
可视化高维数据:T-SNE
地址:https://zhuanlan.zhihu.com/p/99469215
Google Tech Talk June 24, 2013 (more info below)
Presented by Laurens van der Maaten, Delft University of Technology, The Netherlands
视频:
论文:
https://www.jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf
Laurens van der Maaten & Geoffrey Hinton
01
 ,那应该如何去直观感受数据组织?
,那应该如何去直观感受数据组织?如果是关注过可视化领域的,通常会想到Parallel coordinates、radial graph layout或是tree maps:
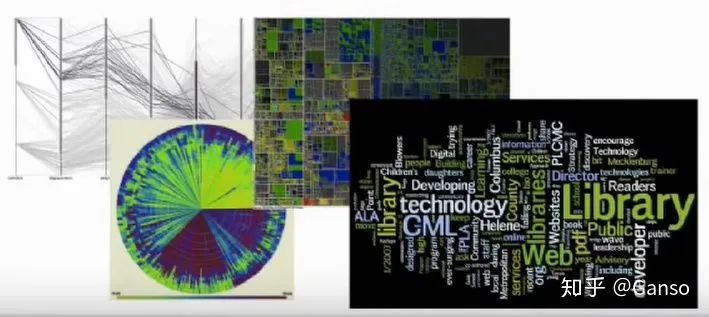
