
用 Java 写了一个搜索引擎系统,这个太强了!!
来源:https://blog.csdn.net/m0_57315623
前言
咱们如果用我们的小服务器去搞百度,搜狗那种引擎肯定是不行的,内属于全站搜索,我们这里做一个站内搜索。这个还是可以的,就类似于我们对网站里的资源进行搜索。
一.搜索引擎怎么搜索
搜索引擎就像一个小蜜蜂每天不停的采摘蜂蜜,就是去爬虫各个网页,然后通过爬取之后建立索引,以供于我们去搜索。
这里我们可以使用Python,或者下载文档压缩包。这里我们下包把,快多了。本来想搞一个英雄联盟的,实在找不见,要是后续有老铁找到可以分享一下。
建议大家别爬虫(要不然被告了,不过我们学校的官网倒是可以随便爬,我们当时就是拿这个练手的) 为什么要用索引呢?
因为爬的数据太多了,不索引,难道我去遍历吗?时间复杂度太大了。
拿LOL举个例子吧,正排就相当于,我们提到无极剑圣的技能就可以联想到:
二.模块划分
1.索引模块
1)扫描下载到的文档,分析内容,构建出,正排索引和倒排索引。并且把索引内容保存到文件中。
2)加载制作i好的索引。并提供一些API实现查正排和查倒排这样的功能。
2.搜索模块
1)调用索引模块,实现一个搜索的完整过程。
输入:用户的查询词 输出:完整的搜索结果
3.web模块
需要实现一个简单的web程序,能够通过网页的形式和用户进行交互。包含了前端和后端。
三. 怎么实现分词
分词的原理:
1.基于词库
尝试把所有的词都进行穷举,把这些结果放到词典文件中。
2.基于统计
收集到很多的语料库,进行人工标注,知道了那些字在一起的概率比较大~
java中能够实现分词的第三方工具也是有很多的
比如ansj(听说唱的兄弟可能听过ansj,哈哈)这个就是一个maven中央仓库的分词第三方库。最新面试题整理好了,点击Java面试库小程序在线刷题。
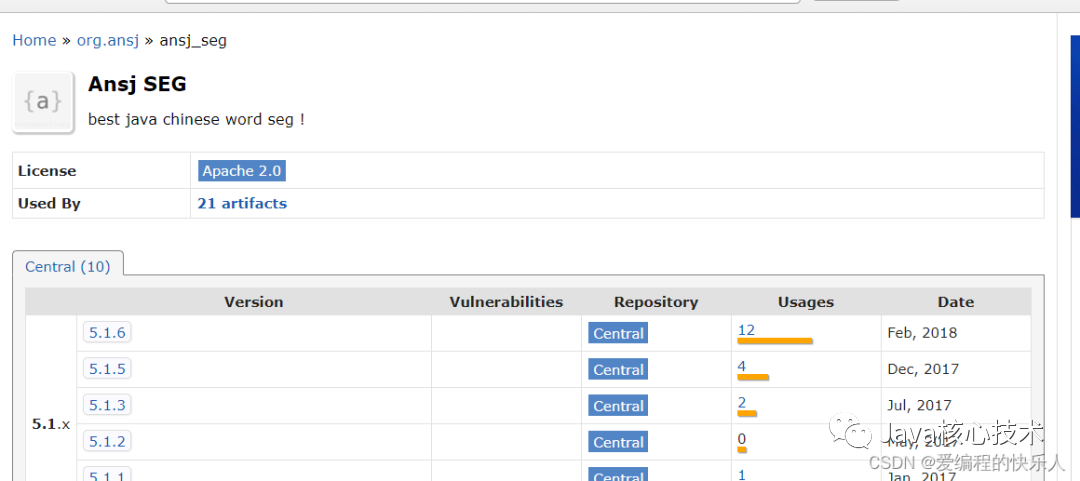
我们直接下载最新版本然后放入pom.xml里面
test包里直接操作:我们使用这个测试代码直接搞。试一下这个包咋用。
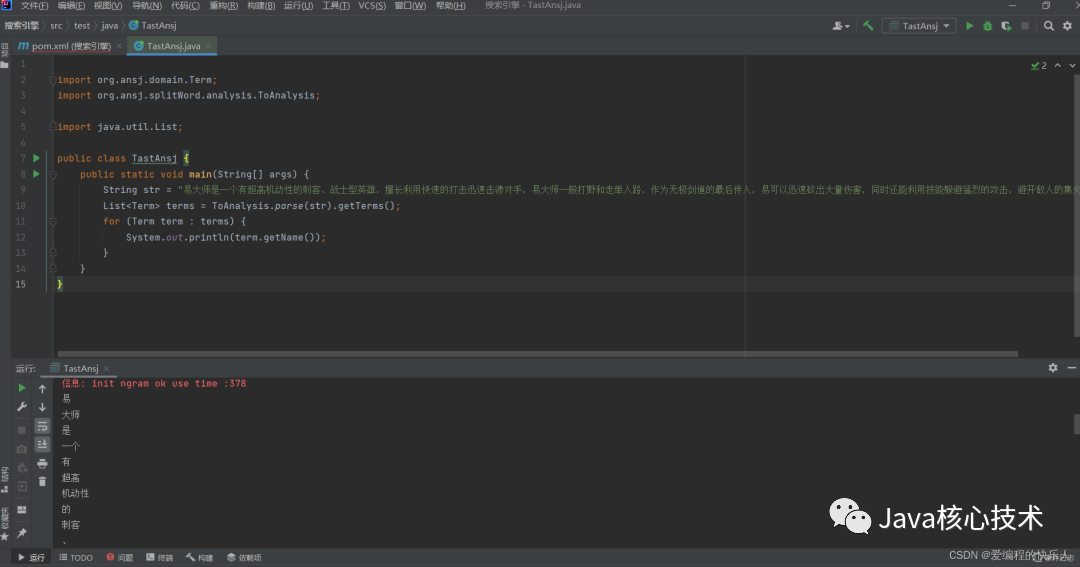
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.ToAnalysis;
import java.util.List;
public class TastAnsj {
public static void main(String[] args) {
String str = "易大师是一个有超高机动性的刺客、战士型英雄,擅长利用快速的打击迅速击溃对手,易大师一般打野和走单人路,作为无极剑道的最后传人,易可以迅速砍出大量伤害,同时还能利用技能躲避猛烈的攻击,避开敌人的集火。";
List terms = ToAnalysis.parse(str).getTerms();
for (Term term : terms) {
