
【Elastic】ES重建索引怎么才能做到数据无缝迁移呢?
背景
众所周知,Elasticsearch是⼀个实时的分布式搜索引擎,为⽤户提供搜索服务。当我们决定存储某种数据,在创建索引的时候就需要将数据结构,即Mapping确定下来,于此同时索引的设定和很多固定配置将不能改变。那如果后续业务发生变化,需要改变数据结构或者更换ES更换分词器怎么办呢?为此,Elastic团队提供了很多通过辅助⼯具来帮助开发⼈员进⾏重建索引的方案。如果对 reindex API 不熟悉,那么在遇到重构的时候,必然事倍功半,效率低下。反之,就可以方便地进行索引重构,省时省力。
步骤
假设之前我们已经存在一个blog索引,因为更换分词器需要对该索引中的数据进行重建索引,以便支持业务使用新的分词规则搜索数据,并且尽可能使这个变化对外服务没有感知,大概分为以下几个步骤:
新增⼀个索引 blog_lastest,Mapping数据结构与blog索引一致将 blog数据同步至blog_lastest删除 blog索引数据同步后给 blog_lastest添加别名blog
新建索引
在这里推荐一个ES管理工具Kibana,主要针对数据的探索、可视化和分析。
put /blog_lastest/
{
"mappings":{
"properties":{
"title":{
"type":"text",
"analyzer":"ik_max_word"
},
"author":{
"type":"keyword",
"fields":{
"seg":{
"type":"text",
"analyzer":"ik_max_word"
}
}
}
}
}
}
将旧索引数据copy到新索引
同步等待
接⼝将会在 reindex 成功结束后返回
POST /_reindex
{
"source": {
"index": "blog"
},
"dest": {
"index": "blog_lastest"
}
}
在 kibana 中的使用如下所示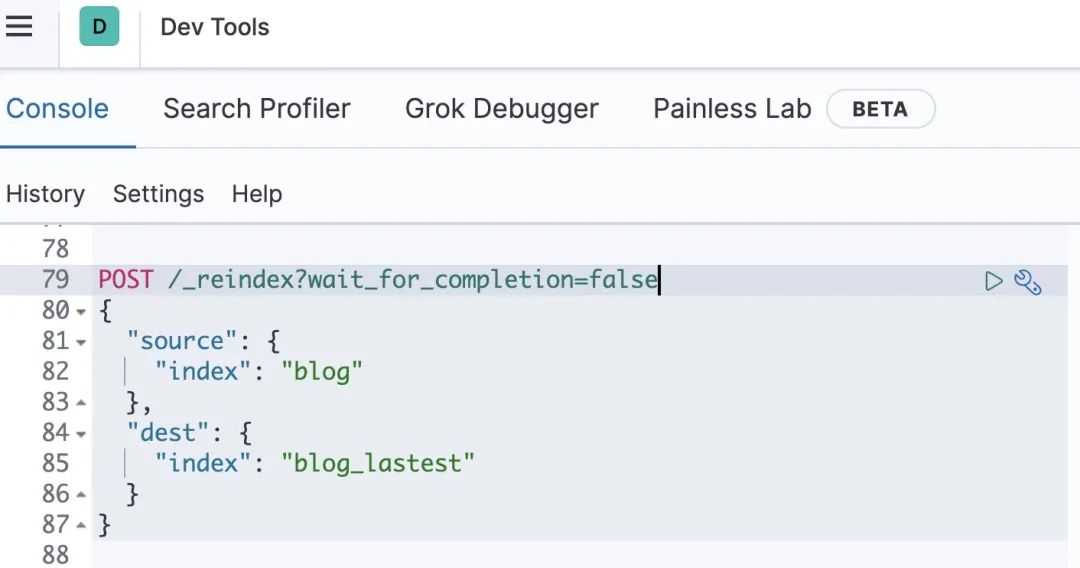
当然高版本(7.1.1)中,ES都有提供对应的Java REST Client,比如
ReindexRequest reindexRequest = new ReindexRequest();
reindexRequest.setSourceIndices("blog").setSource.setDestIndex("blog_lastest");
TaskSubmissionResponse taskSubmissionResponse = client.submitReindexTask(reindexRequest, RequestOptions.DEFAULT);
为了防止赘述,接下来举例全部以kibana中请求介绍,如果有需要用Java REST Client,可以自行去ES官网查看。
异步执⾏
如果 reindex 时间过⻓,建议加上 wait_for_completion=false 的参数条件,这样 reindex 将直接返回 taskId。
POST /_reindex?wait_for_completion=false
{
"source": {
"index": "blog"
},
"dest": {
"index": "blog_lastest"
}
}
返回:
{
"task" : "dpBihNSMQfSlboMGlTgCBA:4728038"
}
op_type 参数
op_type 参数控制着写入数据的冲突处理方式,如果把 op_type 设置为 create【默认值】,在 _reindex API 中,表示写入时只在 dest index中添加不存在的 doucment,如果相同的 document 已经存在,则会报 version confilct 的错误,那么索引操作就会失败。【这种方式与使用 _create API 时效果一致】
POST _reindex
{
"source": {
"index": "blog"
},
"dest": {
"index": "blog_lastest",
"op_type": "create"
}
}
如果这样设置了,也就不存在更新数据的场景了【冲突数据无法写入】,我们也可以把 op_type 设置为 index,表示所有的数据全部重新索引创建。
conflicts 配置
默认情况下,当发生 version conflict 的时候,_reindex 会被 abort,任务终止【此时数据还没有 reindex 完成】,在返回体中的 failures 指标中会包含冲突的数据【有时候数据会非常多】,除非把 conflicts 设置为 proceed。
关于 abort 的说明,如果产生了 abort,已经执行的数据【例如更新写入的】仍然存在于目标索引,此时任务终止,还会有数据没有被执行,也就是漏数了。换句话说,该执行过程不会回滚,只会终止。如果设置了 proceed,任务在检测到数据冲突的情况下,不会终止,会跳过冲突数据继续执行,直到所有数据执行完成,此时不会漏掉正常的数据,只会漏掉有冲突的数据。
POST _reindex
{
"source": {
"index": "blog"
},
"dest": {
"index": "blog_lastest",
"op_type": "create"
},
"conflicts": "proceed"
}
我们可以故意把 op_type 设置为 create,人为制造数据冲突的场景,测试时更容易观察到冲突现象。
如果把 conflicts 设置为 proceed,在返回体结果中不会再出现 failures 的信息,但是通过 version_conflicts 指标可以看到具体的数量。