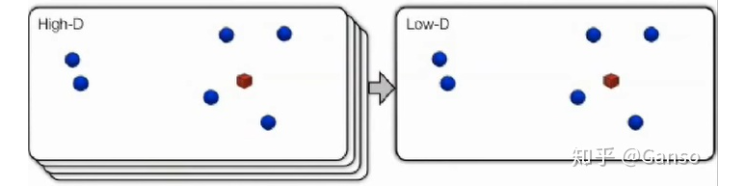
通常将这类方法称为:dimension reduction(维度降低)、embedding(嵌入)或multidimensional scaling(多维度缩放)。
02
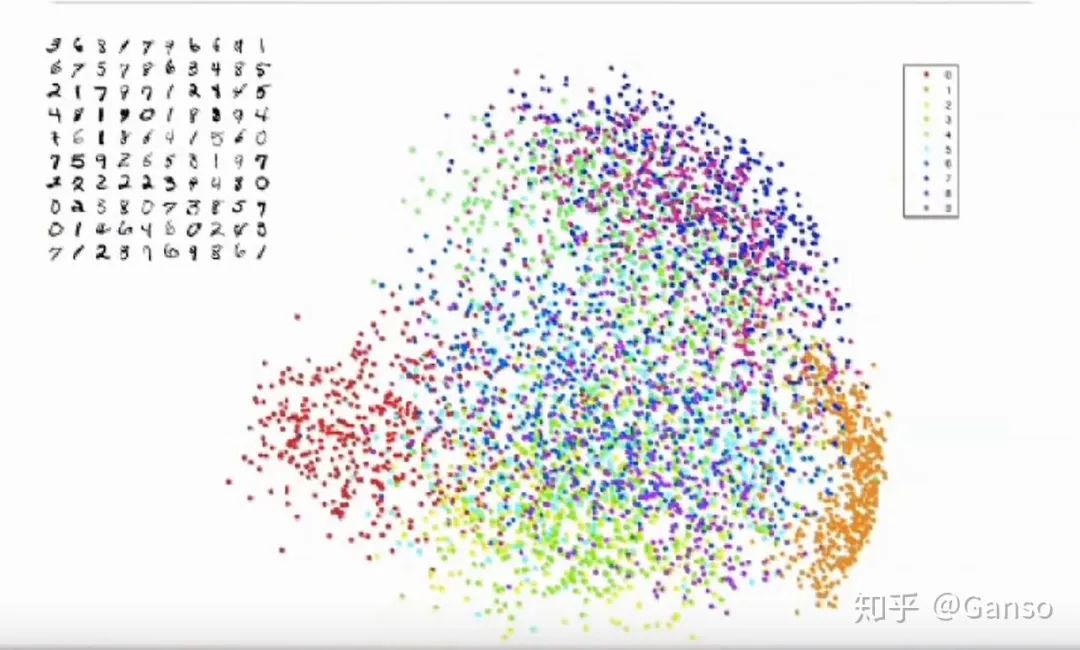
左边红色的部分是数字0,而右边橙色的部分是1,可以看到之间有很大间隔。