System.out.println(term.getName());
}
}
}
四.文件读取
把刚刚下载好的文档的路径复制到String中并且用常量标记。
这一步是为了用遍历的方法把所有html文件搞出来,我们这里用了一个递归,如果是绝对路径,就填加到文件链表,如果不是就递归,继续添加里面的值。
import java.io.File;
import java.util.ArrayList;
//读取刚刚文档
public class Parser {
private static final String INPUT_PATH="D:/test/docs/api";
public void run(){
//整个Parser类的入口
//1.根据路径,去枚举出所有的文件.(html);
ArrayList fileList=new ArrayList<>();
enumFile(INPUT_PATH,fileList);
System.out.println(fileList);
System.out.println(fileList.size());
//2.针对上面罗列出的文件,打开文件,读取文件内容,并进行解析
//3.把在内存中构造好的索引数据结构,保定到指定的文件中。
}
//第一个参数表示从哪里开始遍历 //第二个表示结果。
private void enumFile(String inputPath,ArrayListfileList){
File rootPath=new File(inputPath);
//listFiles 能够获取到一层目录下的文件
File[] files= rootPath.listFiles();
for(File f:files){
//根据当前f的类型判断是否递归。
//如果f是一个普通文件,就把f加入到fileList里面
//如果不是就调用递归
if(f.isDirectory()){
enumFile(f.getAbsolutePath(),fileList);
}else {
fileList.add(f);
}
}
}
public static void main(String[] args) {
//通过main方法来实现整个制作索引的过程
Parser parser=new Parser();
parser.run();
}
}
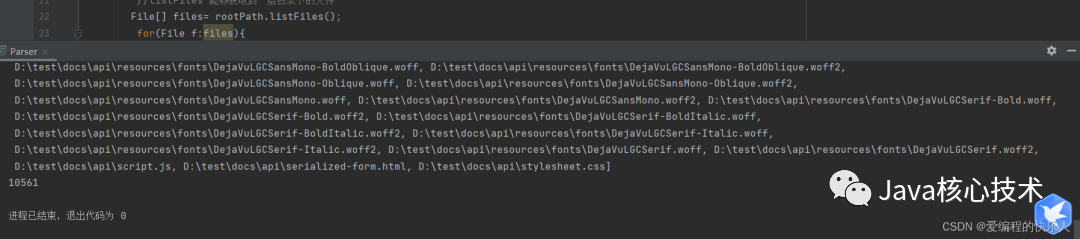
我们尝试运行一下,这里的文件也太多了吧,而且无论是什么都打印出来了。所以我们下一步就是把这些文件进行筛选,选择有用的。最新面试题整理好了,点击Java面试库小程序在线刷题。
else {
if(f.getAbsolutePath().endsWith(",html"))
fileList.add(f);
}
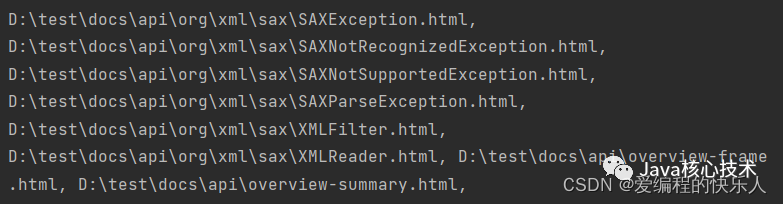