批次大小配置
当你发现reindex的速度有些慢的时候,可以在 query 参数的同一层次【即 source 参数中】添加 size 参数,表示 scroll size 的大小【会影响批次的次数,进而影响整体的速度】,如果不显式设置,默认是一批 1000 条数据,在一开始的简单示例中也看到了。如下,设置 scroll size 为 5000:
POST /_reindex?wait_for_completion=false
{
"source": {
"index": "blog",
"size":5000
},
"dest": {
"index": "blog_lastest",
"op_type": "create"
},
"conflicts": "proceed"
}
测试后,速度达到了 30 分钟 500 万左右,明显提升了很多。
根据taskId可以实时查看任务的执行状态
一般来说,如果我们的 source index 很大【比如几百万数据量】,则可能需要比较长的时间来完成 _reindex 的工作,可能需要几十分钟。而在此期间不可能一直等待结果返回,可以去做其它事情,如果中途需要查看进度,可以通过 _tasks API 进行查看。
GET /_tasks/{taskId}
返回:
{
"completed" : false,
"task" : {
"node" : "dpBihNSMQfSlboMGlTgCBA",
"id" : 4704218,
"type" : "transport",
"action" : "indices:data/write/reindex",
……
}
当执行完毕时,completed为true
查看任务进度以及取消任务,除了根据taskId查看以外,我们还可以通过查看所有的任务中筛选本次reindex的任务。
GET _tasks?detailed=true&actions=*reindex
返回结果:
{
"nodes" : {
"dpBihNSMQfSlboMGlTgCBA" : {
"name" : "node-16111-9210",
"transport_address" : "192.168.XXX.XXX:9310",
"host" : "192.168.XXX.XXX",
"ip" : "192.168.16.111:9310",
"roles" : [
"ingest",
"master"
],
"attributes" : {
"xpack.installed" : "true",
"transform.node" : "false"
},
"tasks" : {
"dpBihNSMQfSlboMGlTgCBA:6629305" : {
"node" : "dpBihNSMQfSlboMGlTgCBA",
"id" : 6629305,
"type" : "transport",
"action" : "indices:data/write/reindex",
"status" : {
"total" : 8361421,
"updated" : 0,
"created" : 254006,
"deleted" : 0,
"batches" : 743,
"version_conflicts" : 3455994,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0
},
"description" : "reindex from [blog] to [blog_lastest][_doc]",
"start_time_in_millis" : 1609338953464,
"running_time_in_nanos" : 1276738396689,
"cancellable" : true,
"headers" : { }
}
}
}
}
}
注意观察里面的几个重要指标,例如从 description 中可以看到任务描述,从 tasks 中可以找到任务的 id【例如 dpBihNSMQfSlboMGlTgCBA:6629305】,从 cancellable 可以判断任务是否支持取消操作。这个 API 其实就是模糊匹配,同理也可以查询其它类型的任务信息,例如使用 GET _tasks?detailed=true&actions=*byquery 查看查询请求的状态。当集群的任务太多时我们就可以根据task_id,也就是上面提到GET /_tasks/task_id 方式更加准确地查询指定任务的状态,避免集群的任务过多,不方便查看。如果遇到操作失误的场景,想取消任务,有没有办法呢?当然有啦,虽然覆水难收,通过调用_tasks API:
POST _tasks/task_id/_cancel
这里的 task_id 就是通过上面的查询任务接口获取的任务id(任务要支持取消操作,即【cancellable 为 true】时方能收效)。
删除旧索引
当我们通过 API 查询发现任务完成后,就可以进行后续操作,我这里是要删除旧索引,然后再给新索引起别名,用于替换旧索引,这样才能保证对外服务没有任何感知。
DELETE /blog
使用别名
POST /_aliases
{
"actions":[
{
"add":{
"index":"blog_lastest",
"alias":"blog"
}
}
]
}
通过别名访问新索引
进行过以上操作后,我们可以使用一个简单的搜索验证服务。
POST /blog/_search
{
"query": {
"match": {
"author": "james"
}
}
}
如果搜索结果达到我们的预期目标,至此,数据索引重建迁移完成。