
蚂蚁金服-支付风险识别亚军方案!
比赛背景

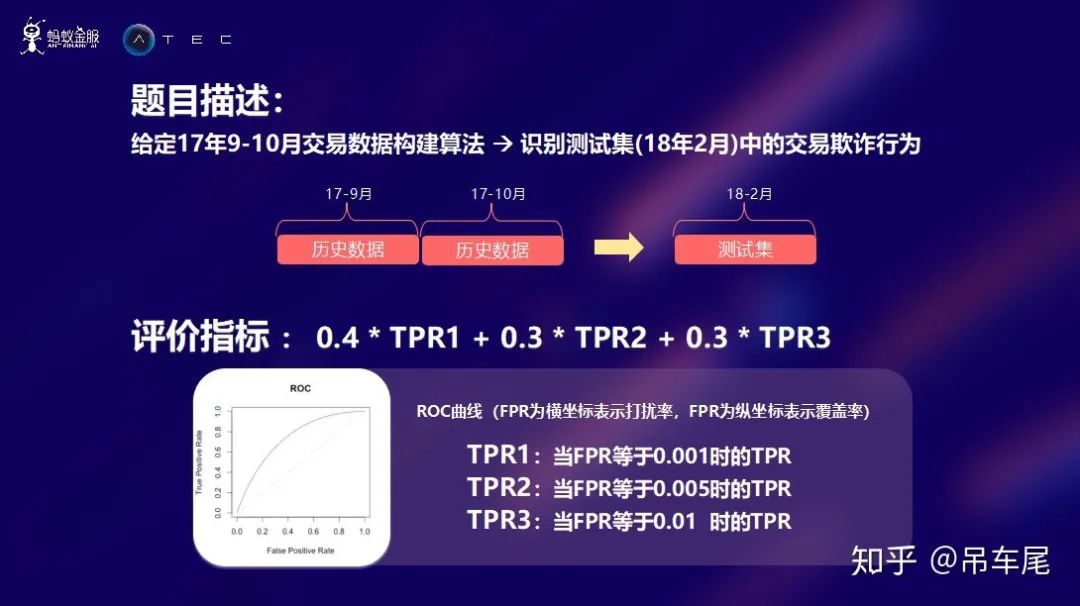
赛题目的
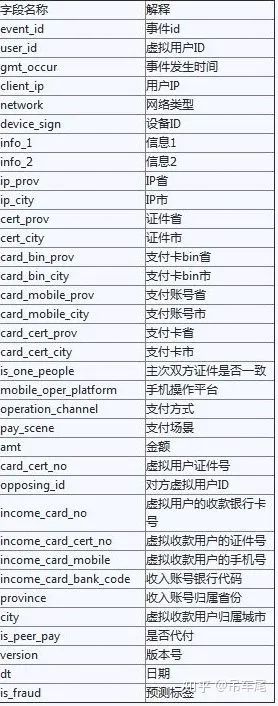
赛题数据