这个代码就是只是针对末尾为html的文件。下图就是展示结果。
4.1 打开文件,解析内容。
这里分为三个分别是解析Title,解析Url,解析内容Content。关注Java核心技术,推送更多 Java 干货!
4.1.1解析Title
'){ isCopy=true; } } } return content.toString(); } catch (FileNotFoundException e) { e.printStackTrace(); } return ''; }这一模块总的代码块如下:" linktype="text" imgurl="" imgdata="null" data-itemshowtype="0" tab="innerlink" data-linktype="2">private String parseTitle(File f) {
String name= f.getName();
return name.substring(0,f.getName().length()-5);
}
4.1.2解析Url操作
'){ isCopy=true; } } } return content.toString(); } catch (FileNotFoundException e) { e.printStackTrace(); } return ''; }这一模块总的代码块如下:" linktype="text" imgurl="" imgdata="null" data-itemshowtype="0" tab="innerlink" data-linktype="2">private String parseUrl(File f) {
String part1="https://docs.oracle.com/javase/8/docs/api/";
String part2=f.getAbsolutePath().substring(INPUT_PATH.length());
return part1+part2;
}
4.1.3解析内容
'){ isCopy=true; } } } return content.toString(); } catch (FileNotFoundException e) { e.printStackTrace(); } return ''; }这一模块总的代码块如下:" linktype="text" imgurl="" imgdata="null" data-itemshowtype="0" tab="innerlink" data-linktype="2">private String parseContent(File f) throws IOException {
//先按照一个一个字符来读取,以<>作为开关
try(FileReader fileReader=new FileReader(f)) {
//加上一个是否拷贝的开关.
