
HDFS 在 HA 模式集群下 JournalNode 节点的作用
早期文章

HDFS 在非 HA 模式的集群下,NameNode 和 DataNode 是一个主从的架构。在这样的主从架构之下只有一台 NameNode。一台 NameNode 的好处是无需因为元数据的同步而考虑数据的一致性问题。但是,只有一台 NameNode 也会有很多的坏处,因为,单台 NameNode 的情况下会出现所有单机都会出现的问题。最简单的问题就是,当这一台 NameNode 挂掉后,整个集群将不可用了。
为了解决单台 NameNode 挂掉不可用的问题,HDFS 在 2.x 版本的时候引入了 HDFS 集群的 HA 模式,也就是有了 NameNode 的主备架构。在 2.x 的版本中,HDFS 支持一主一备的架构,在 3.x 的版本中最多支持 5 个,官方推荐使用 3 个。(这里只整理了 HDFS 在单 NameNode 情况下挂掉的问题,没有整理关于容量的问题)。
一、HDFS 两个 NN 同步哪些数据
在 HDFS 非 HA 模式的集群下,只有一个 NameNode,而在 HDFS 的 HA 模式集群下,存在两个 NameNode,一个是活动的 NameNode,称为 Active,另外一个是备用的 NameNode,称为 Standby。当 Active 节点出现问题时,需要将 Standby 节点切换为 Active 节点来为客户端提供服务,那么,这就需要 Standby 节点存储的元数据和 Active 节点的元数据保持相一致。
那么,Standby 节点和 Active 节点是如何保持它们的数据相一致呢?先来回顾一下 NameNode 中存放的为何物。
HDFS 的 NameNode 保存着 HDFS 集群中的 元数据。元数据的来源分为两部分,一部分是客户端提供的,比如在 HDFS 命令行或者通过 HDFS Java API (HDFS 命令行和 HDFS Java API 都可以看成是 HDFS 的客户端)创建了一个目录,那么就会在 NameNode 下创建对应的元数据;另一部分的元数据来源于 DataNode 提供的 Block 等信息的元数据。
NameNode 中存放了这两种元数据,那么 Active 节点和 Standby 节点都是 NameNode,它们之间的数据是如何一致的呢?通过 HDFS 客户端操作形成的元数据,需要在 Active 节点和 Standby 节点进行同步;DataNode 提供的 Block 等信息的元数据,会同时提交给 Active 节点和 Standby 节点。那么,真正要在 Active 节点和 Standby 节点进行同步的元数据只有客户端操作产生的元数据了。
二、两个节点同步数据的数据一致性问题
那么在 Active 节点和 Standby 节点应该如何同步数据呢?这里先不写结论,先整理一下问题。
首先,假设 Active 节点和 Standby 节点使用同步阻塞的方式同步数据,那情况是这样的。客户端创建目录,Active 节点接收到命令创建了相应的元数据,然后同步给 Standby 节点,Standby 节点同步完成信息后返回成功的确认给 Active 节点,Active 节点返回创建成功给客户端。这样一切正常。但是,如果 Standby 节点故障了,没有给 Active 返回同步成功的确认信息,那么 Active 节点可能会卡很久,等超时后告诉客户端命令执行失败了。这样可能会造成用户体验不好,影响了用户的可用性。那么问题来了,在 HA 模式下引入 Standby 节点的 NameNode 本身是要提高集群的可用性,但是由于它的延迟、故障等又影响了正常节点的可用性。这种方式的好处在于它保证了两个节点之间的数据强一致性,却可能使得整体的可用性不好。
