
利用 Python 实现 Excel 办公常用操作!
本文用的主要是pandas,绘图用的库是plotly,实现的Excel的常用功能有:
Python和Excel的交互
vlookup函数
数据透视表
绘图
以后如果发掘了更多Excel的功能,会回来继续更新和补充。开始之前,首先按照惯例加载pandas包:
import numpy as np
import pandas as pd
pd.set_option('max_columns', 10)
pd.set_option('max_rows', 20)
pd.set_option('display.float_format', lambda x: '%.2f' % x) # 禁用科学计数法
Python和Excel的交互
pandas里最常用的和Excel I/O有关的四个函数是read_csv/ read_excel/ to_csv/ to_excel,它们都有特定的参数设置,可以定制想要的读取和导出效果。比如说想要读取这样一张表的左上部分:
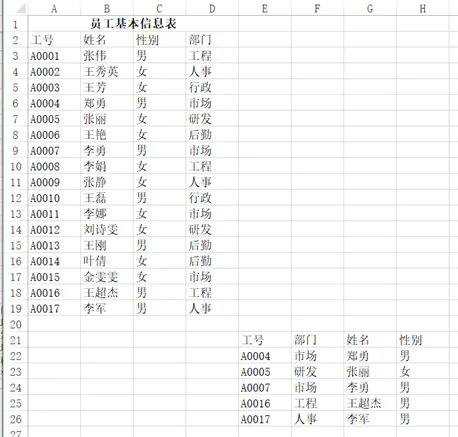
可以用pd.read_excel("test.xlsx", header=1, nrows=17, usecols=3),返回结果:
df
工号 姓名 性别 部门
0 A0001 张伟 男 工程
1 A0002 王秀英 女 人事
2 A0003 王芳 女 行政
3 A0004 郑勇 男 市场
4 A0005 张丽 女 研发
5 A0006 王艳 女 后勤
6 A0007 李勇 男 市场
7 A0008 李娟 女 工程
8 A0009 张静 女 人事
9 A0010 王磊 男 行政
10 A0011 李娜 女 市场
11 A0012 刘诗雯 女 研发
12 A0013 王刚 男 后勤
13 A0014 叶倩 女 后勤
14 A0015 金雯雯 女 市场
15 A0016 王超杰 男 工程
16 A0017 李军 男 人事
输出函数也同理,使用多少列,要不要index,标题怎么放,都可以控制。
vlookup函数
vlookup号称是Excel里的神器之一,用途很广泛,下面的例子来自豆瓣,VLOOKUP函数最常用的10种用法,你会几种?[2]
案例一
问题:A3:B7单元格区域为字母等级查询表,表示60分以下为E级、60~69分为D级、70~79分为C级、80~89分为B级、90分以上为A级。D:G列为初二年级1班语文测验成绩表,如何根据语文成绩返回其字母等级?
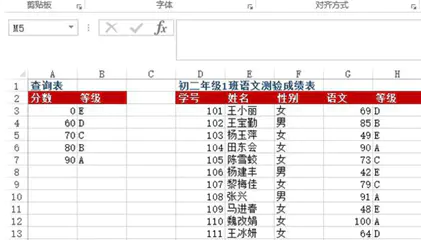
方法:在H3:H13单元格区域中输入=VLOOKUP(G3, $A$3:$B$7, 2)
python实现:
df = pd.read_excel("test.xlsx", sheet_name=0)
def grade_to_point(x):
if x >= 90:
return 'A'
elif x >= 80:
return 'B'
elif x >= 70:
return 'C'
elif x >= 60:
return 'D'
else:
return 'E'
df['等级'] = df['语文'].apply(grade_to_point)
df
学号 姓名 性别 语文 等级
0 101 王小丽 女 69 D
1 102 王宝勤 男 85 B
2 103 杨玉萍 女 49 E
3 104 田东会 女 90 A
4 105 陈雪蛟 女 73 C
5 106 杨建丰 男 42 E
6 107 黎梅佳 女 79 C
7 108 张兴 男 91 A
8 109 马进春 女 48 E
9 110 魏改娟 女 100 A
10 111 王冰研 女 64 D
案例二
问题:在Sheet1里面如何查找折旧明细表中对应编号下的月折旧额?(跨表查询)
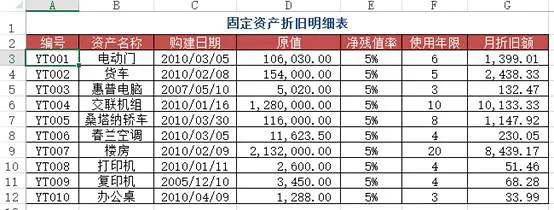