亚军方案
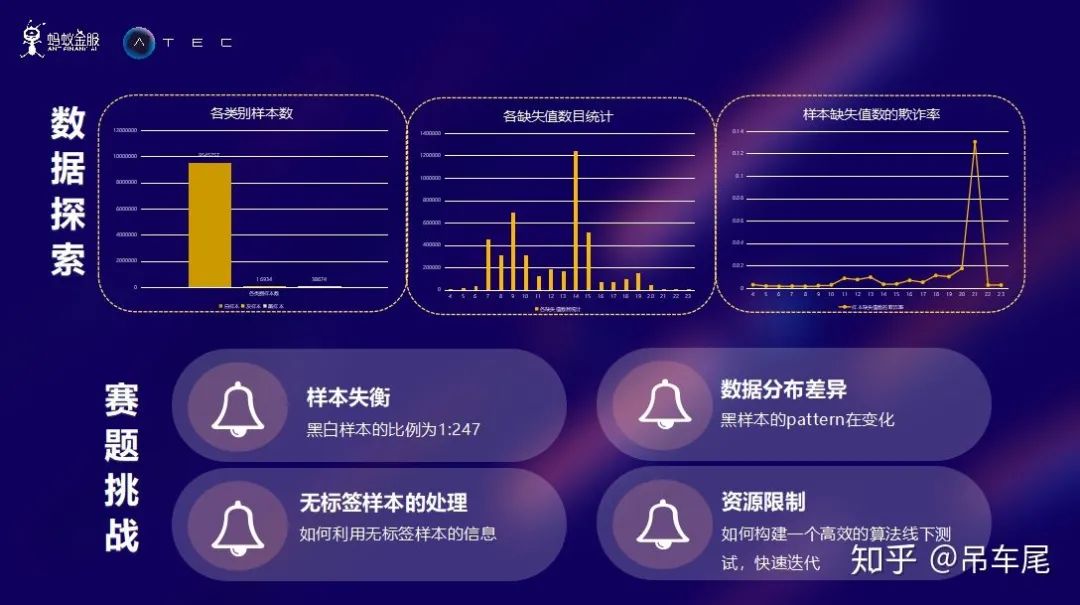
赛题背景
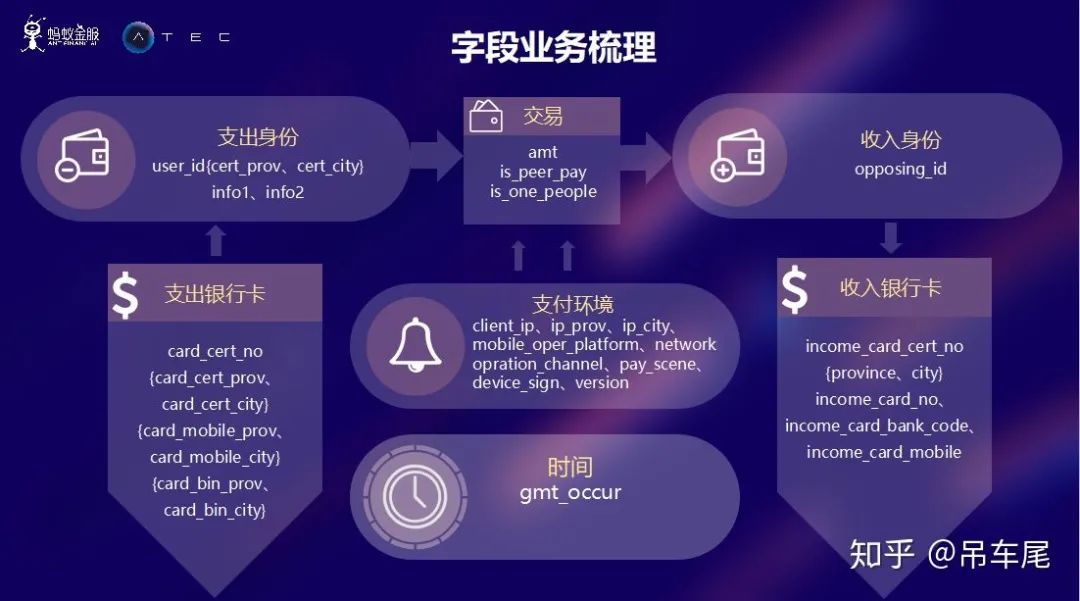
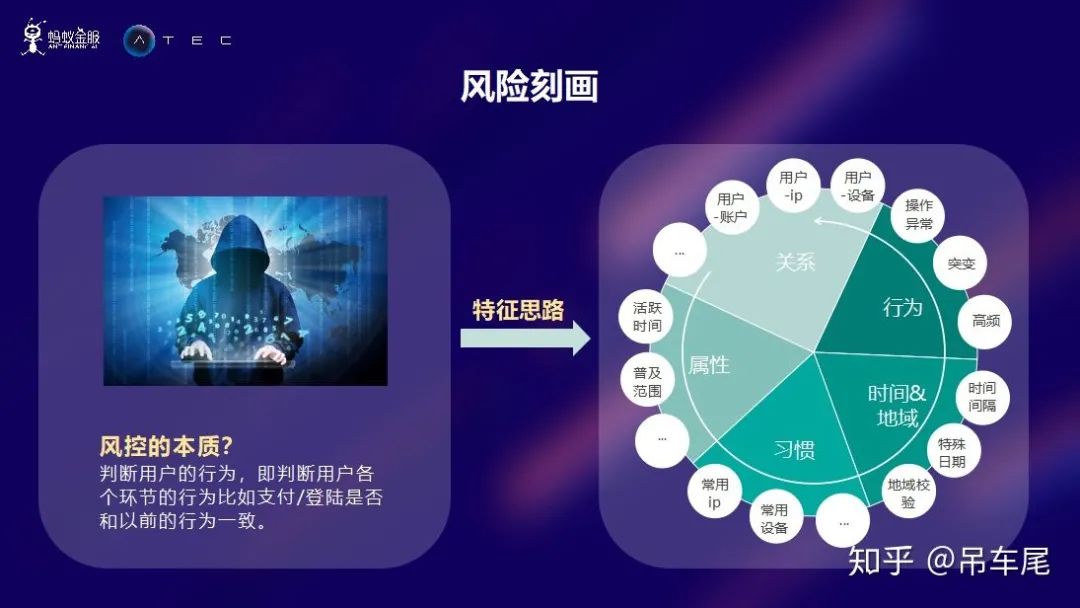