那么,此时换一种方式,使用异步非阻塞模式。Active 节点把要同步的数据发给了 Standby 节点,然后告诉客户端已经成功了。但是使用了异步非阻塞模式,此时 Standby 节点可能什么也没做,也可能它做的过程中故障了,导致同步失败。这样,客户端和 Active 节点的可用性有了,但是 Active 节点和 Standby 节点之间的两个节点的一致性没了。
那么,HDFS 如何解决两个节点数据一致性和可用性的问题呢?答案是 HDFS 引入了 JournalNode 节点。
三、HDFS 中的 JournalNode 节点
为了保证 Active 节点和 Standby 节点,即可以可靠的保持数据的一致性,又不会影响集群的可用性,HDFS 在 Active 节点和 Standby 节点之间引入了另外一个节点 JournalNode 节点。
JournalNode 节点作为 Active 节点和 Standby 节点的中间节点,它为两个节点解决了数据的同步的问题。首先 Active 节点会将元数据发送给 JournalNode 节点,然后 Standby 节点会从 JournalNode 节点获取需要同步的元数据。即使 Standby 节点故障了、产生问题了,在它恢复正常状态后,也可以从 JournalNode 节点中同步相应的数据。这就要求 JournalNode 节点需要有持久化的功能来保证元数据不丢。
但是,问题又来了,JournalNode 节点如果挂掉又怎么办?那么这就对 JournalNode 节点提出了新的要求,它需要保证自己的可靠性,才能保证为 Standby 节点提供数据。因此 JournalNode 节点本身也是一个多节点的集群,从而保证它自身的可靠性。而且 JournalNode 节点会在集群自动的选择一个"主"节点出来,Active 节点会和 JournalNode 的主节点通信,然后 JournalNode 集群的主节点会将数据发送给其他的节点,只要有过半的节点完成了数据的存储,JournalNode 集群的主节点,就会将成功信息返回给 Active 节点。当 JournalNode 集群的主节点挂掉,其他的 JournalNode 节点会快速选举出新的"主"节点来。
这样,通过 JournalNode 通过自身具备存储能力,和保证自身的可靠性,为 Active 节点和 Standby 节点之间的数据最终一致性提供了服务。
四、HDFS HA 模式架构图
HDFS HA 模式集群的架构图如下所示。
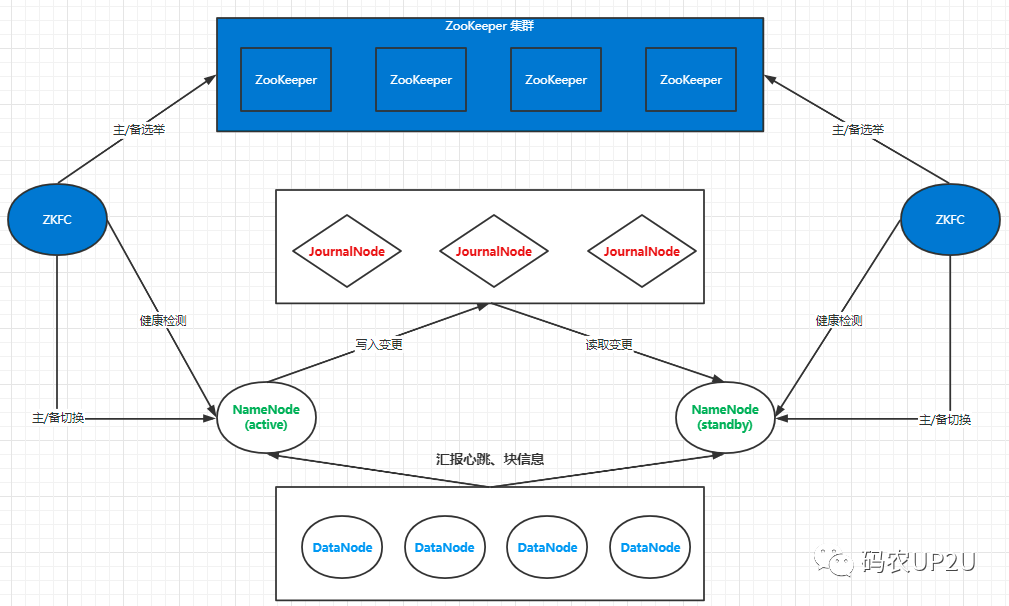
在上图中,蓝色部分是用于故障自动切换的,除蓝色部分外,则是 HDFS HA 模式的集群。在最下方是 DataNode 节点,在 DataNode 节点的上方左右两侧各一个的是处于 Active 状态的 NameNode 节点,和处于 Standby 状态的 NameNode 节点。在 NameNode 节点的上面则是 JournalNode 的集群。这样就保障了整个 HDFS 集群系统的高可用。
五、总结
分布式架构中保证数据的一致性是一个比较关键的问题,分布式一致性也有相关的协议,比如 Paxos 协议。虽然不同的技术使用了不同协议,只是各种技术在具体实现时的综合取舍。

公众号内回复 【mongo】 下载 SpringBoot 整合操作 MongoDB 的文档。
之前整理的关于 Redis 的文章: