
接口越权扫描平台初探

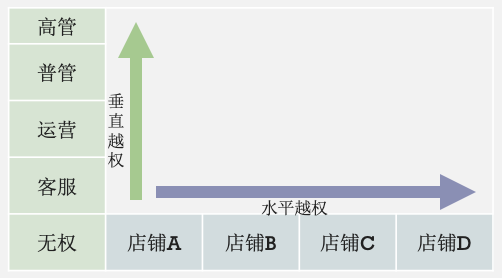
二、基本模型
使用一个正常的账号在页面上操作请求,比如登陆店铺A的员工账号,查询订单1 获取到了查询订单1的请求接口名称、参数以及返回 换一个账号,比如登陆店铺B的员工账号,调用下同一请求,对订单1再次进行查询(也可以直接用工具篡改原始请求的 cookie 替换为店铺 B 的再次进行请求,原理是一样的) 然后观察下此时返回的信息是否越权。如果店铺 B 的员工也获取到了订单1的信息,那么就存在越权的问题;如果报错没有权限,那么说明系统有针对性的做了权限检查。
获取到请求 准备多个账号 结果判断
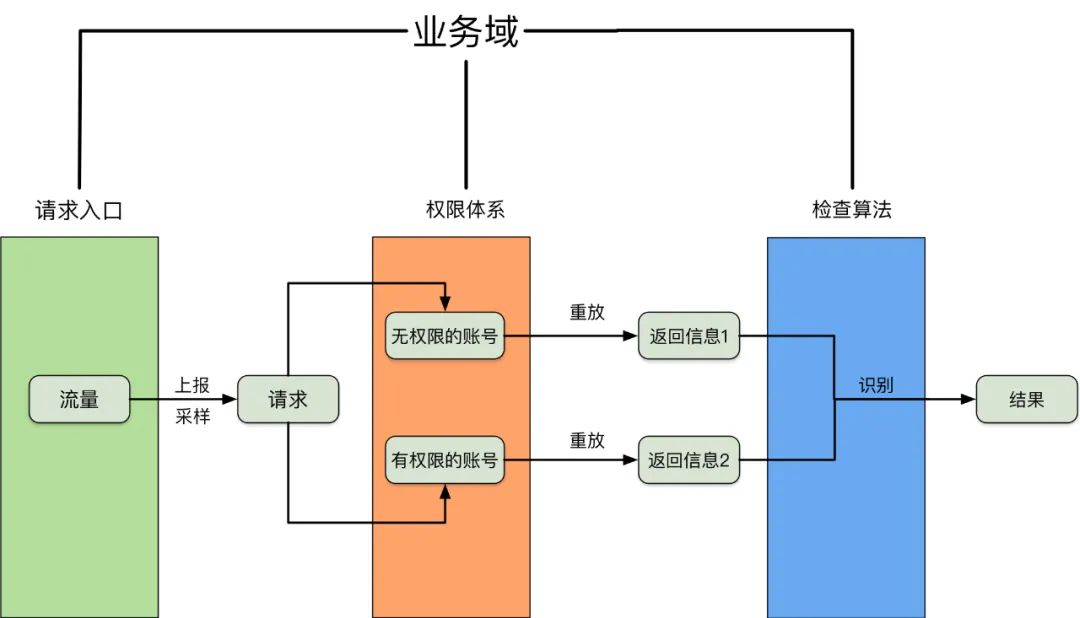
三、整体方案设计
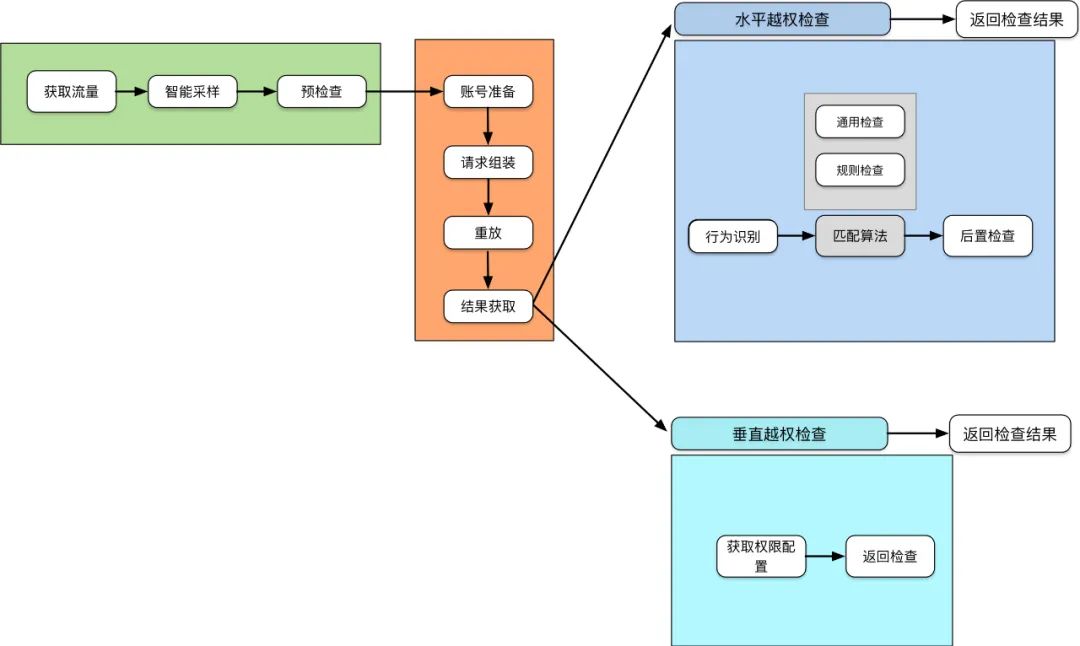
四、核心算法设计
从请求中能够获取到的信息很少,但是返回的结果又是各式各样的,判断是否越权,往往需要借助一些额外信息 对于越权的处理没有标准化,尤其在水平越权中这个现象比较严重:一些情况下代码对越权是做了单独校验,另一些是通过关联查询数据来做防御,在返回的表现上往往不一样。很多额外的工作量就是在识别各种没有标准化的返回上。
4.1 智能采样

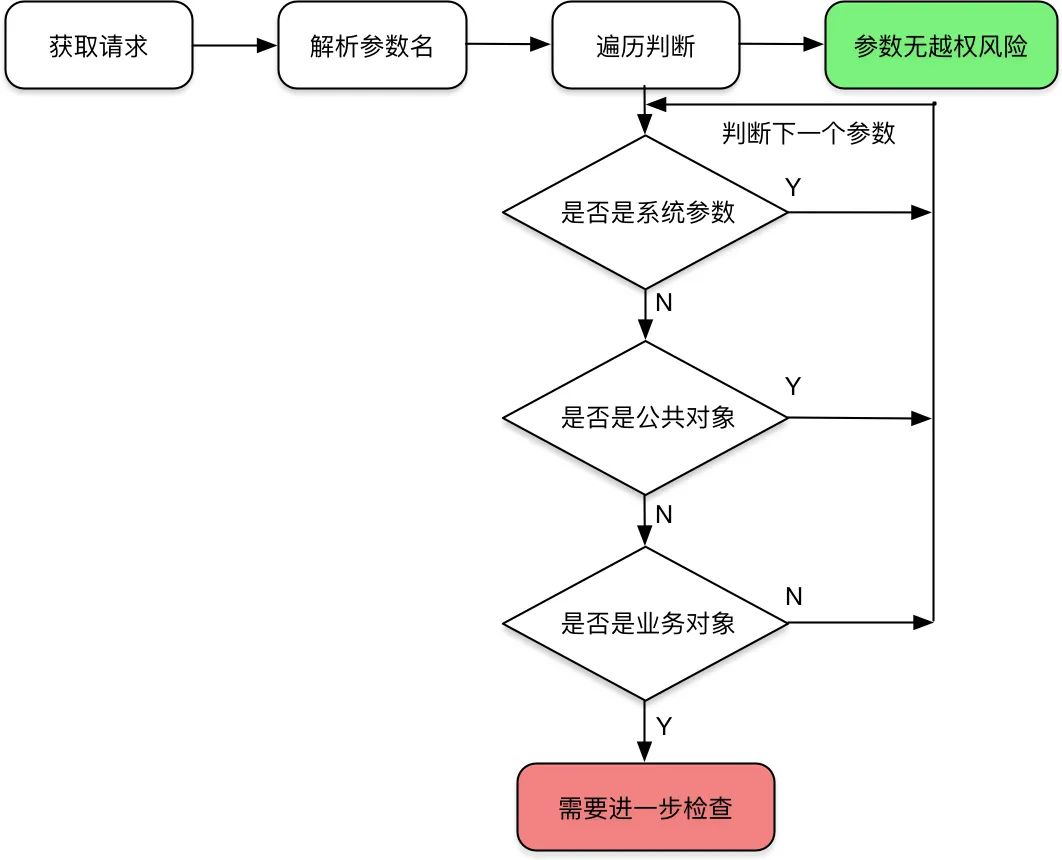
4.2 请求参数的越权风险判断
4.3 垂直越权检查
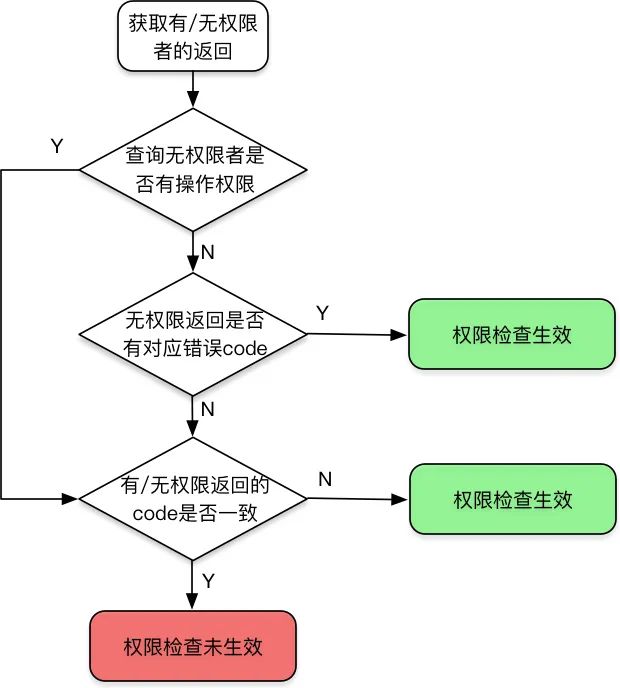

4.4 水平越权检查
4.4.1 行为识别
youzan.retail.finance.settlement.item.list.1.0.0,那么 item 往往标识了操作的对象,而 list 则标识了行为,所以从接口名可以大概推断出这个接口是做什么的。所以可以建立一个关键字的字典,通过字段的名字来匹配到属于哪一种行为。但是,有一部分接口并没有老老实实按这个规则进行命名,比如把行为在前,对象在后,或者行为的那个名字取的不是 query 而是 queryStatus 这样子的名字。所以在匹配的时候根据匹配的程度进行打分,全部匹配时分数较高,部分匹配时分数较低,根据接口名命中的字段和分数最后计算出属于读接口还是写接口。读操作的关键字字典为
["query","list","get"]写操作的关键字字典为
["create","delete","update","config"]给定接口
youzan.retail.trademanager.get.selffetchpointconfig.1.0.0这个接口可能会同时命中了 get 和 config两个关键字,get 是查询行为,能够在给定的查询操作的字典中找到全匹配的值,记2分;selffetchpointconfig 不在字典中,但能部分匹配到 config 这个关键字,config 存在于写操作的字典中,记1分,最后经过计算最后将这个接口的类型定义为读请求。4.4.2 读请求水平越权检查
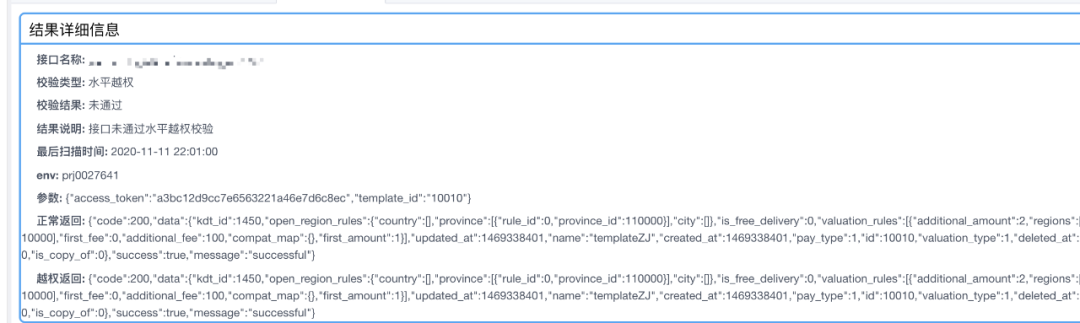
"data":{"total":0,"page_no":1,"page_size":25}"data":[]"data":{"is_bind":false}
4.4.3 写请求水平越权检查
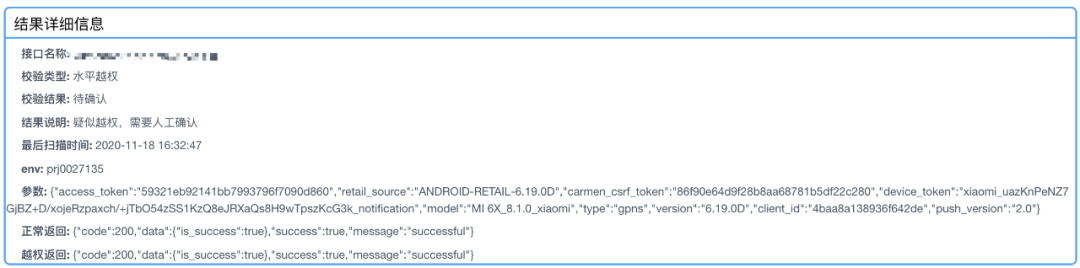
4.4.4 后置检查
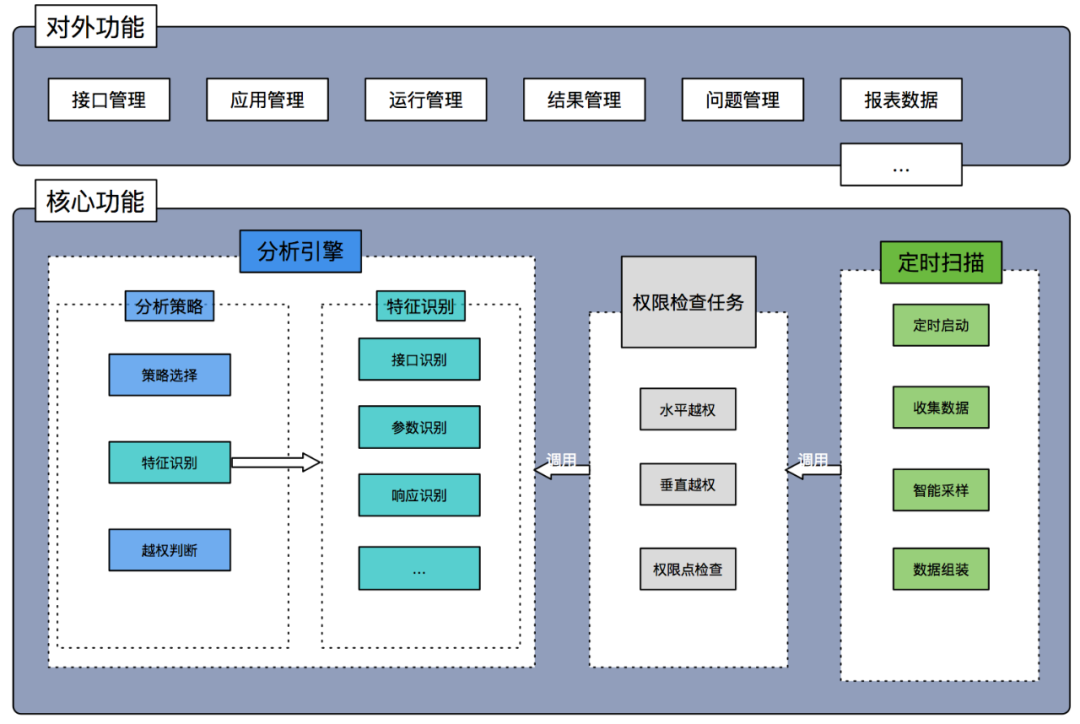
五、整体平台设计
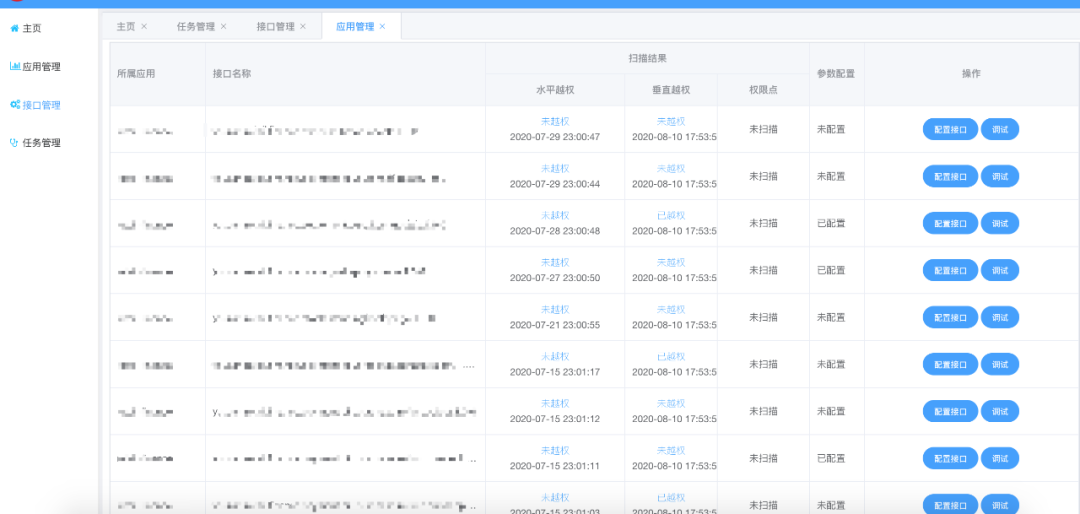
六、实践和落地
有了接口越权扫描平台后,安全问题发现到解决的流程为:
平台每天汇总扫描发现的问题,转给对应业务的测试判断是否是问题;
如果是问题转给对应开发进行修复;
后续问题修复完成关闭问题,入库归档,沉淀为数据;
项目上线前,测试同学查看本次涉及到的接口的扫描情况来评估是否有安全问题,做补充测试或者修复后的回归。
通过接口越权平台的扫描以及研发和安全部门同学的支持,这套机制运转良好,1个月时间,能先于测试同学手工测试发现安全问题20+。逐步形成了适合有赞业务体系的越权防控系统,进一步减少测试人员的投入,也强化了安全质量规范的落地。同时,培养了研发同学的安全意识,在代码编写和用例设计阶段就充分考虑安全性,产生了很大的价值。
七、后续展望
目前接口越权扫描还是单点运行,后续考虑接入持续集成和安全防护体系中,能够发挥更大的作用。 每种业务的越权对象和越权定义都不一样,目前做的判断还是比较粗糙的,需要能够抽象出合理和通用的算法和规则,满足各种业务场景,比如按对象x操作的维度进行处理、规则可配置可插拔等。 通过规则的配置总体上还是不够智能,后续和安全以及其他部门同学合作,考虑采用新思路或者机器学习、人工智能等技术来提高识别率和准确性。
评论