其他的主成成分构成是上方的479,以及下方的358
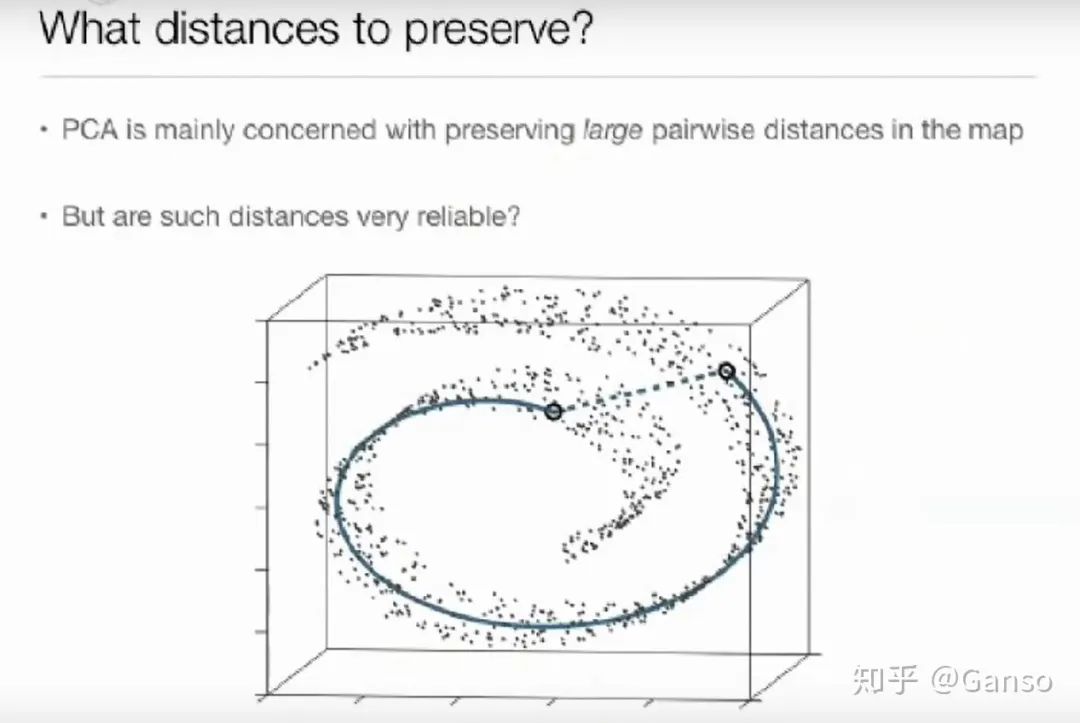
03
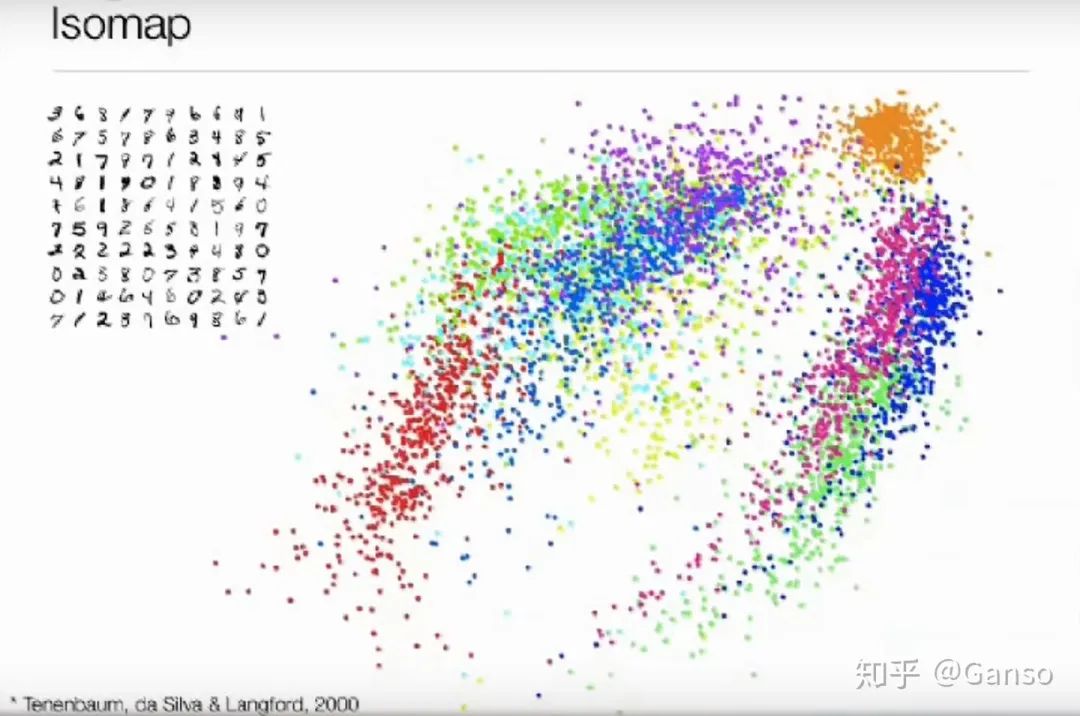
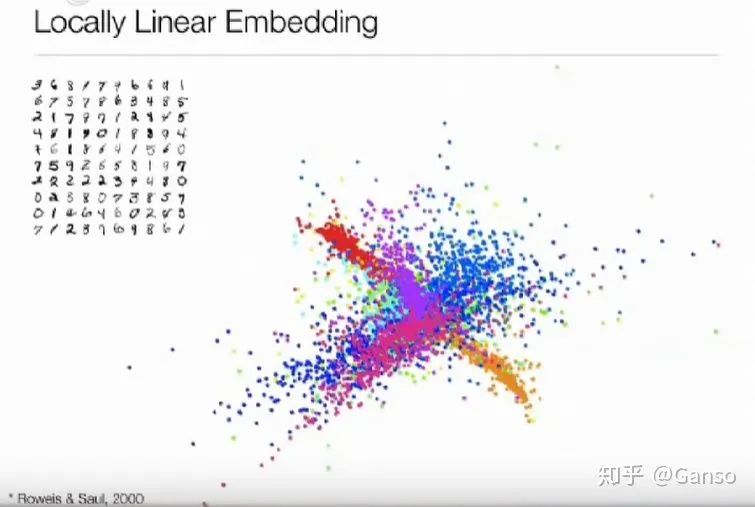
04

 是i与j的相似程度。
是i与j的相似程度。
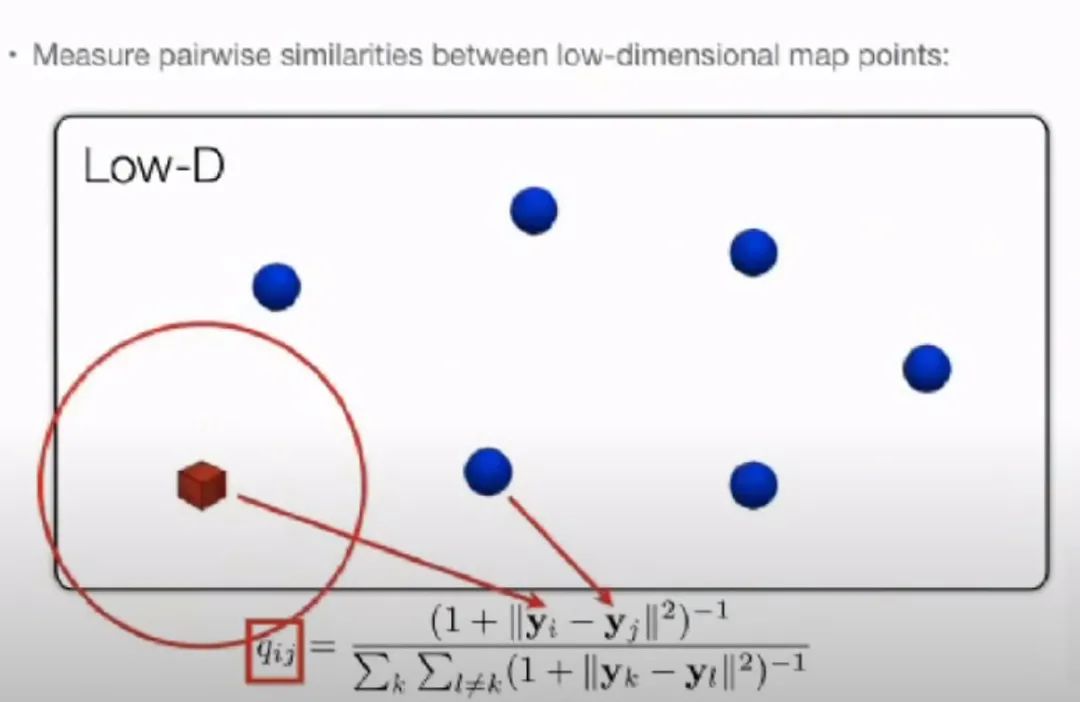