boolean isCopy=true;
//还需要准备一个结果保存
StringBuilder content=new StringBuilder();
while (true){
//此处的read的返回值是int,不是char
//如果读到文件末尾,就会返回-1,这是用int的好处;
int ret = 0;
try {
ret = fileReader.read();
} catch (IOException e) {
e.printStackTrace();
}
if(ret==-1) {
break;
}
char c=(char) ret;
if(isCopy){
if(c=='<'){
isCopy=false;
continue;
}
//其他字符直接拷贝
if(c=='\n'||c=='\r'){
c=' ';
}
content.append(c);
}else{
if(c=='>'){
isCopy=true;
}
}
}
return content.toString();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
return "";
}
这一模块总的代码块如下:
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
//读取刚刚文档
public class Parser {
private static final String INPUT_PATH="D:/test/docs/api";
public void run(){
//整个Parser类的入口
//1.根据路径,去枚举出所有的文件.(html);
ArrayList fileList=new ArrayList<>();
enumFile(INPUT_PATH,fileList);
System.out.println(fileList);
System.out.println(fileList.size());
//2.针对上面罗列出的文件,打开文件,读取文件内容,并进行解析
for (File f:fileList){
System.out.println("开始解析"+f.getAbsolutePath());
parseHTML(f);
}
//3.把在内存中构造好的索引数据结构,保定到指定的文件中。
}
private String parseTitle(File f) {
String name= f.getName();
return name.substring(0,f.getName().length()-5);
}
private String parseUrl(File f) {
String part1="https://docs.oracle.com/javase/8/docs/api/";
String part2=f.getAbsolutePath().substring(INPUT_PATH.length());
return part1+part2;
}
private String parseContent(File f) throws IOException {
//先按照一个一个字符来读取,以<>作为开关
try(FileReader fileReader=new FileReader(f)) {
//加上一个是否拷贝的开关.
boolean isCopy=true;
//还需要准备一个结果保存
StringBuilder content=new StringBuilder();
while (true){
//此处的read的返回值是int,不是char
//如果读到文件末尾,就会返回-1,这是用int的好处;
int ret = 0;
try {
ret = fileReader.read();
} catch (IOException e) {
e.printStackTrace();
}
if(ret==-1) {
break;
}
char c=(char) ret;
if(isCopy){
if(c=='<'){
isCopy=false;
continue;
}
//其他字符直接拷贝
if(c=='\n'||c=='\r'){
c=' ';
}
content.append(c);
}else{
if(c=='>'){
isCopy=true;
}
}
}
return content.toString();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
return "";
}
private void parseHTML (File f){
//解析出标题
String title=parseTitle(f);
//解析出对应的url
String url=parseUrl(f);
//解析出对应的正文
try {
String content=parseContent(f);
} catch (IOException e) {
e.printStackTrace();
}
}
//第一个参数表示从哪里开始遍历 //第二个表示结果。
private void enumFile(String inputPath,ArrayListfileList){
File rootPath=new File(inputPath);
//listFiles 能够获取到一层目录下的文件
File[] files= rootPath.listFiles();
for(File f:files){
//根据当前f的类型判断是否递归。
//如果f是一个普通文件,就把f加入到fileList里面
//如果不是就调用递归
if(f.isDirectory()){
enumFile(f.getAbsolutePath(),fileList);
}else {
if(f.getAbsolutePath().endsWith(".html"))
fileList.add(f);
}
}
}
public static void main(String[] args) {
//通过main方法来实现整个制作索引的过程
Parser parser=new Parser();
parser.run();
}
}
END
推荐阅读
END
一键生成Springboot & Vue项目!【毕设神器】
Java可视化编程工具系列(一)
Java可视化编程工具系列(二)
顺便给大家推荐一个GitHub项目,这个 GitHub 整理了上千本常用技术PDF,绝大部分核心的技术书籍都可以在这里找到,
GitHub地址:https://github.com/javadevbooks/books
电子书已经更新好了,你们需要的可以自行下载了,记得点一个star,持续更新中..

顺便给大家推荐一个GitHub项目,这个 GitHub 整理了上千本常用技术PDF,绝大部分核心的技术书籍都可以在这里找到,
GitHub地址:https://github.com/javadevbooks/books
电子书已经更新好了,你们需要的可以自行下载了,记得点一个star,持续更新中..