方法:在Sheet1里面的C2:C4单元格输入 =VLOOKUP(A2, 折旧明细表!A$2:$G$12, 7, 0)
python实现:使用merge将两个表按照编号连接起来就行
df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表')
df2 = pd.read_excel("test.xlsx", sheet_name=1) #题目里的sheet1
df2.merge(df1[['编号', '月折旧额']], how='left', on='编号')
编号 资产名称 月折旧额
0 YT001 电动门 1399
1 YT005 桑塔纳轿车 1147
2 YT008 打印机 51
案例三
问题:类似于案例二,但此时需要使用近似查找
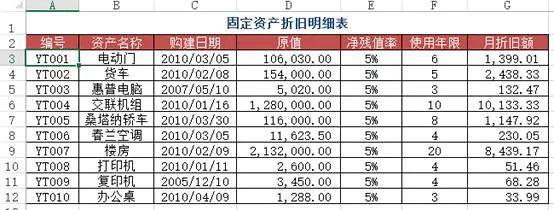
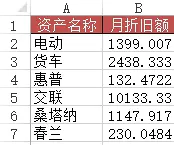
方法:在B2:B7区域中输入公式=VLOOKUP(A2&"*", 折旧明细表!$B$2:$G$12, 6, 0)
python实现:这个比起上一个要麻烦一些,需要用到一些pandas的使用技巧
df1 = pd.read_excel("test.xlsx", sheet_name='折旧明细表')
df3 = pd.read_excel("test.xlsx", sheet_name=3) #含有资产名称简写的表
df3['月折旧额'] = 0
for i in range(len(df3['资产名称'])):
df3['月折旧额'][i] = df1[df1['资产名称'].map(lambda x:df3['资产名称'][i] in x)]['月折旧额']
df3
资产名称 月折旧额
0 电动 1399
1 货车 2438
2 惠普 132
3 交联 10133
4 桑塔纳 1147
5 春兰 230
案例四
问题:在Excel中录入数据信息时,为了提高工作效率,用户希望通过输入数据的关键字后,自动显示该记录的其余信息,例如,输入员工工号自动显示该员工的信命,输入物料号就能自动显示该物料的品名、单价等。如图所示为某单位所有员工基本信息的数据源表,在“2010年3月员工请假统计表”工作表中,当在A列输入员工工号时,如何实现对应员工的姓名、身份证号、部门、职务、入职日期等信息的自动录入?
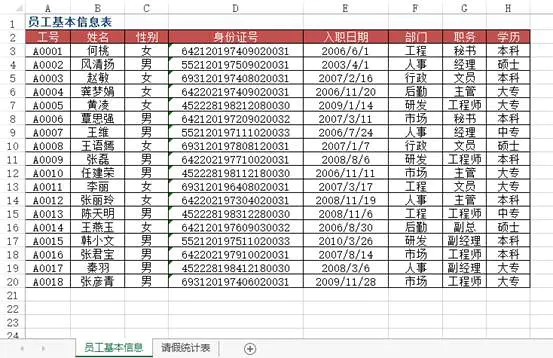
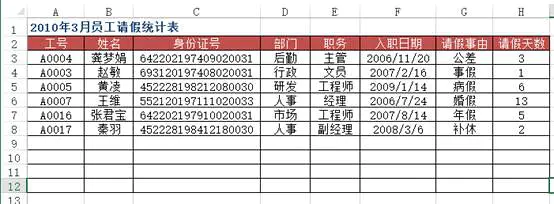
方法:使用VLOOKUP+MATCH函数,在“2010年3月员工请假统计表”工作表中选择B3:F8单元格区域,输入下列公式=IF($A3="","",VLOOKUP($A3,员工基本信息!$A:$H,MATCH(B$2,员工基本信息!$2:$2,0),0)),按下【Ctrl+Enter】组合键结束。
python实现:上面的Excel的方法用得很灵活,但是pandas的想法和操作更简单方便些。
df4 = pd.read_excel("test.xlsx", sheet_name='员工基本信息表')
df5 = pd.read_excel("test.xlsx", sheet_name='请假统计表')
df5.merge(df4[['工号', '姓名', '部门', '职务', '入职日期']], on='工号')
工号 姓名 部门 职务 入职日期
0 A0004 龚梦娟 后勤 主管 2006-11-20
1 A0003 赵敏 行政 文员 2007-02-16
2 A0005 黄凌 研发 工程师 2009-01-14
3 A0007 王维 人事 经理 2006-07-24
4 A0016 张君宝 市场 工程师 2007-08-14
5 A0017 秦羽 人事 副经理 2008-03-06
案例五
问题:用VLOOKUP函数实现批量查找,VLOOKUP函数一般情况下只能查找一个,那么多项应该怎么查找呢?如下图,如何把张一的消费额全部列出?