 能够一定程度上反映高维情况下的相似度 。如果与的结果很像,那么说明映射的结构与原始高维数据结构很相近。
能够一定程度上反映高维情况下的相似度 。如果与的结果很像,那么说明映射的结构与原始高维数据结构很相近。 与的差距很大,惩罚项也会很大。
与的差距很大,惩罚项也会很大。



05
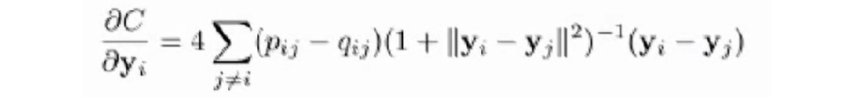
梯度公式

 ,最后一项是表示其他点指向此点的向量
,最后一项是表示其他点指向此点的向量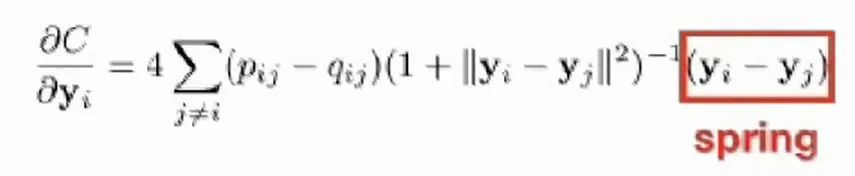
