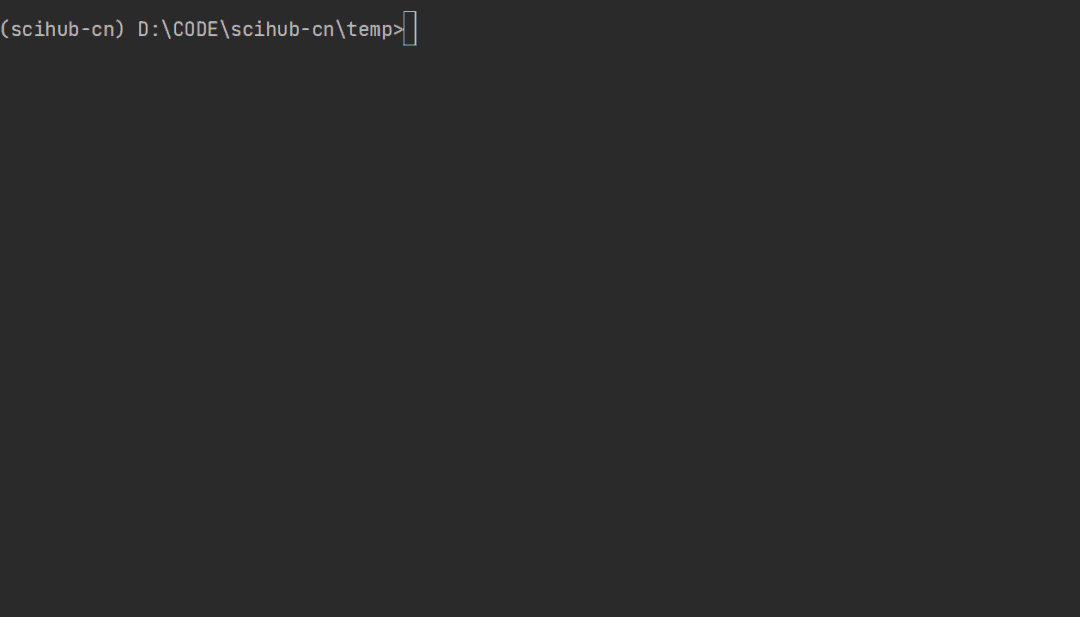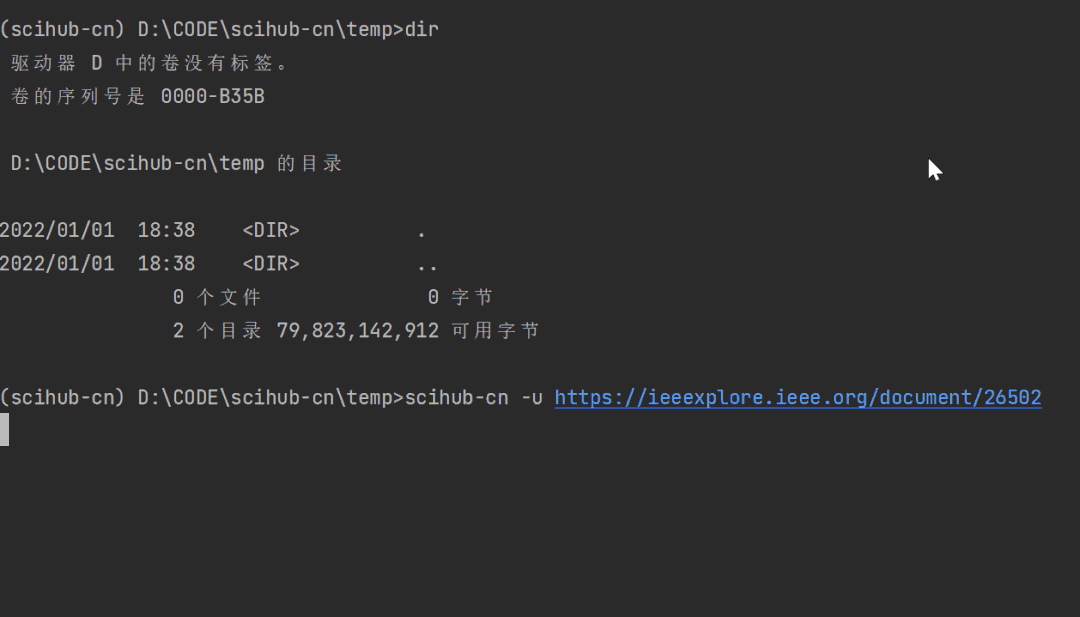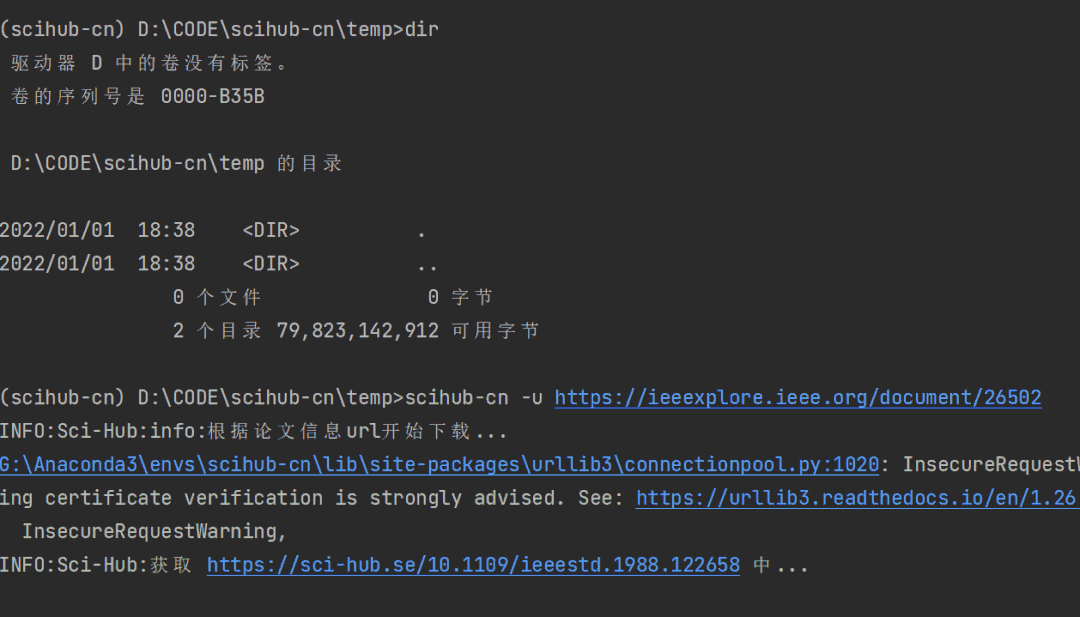