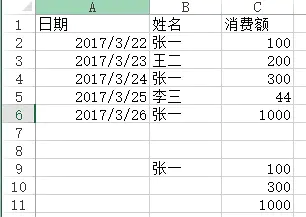
方法:在C9:C11单元格里面输入公式=VLOOKUP(B$9&ROW(A1),IF({1,0},$B$2:$B$6&COUNTIF(INDIRECT("b2:b"&ROW($2:$6)),B$9),$C$2:$C$6),2,),按SHIFT+CTRL+ENTER键结束。
python实现:vlookup函数有两个不足(或者算是特点吧),一个是被查找的值一定要在区域里的第一列,另一个是只能查找一个值,剩余的即便能匹配也不去查找了,这两点都能通过灵活应用if和indirect函数来解决,不过pandas能做得更直白一些
df6 = pd.read_excel("test.xlsx", sheet_name='消费额')
df6[df6['姓名'] == '张一'][['姓名', '消费额']]
姓名 消费额
0 张一 100
2 张一 300
4 张一 1000
数据透视表
数据透视表是Excel的另一个神器,本质上是一系列的表格重组整合的过程。这里用的案例来自知乎,Excel数据透视表有什么用途?[3]
问题:需要汇总各个区域,每个月的销售额与成本总计,并同时算出利润
通过Excel的数据透视表的操作最终实现了下面这样的效果:
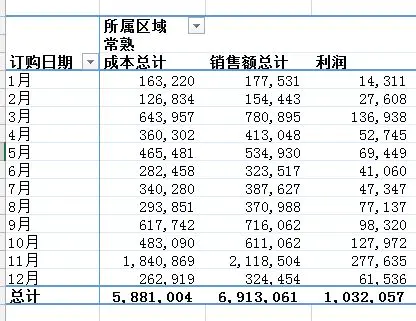
python实现:对于这样的分组的任务,首先想到的就是pandas的groupby,代码写起来也简单,思路就是把刚才Excel的点鼠标的操作反映到代码命令上:
df = pd.read_excel('test.xlsx', sheet_name='销售统计表')
df['订购月份'] = df['订购日期'].apply(lambda x:x.month)
df2 = df.groupby(['订购月份', '所属区域'])[['销售额', '成本']].agg('sum')
df2['利润'] = df2['销售额'] - df2['成本']
df2
销售额 成本 利润
订购月份 所属区域
1 南京 134313.61 94967.84 39345.77
常熟 177531.47 163220.07 14311.40
无锡 316418.09 231822.28 84595.81
昆山 159183.35 145403.32 13780.03
苏州 287253.99 238812.03 48441.96
2 南京 187129.13 138530.42 48598.71
常熟 154442.74 126834.37 27608.37
无锡 464012.20 376134.98 87877.22
昆山 102324.46 86244.52 16079.94
苏州 105940.34 91419.54 14520.80
... ... ...