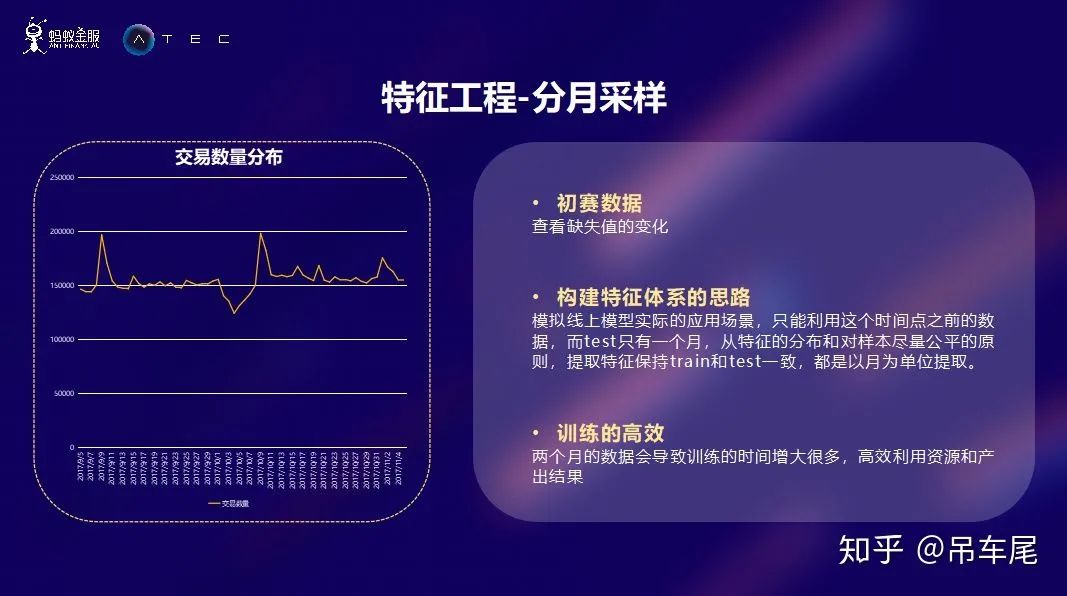
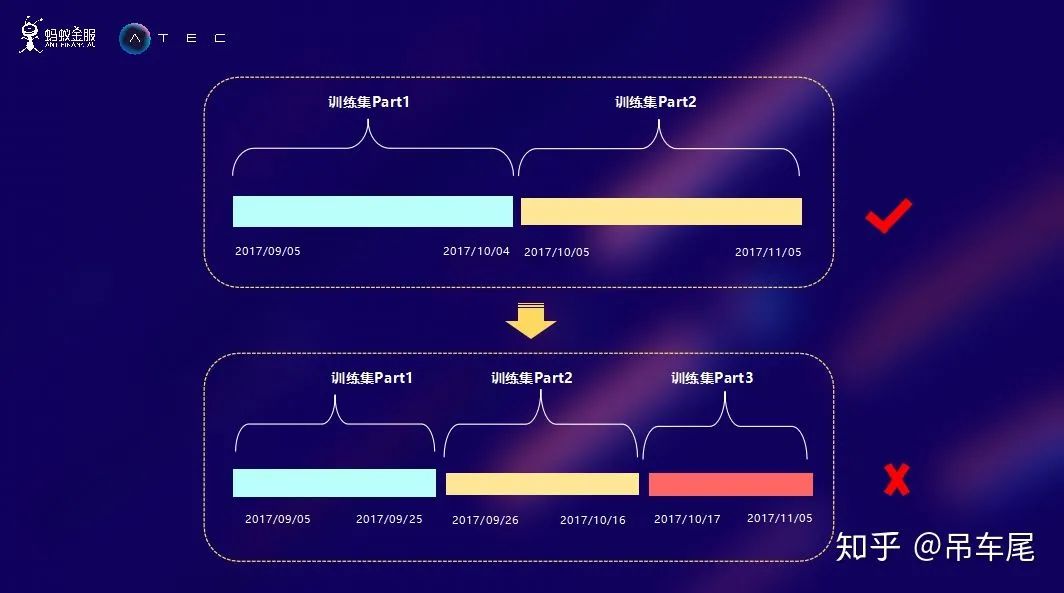
