
Hudi 实践 | 如何将数据更快导入 Apache Hudi?

1. 摘要
Apache Hudi除了支持insert和upsert外,还支持bulk_insert操作将数据摄入Hudi表,对于bulk_insert操作有不同的使用模式,本篇博客将阐述bulk_insert不同的模式以及与其他操作的比较。
Apache Hudi支持bulk_insert操作来将数据初始化至Hudi表中,该操作相比insert和upsert操作速度更快,效率更高。bulk_insert不会查看已存在数据的开销并且不会进行小文件优化。
bulk_insert按照以下原则提供了3种模式来满足不同的需求
•如果数据布局良好,排序将为我们提供良好的压缩和upsert性能。特别是记录键具有某种排序(时间戳等)特征,则排序将有助于在upsert期间裁剪大量文件,如果数据是按频繁查询的列排序的,那么查询将利用parquet谓词下推来裁剪数据,以确保更低的查询延迟。•写parquet文件是内存密集型操作。当将大量数据写入一个也被划分为1000个分区的表中时,如果不进行任何排序,写入程序可能必须保持1000个parquet写入器处于打开状态,同时会产生不可持续的内存压力,并最终导致崩溃。
•在批量导入数据时,最好控制好少的文件个数,以避免以后写入和查询时的元数据开销。
3种开箱即用的模式为:PARTITION_SORT、GLOBAL_SORT、NONE
2. 配置
可以通过hoodie.bulkinsert.sort.mode[1]配置项来设置上述模式(NONE, GLOBAL_SORT , PARTITION_SORT),默认值为GLOBAL_SORT。
3. 不同模式
3.1 GLOBAL_SORT(全局排序)
顾名思义,Hudi在输入分区中对记录进行全局排序,从而在索引查找过程中最大化使用键范围修剪的文件数量,以便提升upsert性能。这是因为每个文件都具有非重叠的键的最小值和最大值,这在键具有某些排序特征(例如基于时间的前缀)时非常有用。假设我们在任何给定的时间都在单个输出分区路径上写入单个parquet文件,此模式在大分区写入期间有助于控制内存压力。同样由于全局排序,每个小表分区路径将从最多有两个分区写入,因此只包含2个文件。该模式是Hudi中进行bulk_insert操作的默认模式。
3.2 PARTITION_SORT(分区排序)
在这种排序模式下将对给定spark分区内的记录进行排序,但是给定的spark分区可能包含来自不同表分区的记录,因此即使我们在每个spark分区内进行排序,也可能会在产生大量文件,因为给定表分区的记录可能会分布在许多spark分区中。在写入器实际写入时可能不会同时打开太多文件,因为我们在移动到下一个文件之前关闭了该文件(记录在spark分区中排序),因此可能没有太大的内存压力。
3.3 NONE
在此模式下,不会对用户记录进行任何转换(如排序),将数据原样委托给写入器。因此在将大量数据写入分区为1000个分区的表中时,写入程序可能必须保持1000个parquet写入程序处于打开状态,同时可能会产生较大内存压力,有可能导致崩溃,因此该模式下会有较大的内存开销。此外给定文件的最小-最大范围可能非常宽(未排序的记录),因此后续的upsert会在索引查找期间从大量文件中读取bloom filter(布隆过滤器)。由于记录没有排序,并且每个写入器可以跨N个表分区获取记录,因此这种模式可能会导致在bulk_insert结束时产生大量文件。由于有大量的小文件,这也可能会影响upsert或查询性能。
4. 用户自定义Partitioner
如果上述模式都不能满足需求,用户可以自定义实现partitioner[2]来满足业务需求。
5. 性能测试
不同模式下简单benchmark性能差异如下
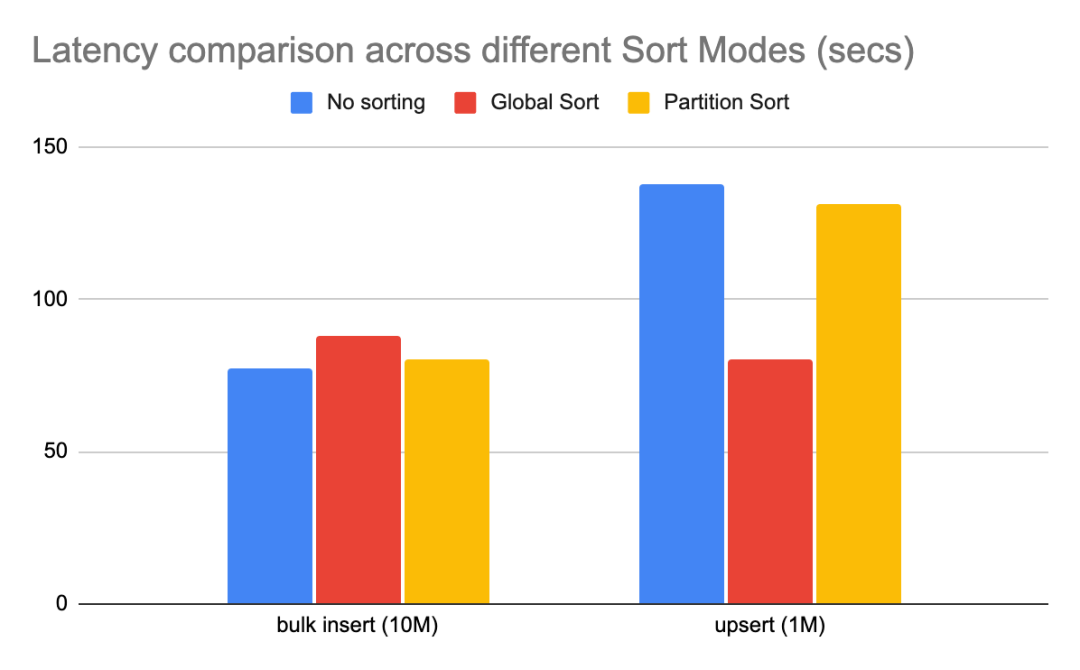
说明:该基准测试使用不同的排序模式将1000万条记录批量插入hudi,然后
upsert100W个条记录(原始数据集大小的10%)。
显而易见,NONE模式对批量导入性能最佳,因为它不涉及任何排序。与NONE模式相比,GLOBAL_SORT相比NONE模式开销约为15%。PARTITION_SORT相比NONE模式开销约为4%,因为也涉及到对记录的排序操作。但是要注意的是后面的upsert性能。如前所述,与其他两种排序模式相比全局排序具有许多优势,GLOBAL_SORT相比NONE upsert性能高40%。PARTITION_SORT相比NONE模式有约5%的改进,这是由于大量小文件开销导致。
6. 总结
希望这个博客能让你很好地了解bulk_insert中的不同模式以及何时使用哪种模式。如果想参与Hudi社区,请点击这里[3]。
推荐阅读
内附PPT下载|万字干货!阿里云基于Apache Hudi构建Lakehouse实践探索
一文彻底掌握Apache Hudi异步Clustering部署
引用链接
[1] hoodie.bulkinsert.sort.mode: https://hudi.apache.org/docs/configurations.html#withBulkInsertSortMode[2] partitioner: https://github.com/apache/hudi/blob/master/hudi-client/hudi-client-common/src/main/java/org/apache/hudi/table/BulkInsertPartitioner.java[3] 这里: https://hudi.apache.org/contribute/get-involved