11 南京 286329.88 221687.11 64642.77
常熟 2118503.54 1840868.53 277635.01
无锡 633915.41 536866.77 97048.64
昆山 351023.24 342420.18 8603.06
苏州 1269351.39 1144809.83 124541.56
12 南京 894522.06 808959.32 85562.74
常熟 324454.49 262918.81 61535.68
无锡 1040127.19 856816.72 183310.48
昆山 1096212.75 951652.87 144559.87
苏州 347939.30 302154.25 45785.05
[60 rows x 3 columns]
也可以使用pandas里的pivot_table函数来实现:
df3 = pd.pivot_table(df, values=['销售额', '成本'], index=['订购月份', '所属区域'] , aggfunc='sum')
df3['利润'] = df3['销售额'] - df3['成本']
df3
成本 销售额 利润
订购月份 所属区域
1 南京 94967.84 134313.61 39345.77
常熟 163220.07 177531.47 14311.40
无锡 231822.28 316418.09 84595.81
昆山 145403.32 159183.35 13780.03
苏州 238812.03 287253.99 48441.96
2 南京 138530.42 187129.13 48598.71
常熟 126834.37 154442.74 27608.37
无锡 376134.98 464012.20 87877.22
昆山 86244.52 102324.46 16079.94
苏州 91419.54 105940.34 14520.80
... ... ...
11 南京 221687.11 286329.88 64642.77
常熟 1840868.53 2118503.54 277635.01
无锡 536866.77 633915.41 97048.64
昆山 342420.18 351023.24 8603.06
苏州 1144809.83 1269351.39 124541.56
12 南京 808959.32 894522.06 85562.74
常熟 262918.81 324454.49 61535.68
无锡 856816.72 1040127.19 183310.48
昆山 951652.87 1096212.75 144559.87
苏州 302154.25 347939.30 45785.05
[60 rows x 3 columns]
pandas的pivot_table的参数index/ columns/ values和Excel里的参数是对应上的(当然,我这话说了等于没说,数据透视表里不就是行/列/值吗还能有啥。。)

但是我个人还是更喜欢用groupby,因为它运算速度非常快。我在打kaggle比赛的时候,有一张表是贷款人的行为信息,大概有2700万行,用groupby算了几个聚合函数,几秒钟就完成了。
groupby的功能很全面,内置了很多aggregate函数,能够满足大部分的基本需求,如果你需要一些其他的函数,可以搭配使用apply和lambda。不过pandas的官方文档说了,groupby之后用apply速度非常慢,aggregate内部做过优化,所以很快,apply是没有优化的,所以建议有问题先想想别的方法,实在不行的时候再用apply。我打比赛的时候,为了生成一个新变量,用了groupby的apply,写了这么一句:ins['weight'] = ins[['SK_ID_PREV', 'DAYS_ENTRY_PAYMENT']].groupby('SK_ID_PREV').apply(lambda x: 1-abs(x)/x.sum().abs()).iloc[:,1],1000万行的数据,足足算了十多分钟,等得我心力交瘁。
绘图
因为Excel画出来的图能够交互,能够在图上进行一些简单操作,所以这里用的python的可视化库是plotly,案例就用我这个学期发展经济学课上的作业吧,当时的图都是用Excel画的,现在用python再画一遍。开始之前,首先加载plotly包。
import plotly.offline as off
import plotly.graph_objs as go
off.init_notebook_mode()
柱状图
当时用Excel画了很多的柱状图,其中的一幅图是
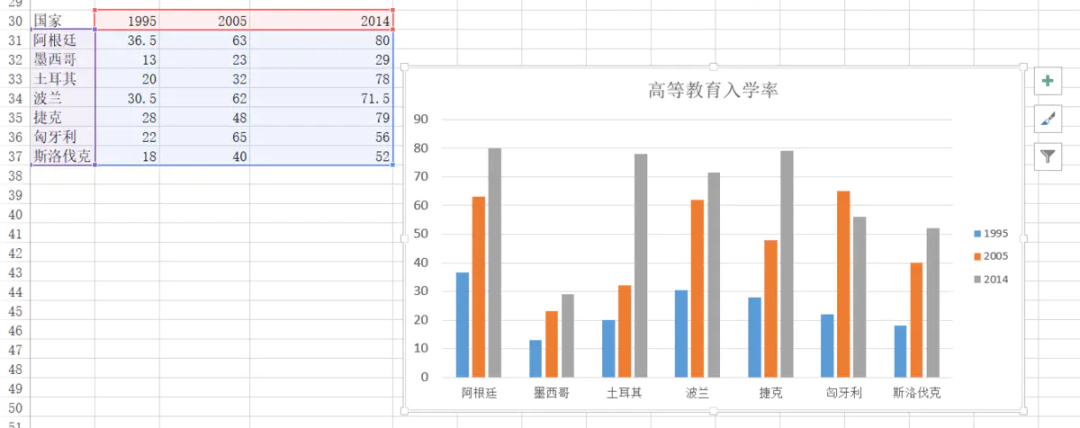
下面用plotly来画一下
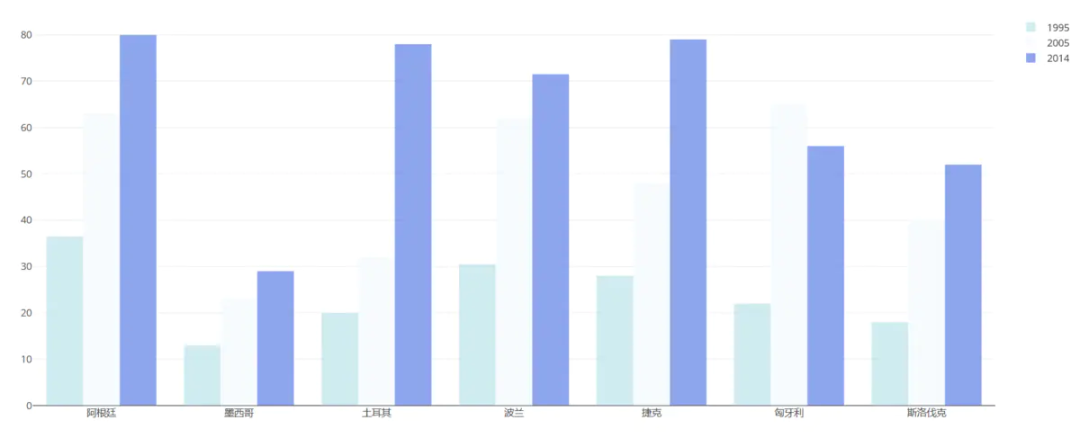
df = pd.read_excel("plot.xlsx", sheet_name='高等教育入学率')
trace1 = go.Bar(
x=df['国家'],
y=df[1995],
name='1995',
opacity=0.6,
marker=dict(
color='powderblue'
)
)
trace2 = go.Bar(
x=df['国家'],
y=df[2005],
name='2005',
opacity=0.6,
marker=dict(
color='aliceblue',
)
)