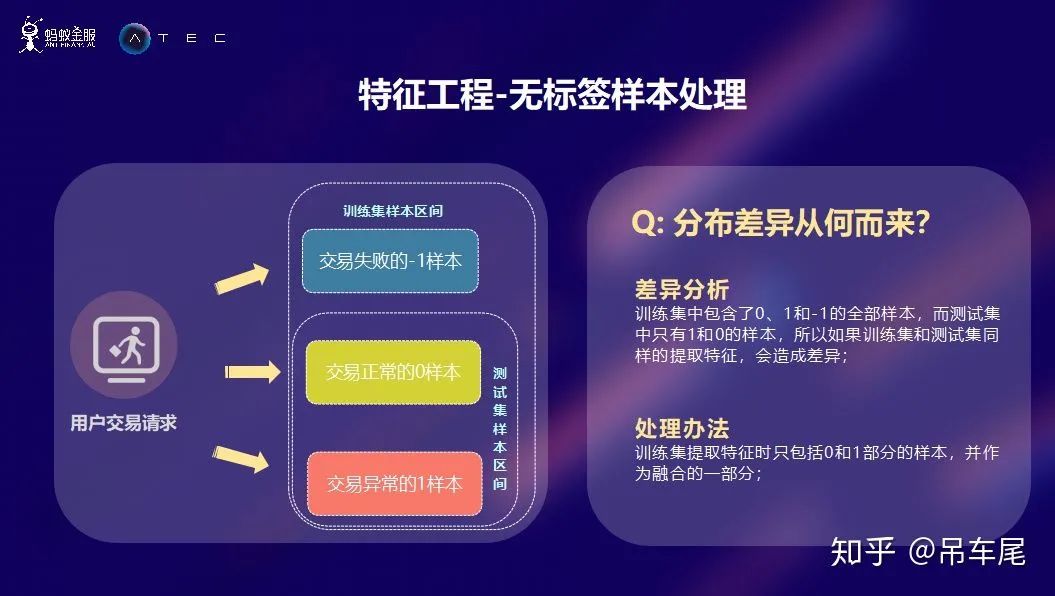
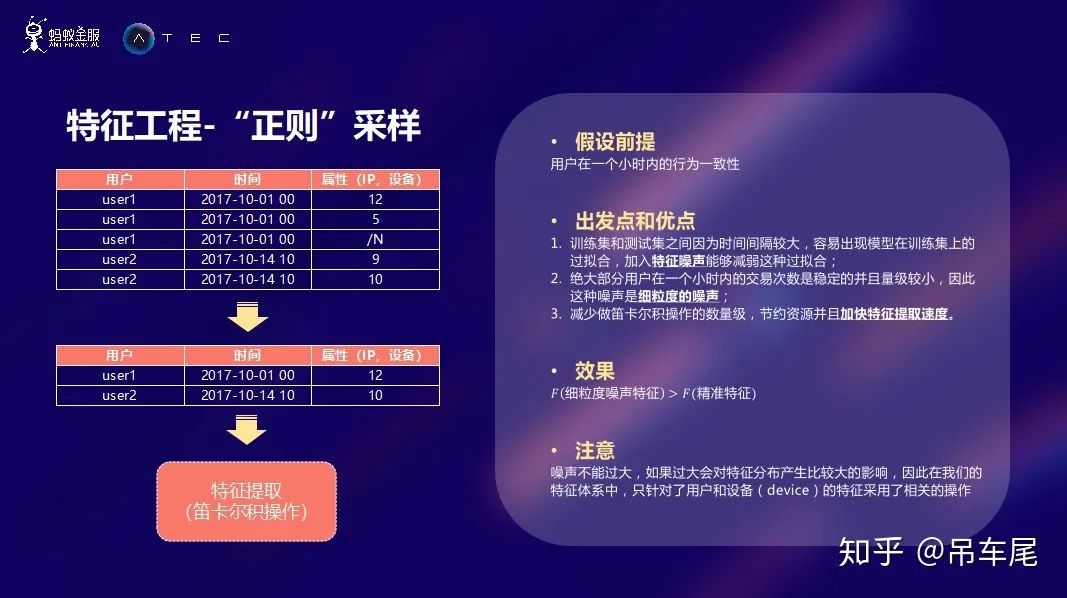
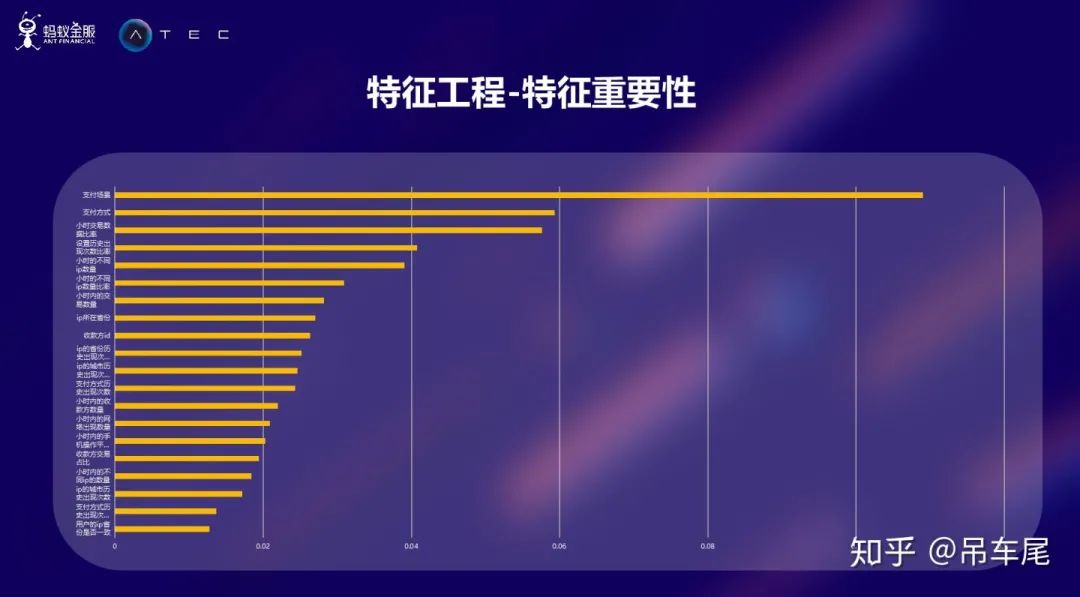
特征工程


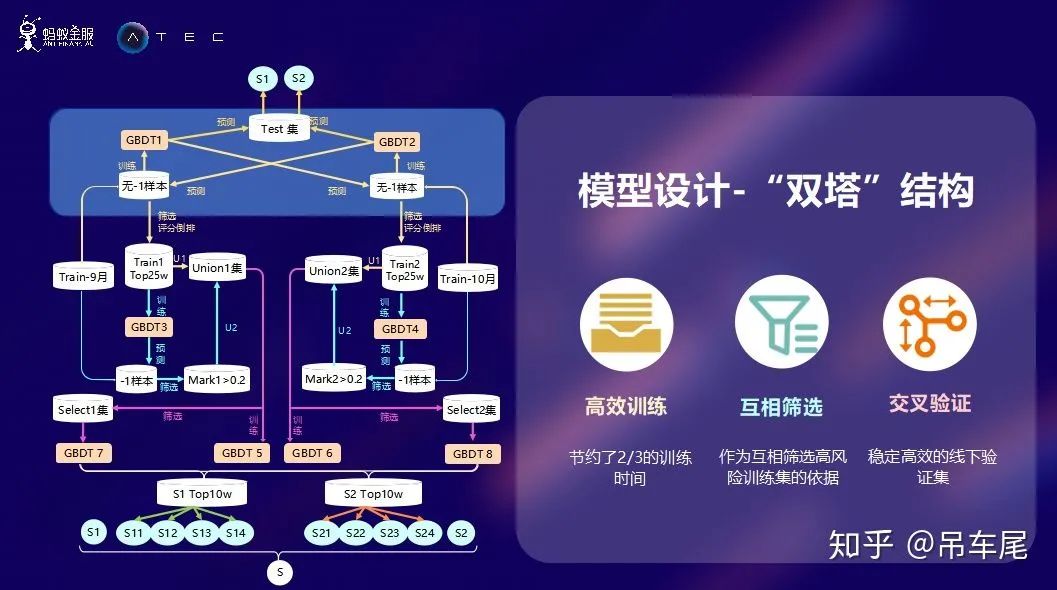
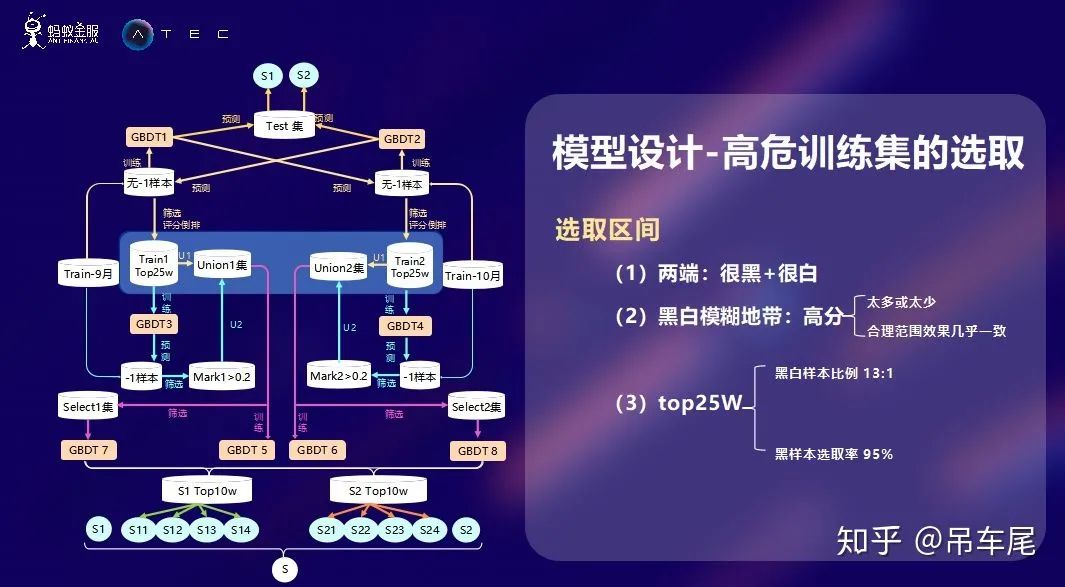
模型设计
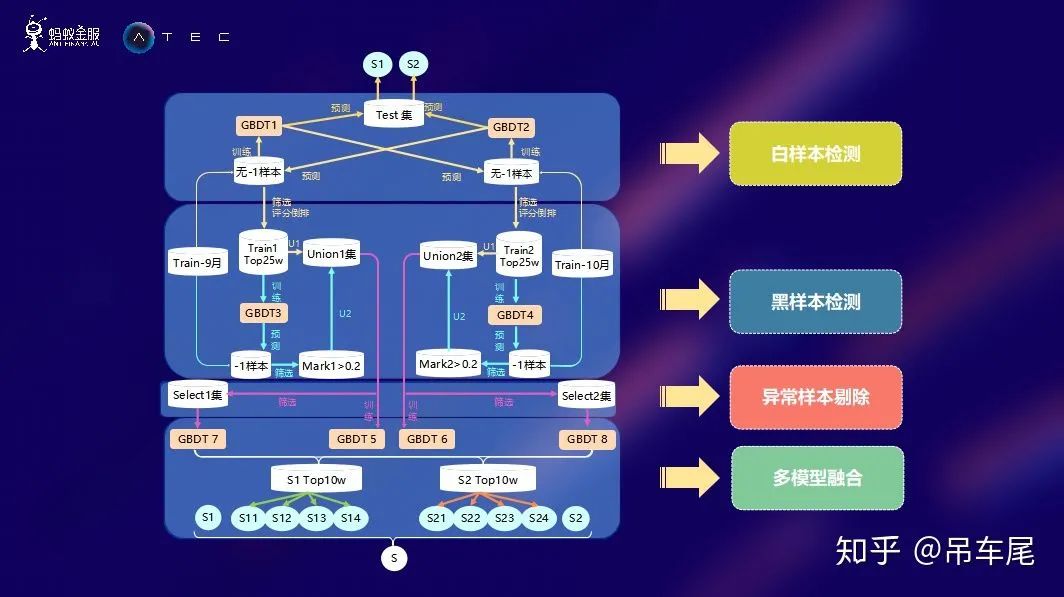
首先是最好的白样本的剔除,我们用9月标签为0和1的样本预测10月标签为0,1的样本,去除其中概率最小的一部分(最优阈值需要不断尝试),同理去除9月的一部分白样本。
然后训练去除最好白样本的这批样本,预测off_val的-1,然后将概率最大的一部分加入到样本中给定标签为1。
比赛开源
竞赛组队交流群
鱼佬,武汉大学硕士,2020腾讯广告算法大赛冠军
阿水,北航计算机硕士,CV领域Top选手
杰少:南京大学硕士,DCIC冠军选手
评论