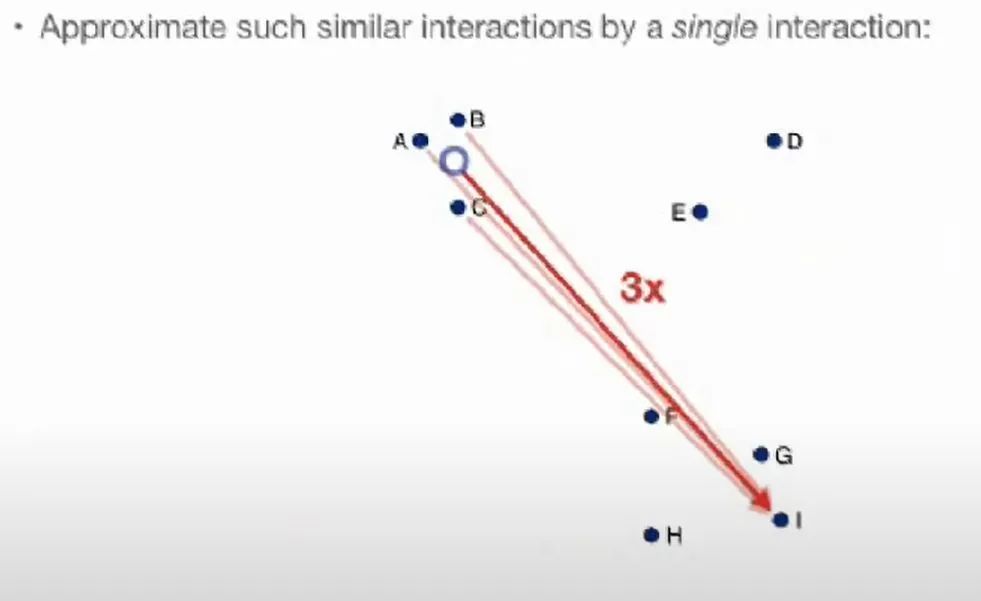
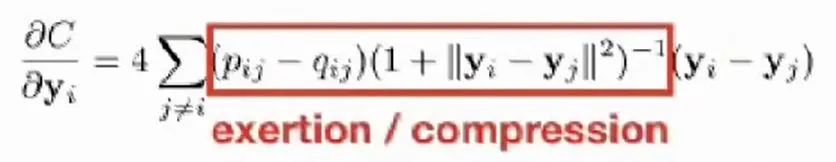 与 很相近时,也就是我们的目标,相当于不用改动位置了,梯度也很接近0.
与 很相近时,也就是我们的目标,相当于不用改动位置了,梯度也很接近0.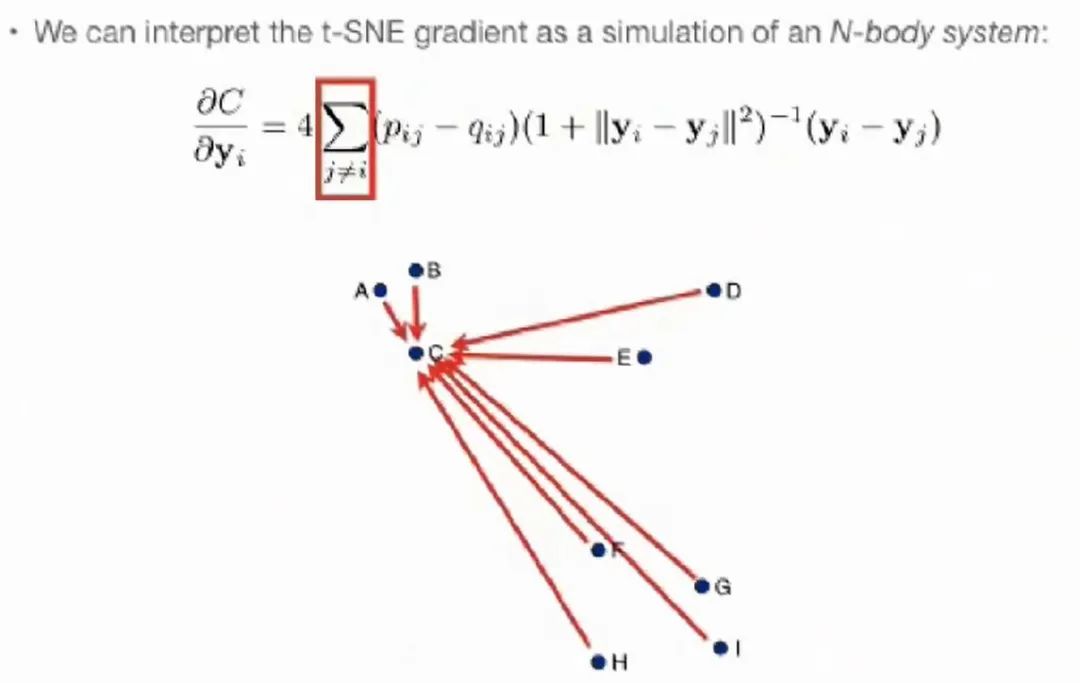
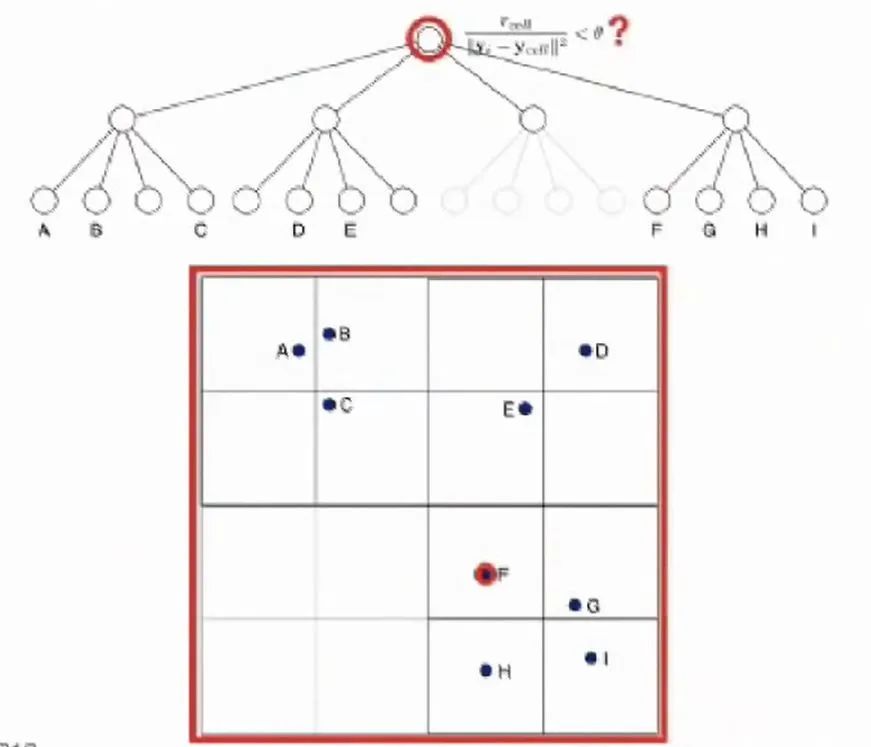
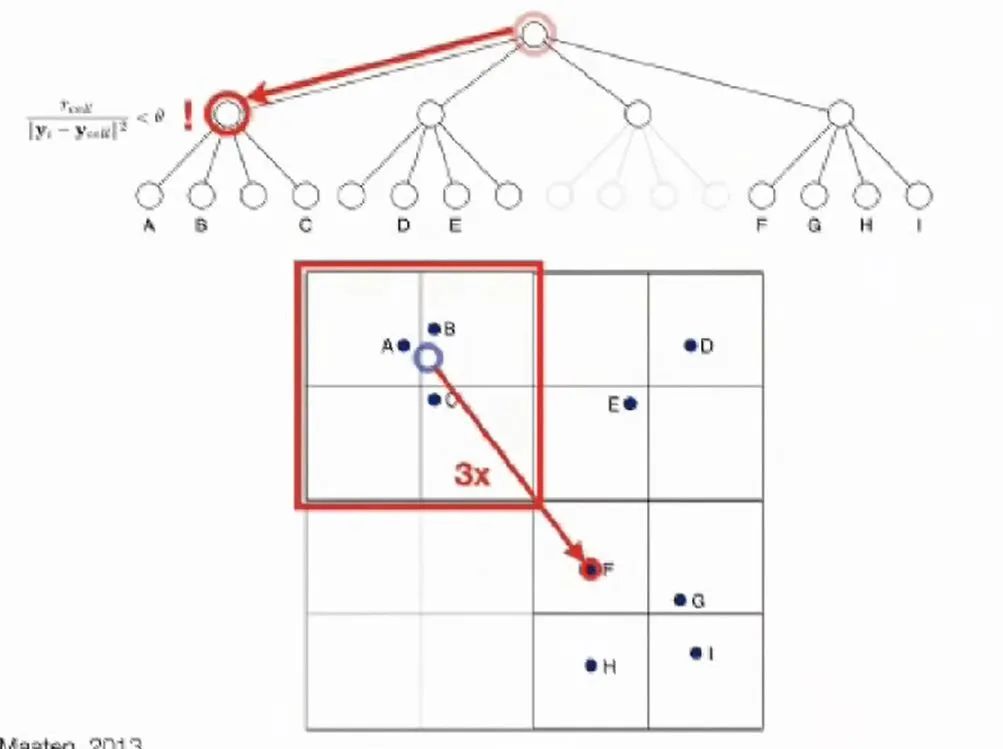
06
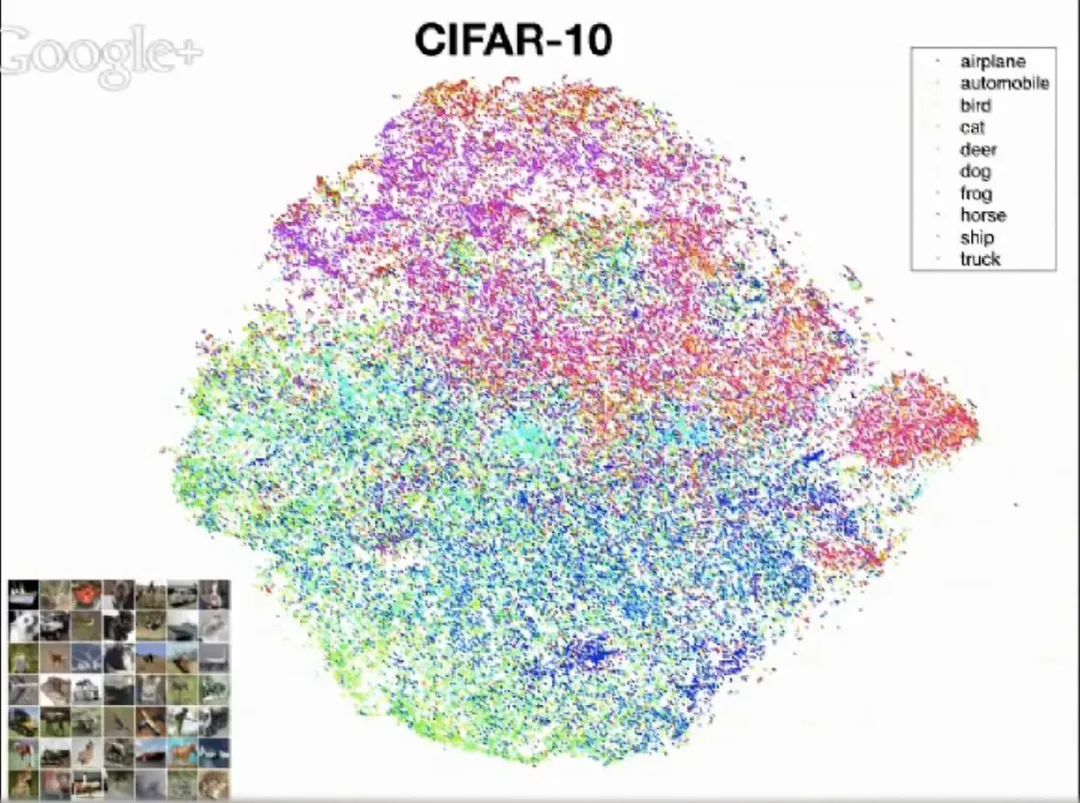
07
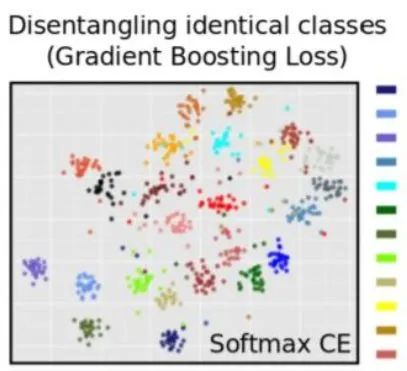
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
评论