
MySQL 索引优化的 10 个策略
1
索引策略是指创建使用索引所要遵循的规则,换句话说,违背了这些规则会导致索引失效或者查询效率降低。
策略1:尽量考虑覆盖索引
策略2:遵循最左前缀匹配
策略3:范围查询字段放最后
策略4:不对索引字段进行逻辑操作
策略5:尽量全值匹配
策略6:Like查询,左侧尽量不要加%
策略7:注意null/not null 可能对索引有影响
策略8:尽量减少使用不等于
策略9:字符类型务必加上引号
策略10:OR关键字左右尽量都为索引列
2
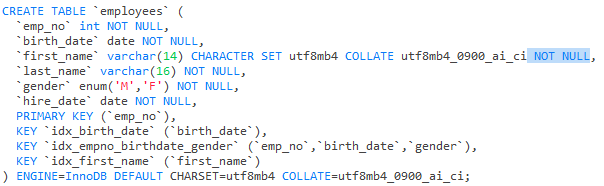
测试数据表:
show index from employees;
策略1:尽量考虑覆盖索引
覆盖索引:SQL只需要通过遍历索引树就可以返回所需要查询的数据,而不必通过辅助索引查到主键值之后再去查询数据(回表操作)。回表操作的详细介绍可以参考本人《MySQL慢查询优化》系列博文之索引。
EG:
EXPLAIN SELECT emp_no,birth_date,gender FROM employees WHERE gender ='M' ;
Using index:表示已经使用了覆盖索引。
策略2:遵循最左前缀匹配
联合索引命中必须遵循“最左前缀法则”。即SQL查询Where条件字段必须从索引的最左前列开始匹配,不能跳过索引中的列。联合索引又称复合索引,类似于书籍的目录,多级的目录结构中子目录依赖于父级目录存在,也是遵循“最左前缀法则”。
联合索引结构分析,示例:

EXPLAIN SELECT * FROM employees WHERE birth_date = '1963-06-01' AND gender ='F';
注:表存在多个索引时,即使Where条件满足最左前缀规则,SQL执行时也未必一定会命中联合索引,根据性能可能直接使用了主键索引。
EG:
EXPLAIN SELECT * FROM employees WHERE emp_no = 10010 AND birth_date = '1963-06-01' AND gender ='F';
PRIMARY KEY (`emp_no`)
策略3:范围查询字段放最后
联合索引定义时,尽量将范围查询字段放在最后(放在最后联合索引使用最充分,放在中间联合索引使用不充分)。使用联合索引时范围列(当前范围列索引生效)后面的索引列无法生效,同时索引最多用于一个范围列,如果查询条件中有多个范围列,也只能用到一个范围列索引。
EG1:
EXPLAIN SELECT emp_no,birth_date,gender FROM employees WHERE emp_no > 10015 AND gender ='F';
只是使用到了主键索引PRIMARY(emp_no),联合索引未生效idx_empno_birthdate_gender(emp_no,birth_date,gender);
删除idx_empno_birthdate_gender索引,新建联合索引idx_gender_birthdate_empno(gender,birth_date,emp_no);

EG2:
EXPLAIN SELECT emp_no,birth_date,gender FROM employees WHERE emp_no > 10015 AND birth_date = 1953-09-02 AND gender ='F';
策略4:不对索引字段进行逻辑操作
在索引字段上进行计算、函数、类型转换(自动\手动)都会导致索引失效。
EG:
CREATE INDEX idx_first_name ON employees(first_name);
EXPLAIN SELECT * FROM employees WHERE LEFT(first_name,3) ='Geo';
策略5:尽量全值匹配
全值匹配也就是精确匹配不使用like查询(模糊匹配),使用like会使查询效率降低。
策略6:Like查询,左侧尽量不要加%
like 以%开头,当前列索引无效(当为联合索引时,当前列和后续列索引不生效,可能导致索引使用不充分);当like前缀没有%,后缀有%时,索引有效。
EG1:
EXPLAIN SELECT * FROM employees WHERE first_name like'Geo%';
EG2:
EXPLAIN SELECT * FROM employees WHERE first_name like'%Geo%';

策略7:注意NULL/NOT NULL可能对索引有影响
在索引列上使用 IS NULL 或 IS NOT NULL条件,可能对索引有所影响。
字段定义默认为NULL时,NULL索引生效,NOT NULL索引不生效;
字段定义明确为NOT NULL ,不允许为空时,NULL/NOT NULL索引列,索引均失效;
列字段尽量设置为NOT NULL,MySQL难以对使用NULL的列进行查询优化,允许Null会使索引值以及索引统计更加复杂。允许NULL值的列需要更多的存储空间,还需要MySQL内部进行特殊处理。

EG1:
EXPLAIN SELECT * FROM employees WHERE first_name IS NULL;
EG2:
EXPLAIN SELECT * FROM employees WHERE first_name IS NOT NULL;
EG3:
EXPLAIN SELECT * FROM employees WHERE first_name IS NOT NULL;
策略8:尽量减少使用不等于
不等于操作符是不会使用索引的。不等于操作符包括:not,<>,!=。
优化方法:数值型 key<>0 改为 key>0 or key<0。
EG:
EXPLAIN SELECT * FROM employees WHERE first_name != 'Georgi';
策略9:字符类型务必加上引号
若varchar类型字段值不加单引号,可能会发生数据类型隐式转化,自动转换为int型,使索引无效。
EG:
EXPLAIN SELECT * FROM employees WHERE first_name = 1;
策略10:OR关键字前后尽量都为索引列
当OR左右查询字段只有一个是索引,会使该索引失效,只有当OR左右查询字段均为索引列时,这些索引才会生效。OR改UNION效率高。
EG1:
EXPLAIN SELECT * FROM employees WHERE first_name = 'Georgi' OR emp_no = 20001;
EG2:
EXPLAIN SELECT * FROM employees WHERE first_name = 'Georgi' OR last_name = 'Facello';
3
索引的创建需要参照具体的SQL实现。
当全表扫描速度比索引速度快时,MySQL会使用全表扫描,此时索引失效。
表中存在多个索引时,即使where条件满足某个索引策略,MySQL查询优化器也不一定会使用该索引,可能使用其他索引,取决于性能。另外,当某个索引没有命中也不一定会走全表扫描,可能走其他索引。
理论上索引对顺序是敏感的,也就是说where子句的字段列表需要讲究顺序,但是由于MySQL的查询优化器会自动调整where子句的条件顺序以匹配适合的索引,因此,允许我们不去刻意关注where子句的条件顺序
来源:cnblogs.com/gavincoder/p/14056731.html
往期推荐