trace3 = go.Bar(
x=df['国家'],
y=df[2014],
name='2014',
opacity=0.6,
marker=dict(
color='royalblue'
)
)
layout = go.Layout(barmode='group')
data = [trace1, trace2, trace3]
fig = go.Figure(data, layout)
off.plot(fig)
雷达图
用Excel画的:
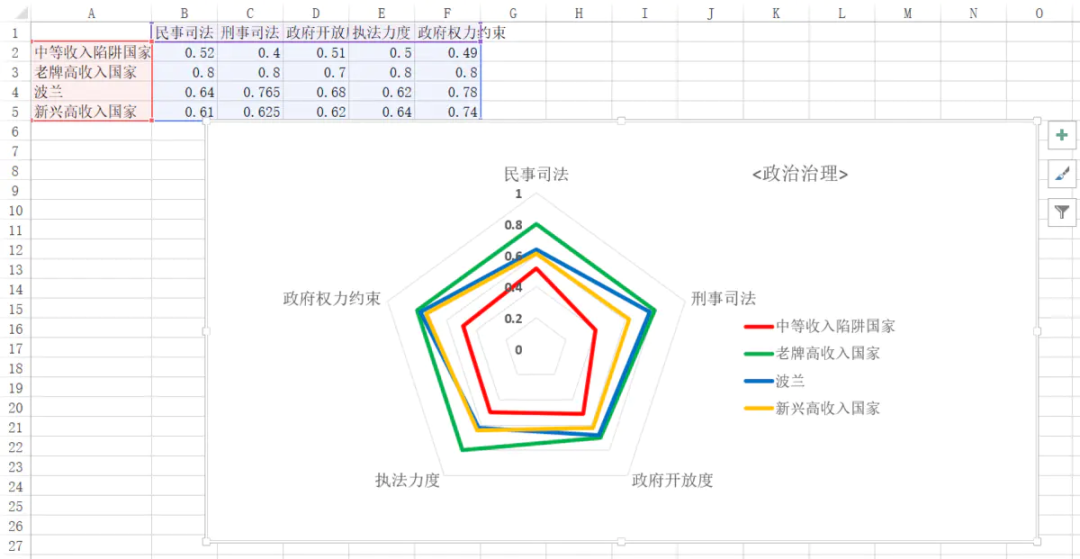
用python画的:
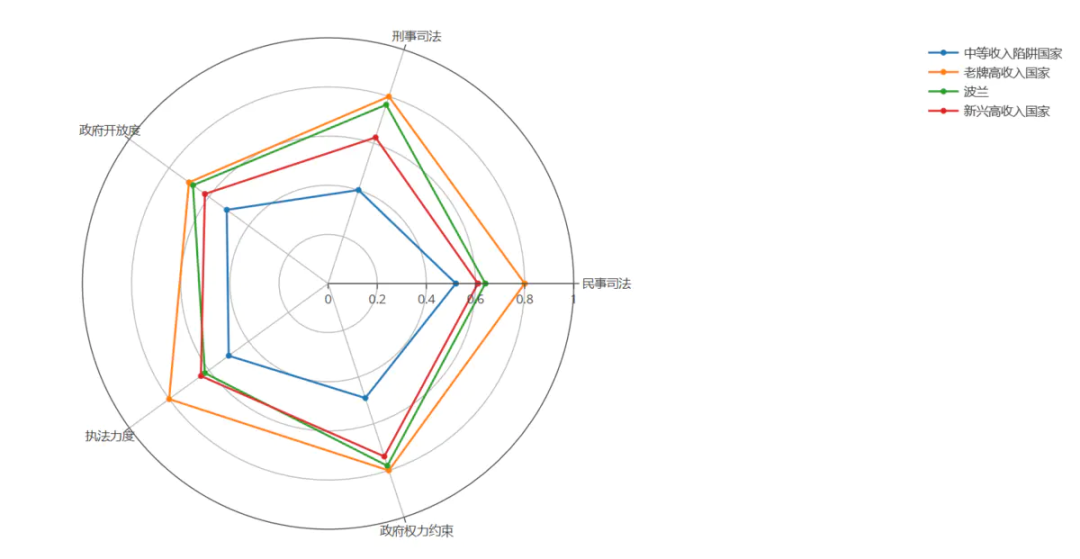
df = pd.read_excel('plot.xlsx', sheet_name='政治治理')
theta = df.columns.tolist()
theta.append(theta[0])
names = df.index
df[''] = df.iloc[:,0]
df = np.array(df)
trace1 = go.Scatterpolar(
r=df[0],
theta=theta,
name=names[0]
)
trace2 = go.Scatterpolar(
r=df[1],
theta=theta,
name=names[1]
)
trace3 = go.Scatterpolar(
r=df[2],
theta=theta,
name=names[2]
)
trace4 = go.Scatterpolar(
r=df[3],
theta=theta,
name=names[3]
)
data = [trace1, trace2, trace3, trace4]
layout = go.Layout(
polar=dict(
radialaxis=dict(
visible=True,
range=[0,1]
)
),
showlegend=True
)
fig = go.Figure(data, layout)
off.plot(fig)
画起来比Excel要麻烦得多。总体而言,如果画简单基本的图形,用Excel是最方便的,如果要画高级一些的或者是需要更多定制化的图形,使用python更合适。
参考资料
[1]来源: https://www.jianshu.com/p/9bc9f473dd22
[2]VLOOKUP函数最常用的10种用法,你会几种?: https://www.douban.com/note/617113346/
[3]Excel数据透视表有什么用途?: https://www.zhihu.com/question/22484899/answer/39933218
--- EOF ---