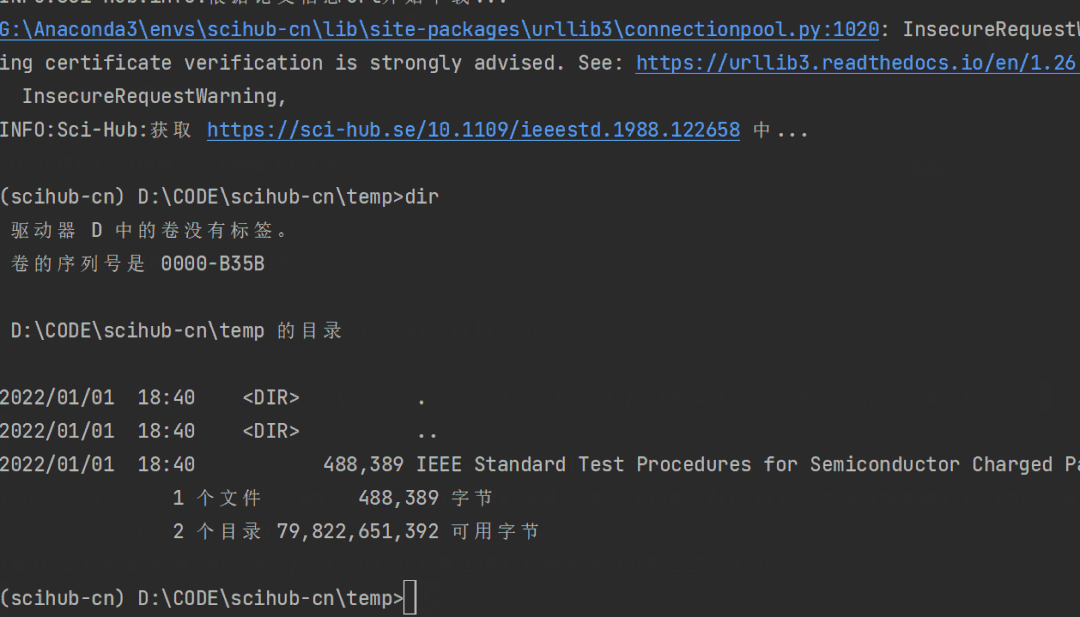
使用 -u 参数指定论文链接即可,非常方便。
3.批量下载论文
当然,之前花了几篇文章优化的批量下载模块这个版本肯定少不了!
而且还增加了几种新的批量下载方式:
1. 根据给出所有论文名称的txt文本文件下载论文。
2. 根据给出所有论文url的txt文件下载论文。
3. 根据给出所有论文DOI号的txt文本文件下载论文。
4. 根据给出bibtex文件下载论文。
比如,根据给出所有论文URL的txt文件下载论文:
scihub-cn -i urls.txt --url
效果如下:
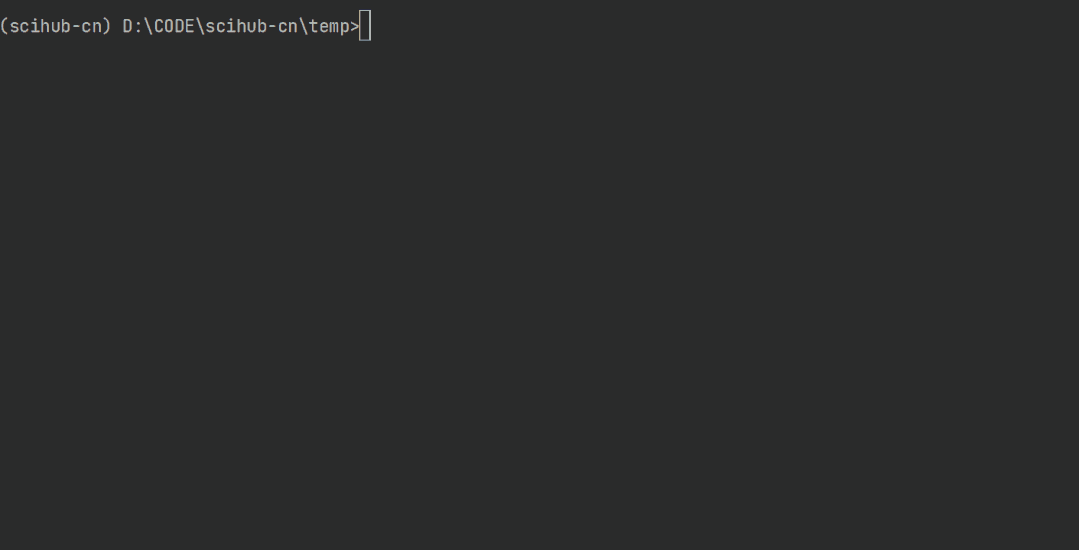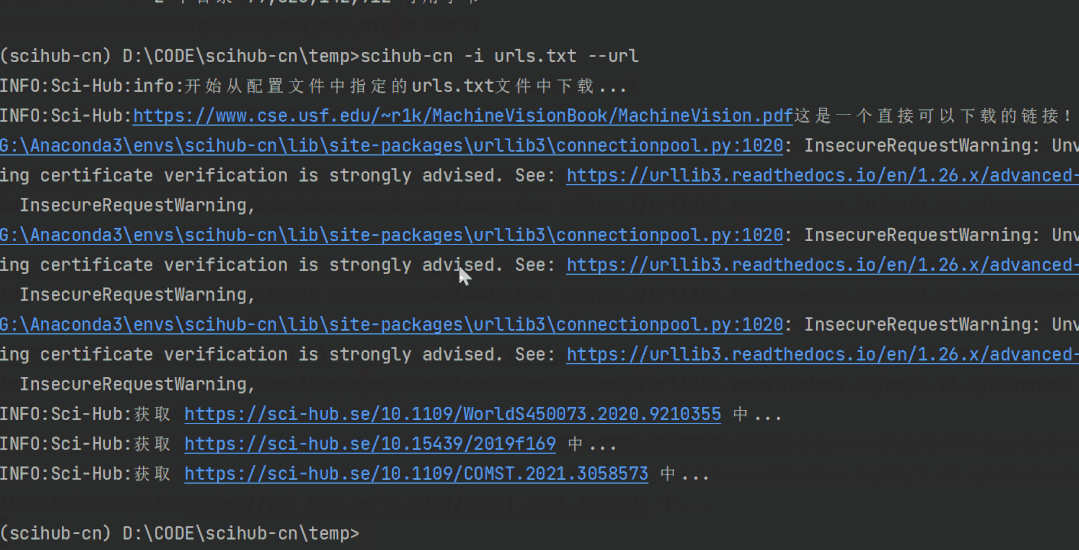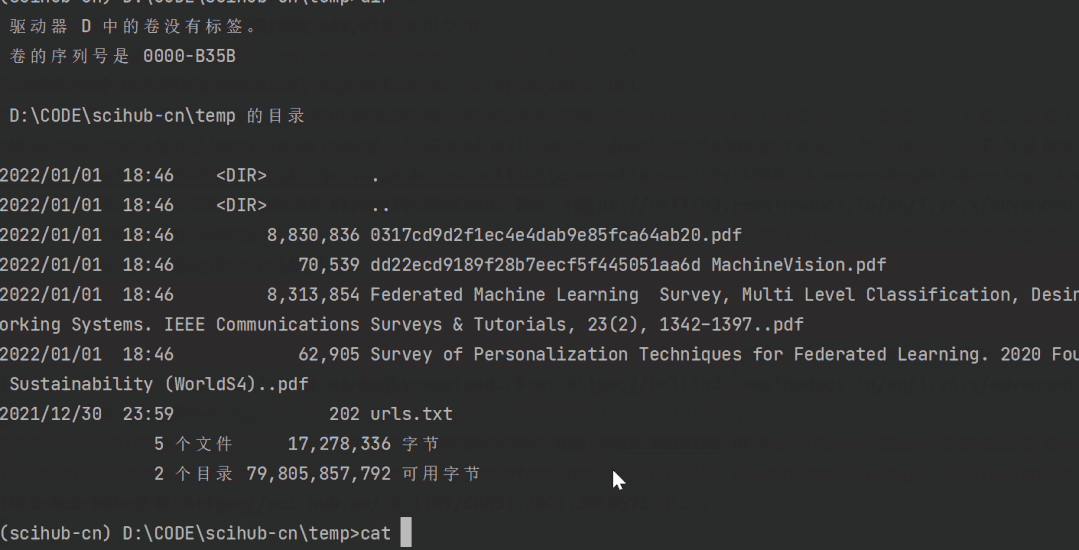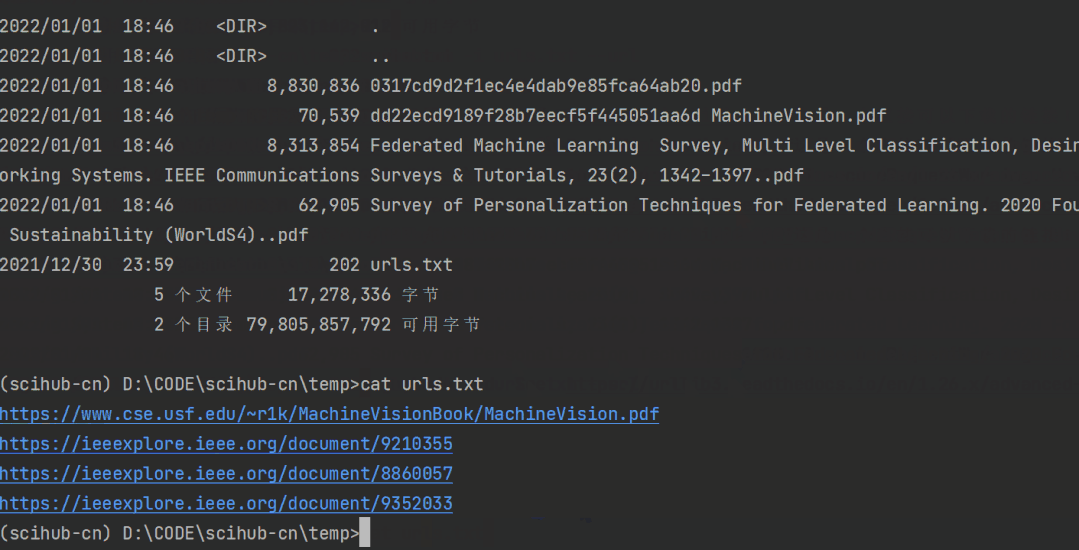
可以看到,文件内有4个论文链接,而他也成功地下载到了这4篇论文。
再试试放了DOI号的txt文件的批量下载:
scihub-cn -i dois.txt --doi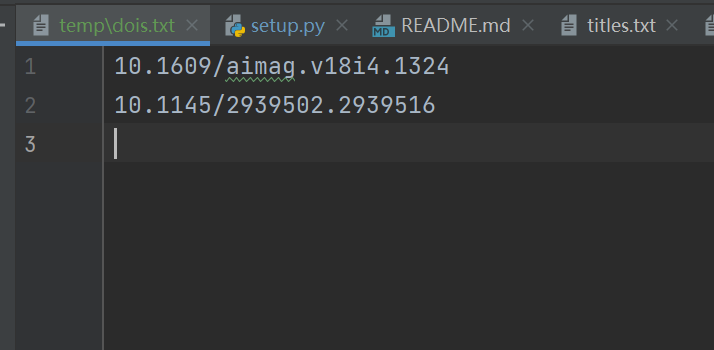
效果如下:
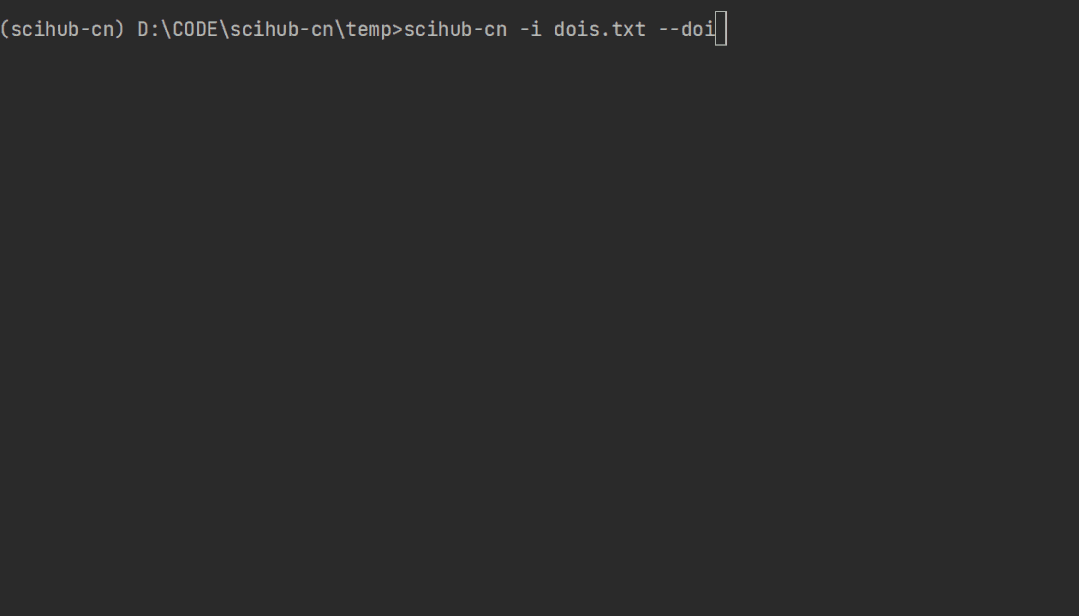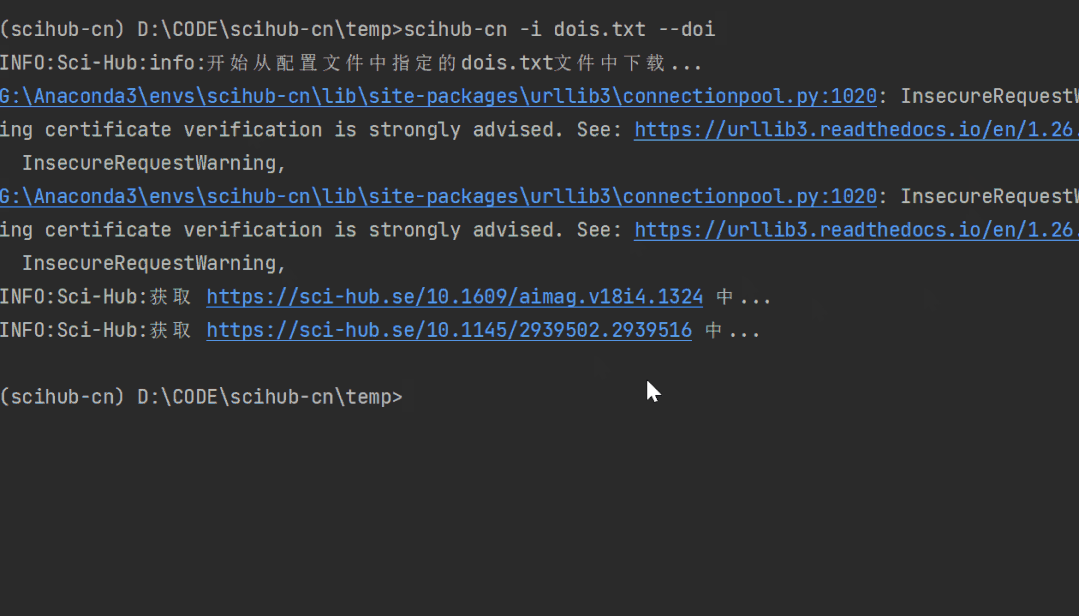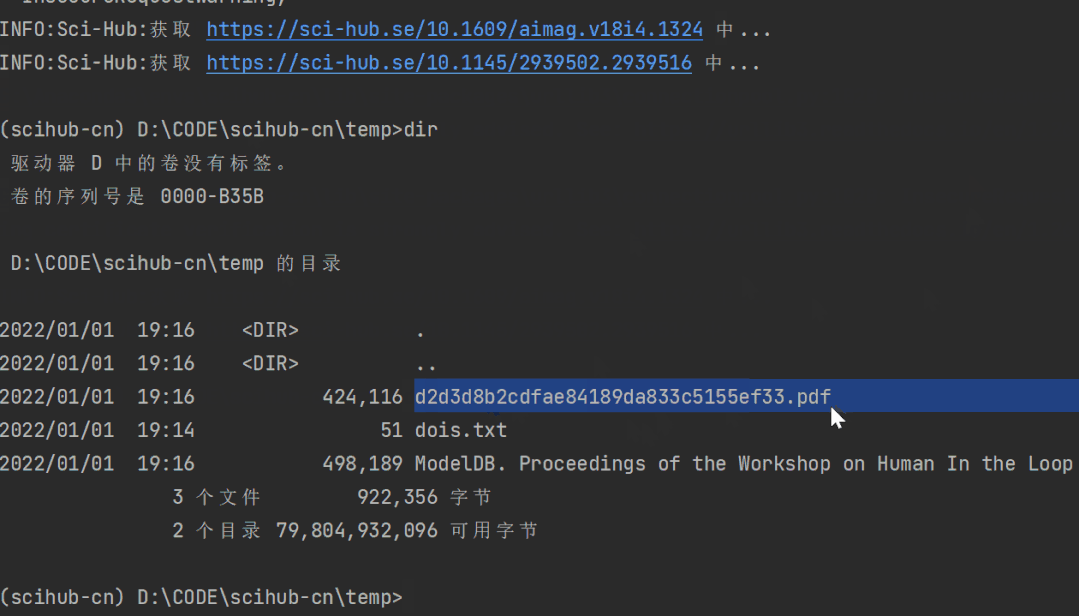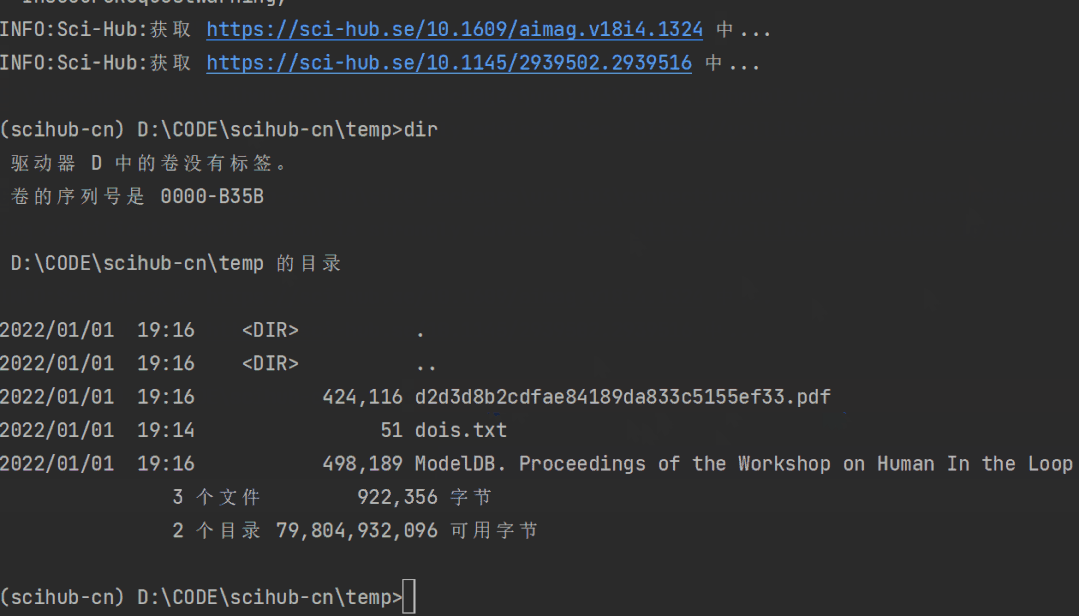
你可以输入 scihub-cn --help 看到更多的参数说明:
$scihub-cn --help
... ...
optional arguments:
-h, --help show this help message and exit
-u URL input the download url
-d DOI input the download doi
--input INPUTFILE, -i INPUTFILE
input download file
-w WORDS, --words WORDS
download from some key words,keywords are linked by
_,like machine_learning.
--title download from paper titles file
-p PROXY, --proxy PROXY
use proxy to download papers
--output OUTPUT, -o OUTPUT
setting output path
--doi download paper from dois file
--bib download papers from bibtex file
--url download paper from url file
-e SEARCH_ENGINE, --engine SEARCH_ENGINE
set the search engine
-l LIMIT, --limit LIMIT
limit the number of search result大家如果有更多的想法,可以往我们这个开源项目贡献代码,我也非常希望能够有更多人参与这个项目:
https://github.com/Ckend/scihub-cn
本文仅限参考研究,下载的论文请在24小时内阅读后删除,请勿将此项目用于商业目的。
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典